 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning domain-invariant features through channel-level sparsification for Out-Of Distribution Generalization
Mar 26, 2026Out-of-Distribution (OOD) generalization has become a primary metric for evaluating image analysis systems. Since deep learning models tend to capture domain-specific context, they often develop shortcut dependencies on these non-causal features, leading to inconsistent performance across different data sources. Current techniques, such as invariance learning, attempt to mitigate this. However, they struggle to isolate highly mixed features within deep latent spaces. This limitation prevents them from fully resolving the shortcut learning problem.In this paper, we propose Hierarchical Causal Dropout (HCD), a method that uses channel-level causal masks to enforce feature sparsity. This approach allows the model to separate causal features from spurious ones, effectively performing a causal intervention at the representation level. The training is guided by a Matrix-based Mutual Information (MMI) objective to minimize the mutual information between latent features and domain labels, while simultaneously maximizing the information shared with class labels.To ensure stability, we incorporate a StyleMix-driven VICReg module, which prevents the masks from accidentally filtering out essential causal data. Experimental results on OOD benchmarks show that HCD performs better than existing top-tier methods.
Kirchhoff-Inspired Neural Networks for Evolving High-Order Perception
Mar 25, 2026Deep learning architectures are fundamentally inspired by neuroscience, particularly the structure of the brain's sensory pathways, and have achieved remarkable success in learning informative data representations. Although these architectures mimic the communication mechanisms of biological neurons, their strategies for information encoding and transmission are fundamentally distinct. Biological systems depend on dynamic fluctuations in membrane potential; by contrast, conventional deep networks optimize weights and biases by adjusting the strengths of inter-neural connections, lacking a systematic mechanism to jointly characterize the interplay among signal intensity, coupling structure, and state evolution. To tackle this limitation, we propose the Kirchhoff-Inspired Neural Network (KINN), a state-variable-based network architecture constructed based on Kirchhoff's current law. KINN derives numerically stable state updates from fundamental ordinary differential equations, enabling the explicit decoupling and encoding of higher-order evolutionary components within a single layer while preserving physical consistency, interpretability, and end-to-end trainability. Extensive experiments on partial differential equation (PDE) solving and ImageNet image classification validate that KINN outperforms state-of-the-art existing methods.
Weak-PDE-Net: Discovering Open-Form PDEs via Differentiable Symbolic Networks and Weak Formulation
Mar 24, 2026Discovering governing Partial Differential Equations (PDEs) from sparse and noisy data is a challenging issue in data-driven scientific computing. Conventional sparse regression methods often suffer from two major limitations: (i) the instability of numerical differentiation under sparse and noisy data, and (ii) the restricted flexibility of a pre-defined candidate library. We propose Weak-PDE-Net, an end-to-end differentiable framework that can robustly identify open-form PDEs. Weak-PDE-Net consists of two interconnected modules: a forward response learner and a weak-form PDE generator. The learner embeds learnable Gaussian kernels within a lightweight MLP, serving as a surrogate model that adaptively captures system dynamics from sparse observations. Meanwhile, the generator integrates a symbolic network with an integral module to construct weak-form PDEs, avoiding explicit numerical differentiation and improving robustness to noise. To relax the constraints of the pre-defined library, we leverage Differentiable Neural Architecture Search strategy during training to explore the functional space, which enables the efficient discovery of open-form PDEs. The capability of Weak-PDE-Net in multivariable systems discovery is further enhanced by incorporating Galilean Invariance constraints and symmetry equivariance hypotheses to ensure physical consistency. Experiments on several challenging PDE benchmarks demonstrate that Weak-PDE-Net accurately recovers governing equations, even under highly sparse and noisy observations.
Differentiable Adaptive Kalman Filtering via Optimal Transport
Aug 09, 2025Learning-based filtering has demonstrated strong performance in non-linear dynamical systems, particularly when the statistics of noise are unknown. However, in real-world deployments, environmental factors, such as changing wind conditions or electromagnetic interference, can induce unobserved noise-statistics drift, leading to substantial degradation of learning-based methods. To address this challenge, we propose OTAKNet, the first online solution to noise-statistics drift within learning-based adaptive Kalman filtering. Unlike existing learning-based methods that perform offline fine-tuning using batch pointwise matching over entire trajectories, OTAKNet establishes a connection between the state estimate and the drift via one-step predictive measurement likelihood, and addresses it using optimal transport. This leverages OT's geometry - aware cost and stable gradients to enable fully online adaptation without ground truth labels or retraining. We compare OTAKNet against classical model-based adaptive Kalman filtering and offline learning-based filtering. The performance is demonstrated on both synthetic and real-world NCLT datasets, particularly under limited training data.
Squeeze10-LLM: Squeezing LLMs' Weights by 10 Times via a Staged Mixed-Precision Quantization Method
Jul 24, 2025Deploying large language models (LLMs) is challenging due to their massive parameters and high computational costs. Ultra low-bit quantization can significantly reduce storage and accelerate inference, but extreme compression (i.e., mean bit-width <= 2) often leads to severe performance degradation. To address this, we propose Squeeze10-LLM, effectively "squeezing" 16-bit LLMs' weights by 10 times. Specifically, Squeeze10-LLM is a staged mixed-precision post-training quantization (PTQ) framework and achieves an average of 1.6 bits per weight by quantizing 80% of the weights to 1 bit and 20% to 4 bits. We introduce Squeeze10LLM with two key innovations: Post-Binarization Activation Robustness (PBAR) and Full Information Activation Supervision (FIAS). PBAR is a refined weight significance metric that accounts for the impact of quantization on activations, improving accuracy in low-bit settings. FIAS is a strategy that preserves full activation information during quantization to mitigate cumulative error propagation across layers. Experiments on LLaMA and LLaMA2 show that Squeeze10-LLM achieves state-of-the-art performance for sub-2bit weight-only quantization, improving average accuracy from 43% to 56% on six zero-shot classification tasks--a significant boost over existing PTQ methods. Our code will be released upon publication.
HRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Jun 17, 2025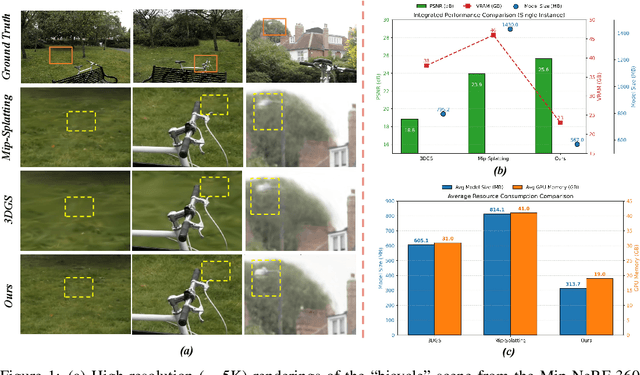

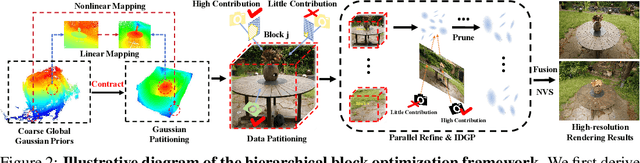

3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
UniSymNet: A Unified Symbolic Network Guided by Transformer
May 09, 2025
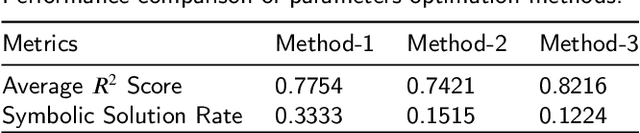
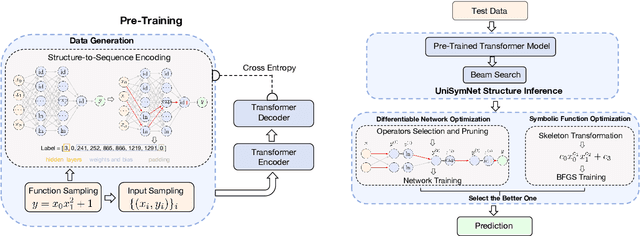
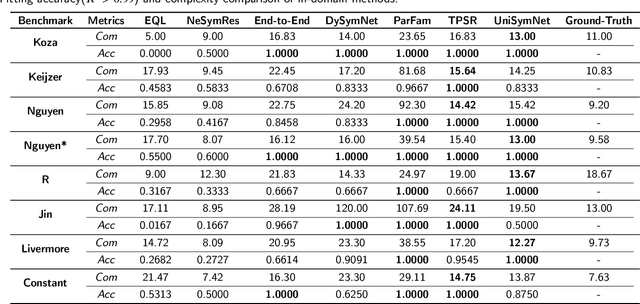
Symbolic Regression (SR) is a powerful technique for automatically discovering mathematical expressions from input data. Mainstream SR algorithms search for the optimal symbolic tree in a vast function space, but the increasing complexity of the tree structure limits their performance. Inspired by neural networks, symbolic networks have emerged as a promising new paradigm. However, most existing symbolic networks still face certain challenges: binary nonlinear operators $\{\times, \div\}$ cannot be naturally extended to multivariate operators, and training with fixed architecture often leads to higher complexity and overfitting. In this work, we propose a Unified Symbolic Network that unifies nonlinear binary operators into nested unary operators and define the conditions under which UniSymNet can reduce complexity. Moreover, we pre-train a Transformer model with a novel label encoding method to guide structural selection, and adopt objective-specific optimization strategies to learn the parameters of the symbolic network. UniSymNet shows high fitting accuracy, excellent symbolic solution rate, and relatively low expression complexity, achieving competitive performance on low-dimensional Standard Benchmarks and high-dimensional SRBench.
Multimodal-Aware Fusion Network for Referring Remote Sensing Image Segmentation
Mar 14, 2025



Referring remote sensing image segmentation (RRSIS) is a novel visual task in remote sensing images segmentation, which aims to segment objects based on a given text description, with great significance in practical application. Previous studies fuse visual and linguistic modalities by explicit feature interaction, which fail to effectively excavate useful multimodal information from dual-branch encoder. In this letter, we design a multimodal-aware fusion network (MAFN) to achieve fine-grained alignment and fusion between the two modalities. We propose a correlation fusion module (CFM) to enhance multi-scale visual features by introducing adaptively noise in transformer, and integrate cross-modal aware features. In addition, MAFN employs multi-scale refinement convolution (MSRC) to adapt to the various orientations of objects at different scales to boost their representation ability to enhances segmentation accuracy. Extensive experiments have shown that MAFN is significantly more effective than the state of the art on RRSIS-D datasets. The source code is available at https://github.com/Roaxy/MAFN.
TrackDiffuser: Nearly Model-Free Bayesian Filtering with Diffusion Model
Feb 08, 2025



State estimation remains a fundamental challenge across numerous domains, from autonomous driving, aircraft tracking to quantum system control. Although Bayesian filtering has been the cornerstone solution, its classical model-based paradigm faces two major limitations: it struggles with inaccurate state space model (SSM) and requires extensive prior knowledge of noise characteristics. We present TrackDiffuser, a generative framework addressing both challenges by reformulating Bayesian filtering as a conditional diffusion model. Our approach implicitly learns system dynamics from data to mitigate the effects of inaccurate SSM, while simultaneously circumventing the need for explicit measurement models and noise priors by establishing a direct relationship between measurements and states. Through an implicit predict-and-update mechanism, TrackDiffuser preserves the interpretability advantage of traditional model-based filtering methods. Extensive experiments demonstrate that our framework substantially outperforms both classical and contemporary hybrid methods, especially in challenging non-linear scenarios involving non-Gaussian noises. Notably, TrackDiffuser exhibits remarkable robustness to SSM inaccuracies, offering a practical solution for real-world state estimation problems where perfect models and prior knowledge are unavailable.
ViSymRe: Vision-guided Multimodal Symbolic Regression
Dec 15, 2024Symbolic regression automatically searches for mathematical equations to reveal underlying mechanisms within datasets, offering enhanced interpretability compared to black box models. Traditionally, symbolic regression has been considered to be purely numeric-driven, with insufficient attention given to the potential contributions of visual information in augmenting this process. When dealing with high-dimensional and complex datasets, existing symbolic regression models are often inefficient and tend to generate overly complex equations, making subsequent mechanism analysis complicated. In this paper, we propose the vision-guided multimodal symbolic regression model, called ViSymRe, that systematically explores how visual information can improve various metrics of symbolic regression. Compared to traditional models, our proposed model has the following innovations: (1) It integrates three modalities: vision, symbol and numeric to enhance symbolic regression, enabling the model to benefit from the strengths of each modality; (2) It establishes a meta-learning framework that can learn from historical experiences to efficiently solve new symbolic regression problems; (3) It emphasizes the simplicity and structural rationality of the equations rather than merely numerical fitting. Extensive experiments show that our proposed model exhibits strong generalization capability and noise resistance. The equations it generates outperform state-of-the-art numeric-only baselines in terms of fitting effect, simplicity and structural accuracy, thus being able to facilitate accurate mechanism analysis and the development of theoretical models.