 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRAL: A Closed-Loop Framework for Self-Improving Action World Models via Reflective Planning Agents
Mar 11, 2026We introduce SPIRAL, a self-improving planning and iterative reflective action world modeling closed-loop framework that enables controllable long-horizon video generation conditioned on high-level semantic actions. Existing one-shot video generation models operate in open-loop, often resulting in incomplete action execution, weak semantic grounding, and temporal drift. SPIRAL formulates ActWM as a closed-loop think-act-reflect process, where generation proceeds step by step under explicit planning and feedback. A PlanAgent decomposes abstract actions into object-centric sub-actions, while a CriticAgent evaluates intermediate results and guides iterative refinement with long-horizon memory. This closed-loop design naturally supports RL evolving optimization, improving semantic alignment and temporal consistency over extended horizons. We further introduce the ActWM-Dataset and ActWM-Bench for training and evaluation. Experiments across multiple TI2V backbones demonstrate consistent gains on ActWM-Bench and mainstream video generation benchmarks, validating SPIRAL's effectiveness.
UrbanGS: A Scalable and Efficient Architecture for Geometrically Accurate Large-Scene Reconstruction
Feb 02, 2026While 3D Gaussian Splatting (3DGS) enables high-quality, real-time rendering for bounded scenes, its extension to large-scale urban environments gives rise to critical challenges in terms of geometric consistency, memory efficiency, and computational scalability. To address these issues, we present UrbanGS, a scalable reconstruction framework that effectively tackles these challenges for city-scale applications. First, we propose a Depth-Consistent D-Normal Regularization module. Unlike existing approaches that rely solely on monocular normal estimators, which can effectively update rotation parameters yet struggle to update position parameters, our method integrates D-Normal constraints with external depth supervision. This allows for comprehensive updates of all geometric parameters. By further incorporating an adaptive confidence weighting mechanism based on gradient consistency and inverse depth deviation, our approach significantly enhances multi-view depth alignment and geometric coherence, which effectively resolves the issue of geometric accuracy in complex large-scale scenes. To improve scalability, we introduce a Spatially Adaptive Gaussian Pruning (SAGP) strategy, which dynamically adjusts Gaussian density based on local geometric complexity and visibility to reduce redundancy. Additionally, a unified partitioning and view assignment scheme is designed to eliminate boundary artifacts and optimize computational load. Extensive experiments on multiple urban datasets demonstrate that UrbanGS achieves superior performance in rendering quality, geometric accuracy, and memory efficiency, providing a systematic solution for high-fidelity large-scale scene reconstruction.
Surf3R: Rapid Surface Reconstruction from Sparse RGB Views in Seconds
Aug 06, 2025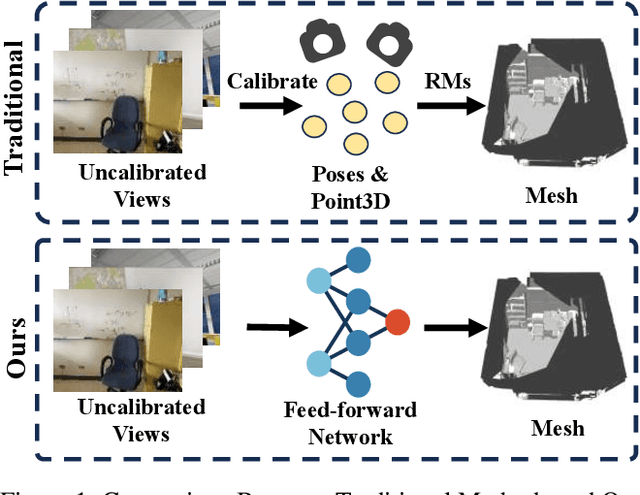
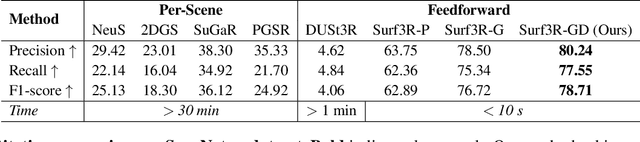
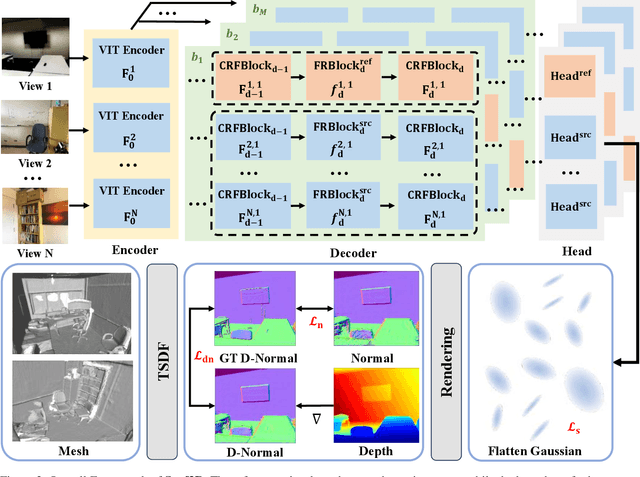

Current multi-view 3D reconstruction methods rely on accurate camera calibration and pose estimation, requiring complex and time-intensive pre-processing that hinders their practical deployment. To address this challenge, we introduce Surf3R, an end-to-end feedforward approach that reconstructs 3D surfaces from sparse views without estimating camera poses and completes an entire scene in under 10 seconds. Our method employs a multi-branch and multi-view decoding architecture in which multiple reference views jointly guide the reconstruction process. Through the proposed branch-wise processing, cross-view attention, and inter-branch fusion, the model effectively captures complementary geometric cues without requiring camera calibration. Moreover, we introduce a D-Normal regularizer based on an explicit 3D Gaussian representation for surface reconstruction. It couples surface normals with other geometric parameters to jointly optimize the 3D geometry, significantly improving 3D consistency and surface detail accuracy. Experimental results demonstrate that Surf3R achieves state-of-the-art performance on multiple surface reconstruction metrics on ScanNet++ and Replica datasets, exhibiting excellent generalization and efficiency.
HRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Jun 17, 2025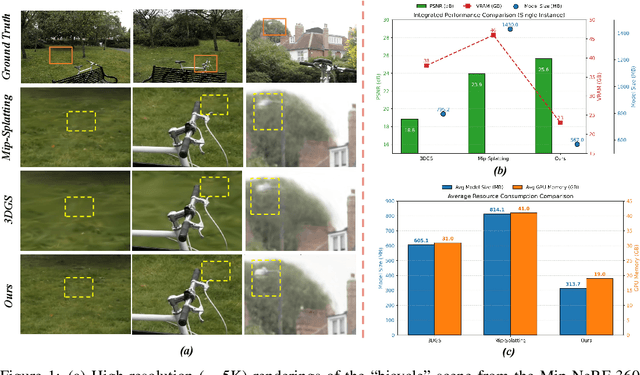

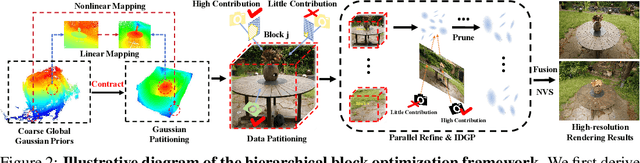

3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
Impact Analysis of Inference Time Attack of Perception Sensors on Autonomous Vehicles
May 05, 2025As a safety-critical cyber-physical system, cybersecurity and related safety issues for Autonomous Vehicles (AVs) have been important research topics for a while. Among all the modules on AVs, perception is one of the most accessible attack surfaces, as drivers and AVs have no control over the outside environment. Most current work targeting perception security for AVs focuses on perception correctness. In this work, we propose an impact analysis based on inference time attacks for autonomous vehicles. We demonstrate in a simulation system that such inference time attacks can also threaten the safety of both the ego vehicle and other traffic participants.
ChatSplat: 3D Conversational Gaussian Splatting
Dec 01, 2024
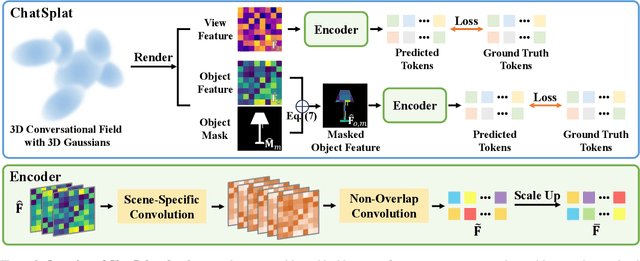

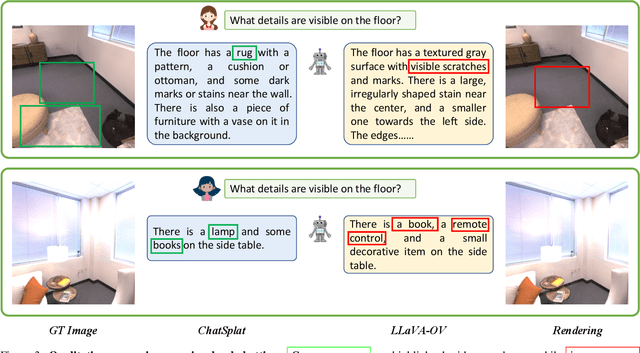
Humans naturally interact with their 3D surroundings using language, and modeling 3D language fields for scene understanding and interaction has gained growing interest. This paper introduces ChatSplat, a system that constructs a 3D language field, enabling rich chat-based interaction within 3D space. Unlike existing methods that primarily use CLIP-derived language features focused solely on segmentation, ChatSplat facilitates interaction on three levels: objects, views, and the entire 3D scene. For view-level interaction, we designed an encoder that encodes the rendered feature map of each view into tokens, which are then processed by a large language model (LLM) for conversation. At the scene level, ChatSplat combines multi-view tokens, enabling interactions that consider the entire scene. For object-level interaction, ChatSplat uses a patch-wise language embedding, unlike LangSplat's pixel-wise language embedding that implicitly includes mask and embedding. Here, we explicitly decouple the language embedding into separate mask and feature map representations, allowing more flexible object-level interaction. To address the challenge of learning 3D Gaussians posed by the complex and diverse distribution of language embeddings used in the LLM, we introduce a learnable normalization technique to standardize these embeddings, facilitating effective learning. Extensive experimental results demonstrate that ChatSplat supports multi-level interactions -- object, view, and scene -- within 3D space, enhancing both understanding and engagement.
Generalizable Human Gaussians from Single-View Image
Jun 10, 2024In this work, we tackle the task of learning generalizable 3D human Gaussians from a single image. The main challenge for this task is to recover detailed geometry and appearance, especially for the unobserved regions. To this end, we propose single-view generalizable Human Gaussian model (HGM), a diffusion-guided framework for 3D human modeling from a single image. We design a diffusion-based coarse-to-fine pipeline, where the diffusion model is adapted to refine novel-view images rendered from a coarse human Gaussian model. The refined images are then used together with the input image to learn a refined human Gaussian model. Although effective in hallucinating the unobserved views, the approach may generate unrealistic human pose and shapes due to the lack of supervision. We circumvent this problem by further encoding the geometric priors from SMPL model. Specifically, we propagate geometric features from SMPL volume to the predicted Gaussians via sparse convolution and attention mechanism. We validate our approach on publicly available datasets and demonstrate that it significantly surpasses state-of-the-art methods in terms of PSNR and SSIM. Additionally, our method exhibits strong generalization for in-the-wild images.
VCR-GauS: View Consistent Depth-Normal Regularizer for Gaussian Surface Reconstruction
Jun 09, 2024
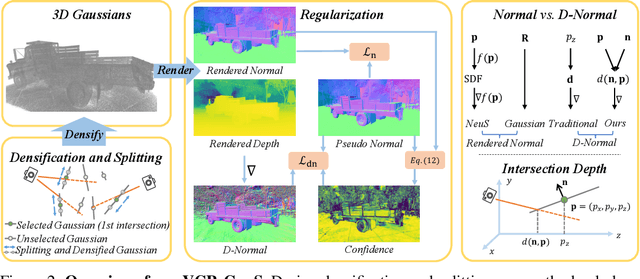


Although 3D Gaussian Splatting has been widely studied because of its realistic and efficient novel-view synthesis, it is still challenging to extract a high-quality surface from the point-based representation. Previous works improve the surface by incorporating geometric priors from the off-the-shelf normal estimator. However, there are two main limitations: 1) Supervising normal rendered from 3D Gaussians updates only the rotation parameter while neglecting other geometric parameters; 2) The inconsistency of predicted normal maps across multiple views may lead to severe reconstruction artifacts. In this paper, we propose a Depth-Normal regularizer that directly couples normal with other geometric parameters, leading to full updates of the geometric parameters from normal regularization. We further propose a confidence term to mitigate inconsistencies of normal predictions across multiple views. Moreover, we also introduce a densification and splitting strategy to regularize the size and distribution of 3D Gaussians for more accurate surface modeling. Compared with Gaussian-based baselines, experiments show that our approach obtains better reconstruction quality and maintains competitive appearance quality at faster training speed and 100+ FPS rendering. Our code will be made open-source upon paper acceptance.
FreeSplat: Generalizable 3D Gaussian Splatting Towards Free-View Synthesis of Indoor Scenes
May 28, 2024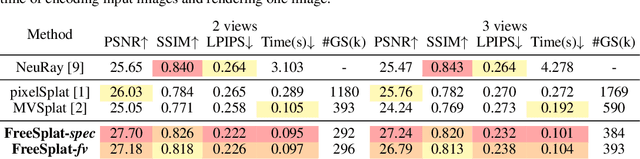
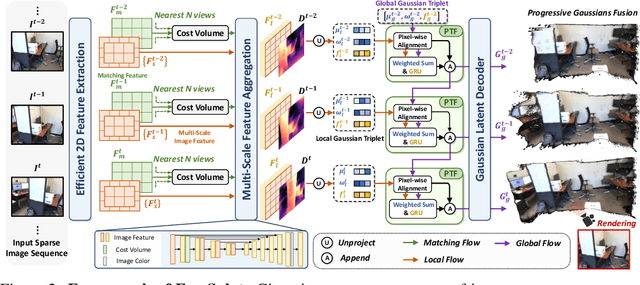

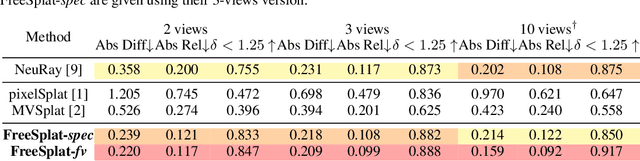
Empowering 3D Gaussian Splatting with generalization ability is appealing. However, existing generalizable 3D Gaussian Splatting methods are largely confined to narrow-range interpolation between stereo images due to their heavy backbones, thus lacking the ability to accurately localize 3D Gaussian and support free-view synthesis across wide view range. In this paper, we present a novel framework FreeSplat that is capable of reconstructing geometrically consistent 3D scenes from long sequence input towards free-view synthesis.Specifically, we firstly introduce Low-cost Cross-View Aggregation achieved by constructing adaptive cost volumes among nearby views and aggregating features using a multi-scale structure. Subsequently, we present the Pixel-wise Triplet Fusion to eliminate redundancy of 3D Gaussians in overlapping view regions and to aggregate features observed across multiple views. Additionally, we propose a simple but effective free-view training strategy that ensures robust view synthesis across broader view range regardless of the number of views. Our empirical results demonstrate state-of-the-art novel view synthesis peformances in both novel view rendered color maps quality and depth maps accuracy across different numbers of input views. We also show that FreeSplat performs inference more efficiently and can effectively reduce redundant Gaussians, offering the possibility of feed-forward large scene reconstruction without depth priors.
An Advanced Framework for Ultra-Realistic Simulation and Digital Twinning for Autonomous Vehicles
May 02, 2024



Simulation is a fundamental tool in developing autonomous vehicles, enabling rigorous testing without the logistical and safety challenges associated with real-world trials. As autonomous vehicle technologies evolve and public safety demands increase, advanced, realistic simulation frameworks are critical. Current testing paradigms employ a mix of general-purpose and specialized simulators, such as CARLA and IVRESS, to achieve high-fidelity results. However, these tools often struggle with compatibility due to differing platform, hardware, and software requirements, severely hampering their combined effectiveness. This paper introduces BlueICE, an advanced framework for ultra-realistic simulation and digital twinning, to address these challenges. BlueICE's innovative architecture allows for the decoupling of computing platforms, hardware, and software dependencies while offering researchers customizable testing environments to meet diverse fidelity needs. Key features include containerization to ensure compatibility across different systems, a unified communication bridge for seamless integration of various simulation tools, and synchronized orchestration of input and output across simulators. This framework facilitates the development of sophisticated digital twins for autonomous vehicle testing and sets a new standard in simulation accuracy and flexibility. The paper further explores the application of BlueICE in two distinct case studies: the ICAT indoor testbed and the STAR campus outdoor testbed at the University of Delaware. These case studies demonstrate BlueICE's capability to create sophisticated digital twins for autonomous vehicle testing and underline its potential as a standardized testbed for future autonomous driving technologies.