 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Scalable Agentic 3D Scene Generation for Embodied AI
Feb 10, 2026Real-world data collection for embodied agents remains costly and unsafe, calling for scalable, realistic, and simulator-ready 3D environments. However, existing scene-generation systems often rely on rule-based or task-specific pipelines, yielding artifacts and physically invalid scenes. We present SAGE, an agentic framework that, given a user-specified embodied task (e.g., "pick up a bowl and place it on the table"), understands the intent and automatically generates simulation-ready environments at scale. The agent couples multiple generators for layout and object composition with critics that evaluate semantic plausibility, visual realism, and physical stability. Through iterative reasoning and adaptive tool selection, it self-refines the scenes until meeting user intent and physical validity. The resulting environments are realistic, diverse, and directly deployable in modern simulators for policy training. Policies trained purely on this data exhibit clear scaling trends and generalize to unseen objects and layouts, demonstrating the promise of simulation-driven scaling for embodied AI. Code, demos, and the SAGE-10k dataset can be found on the project page here: https://nvlabs.github.io/sage.
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
Efficient Part-level 3D Object Generation via Dual Volume Packing
Jun 11, 2025Recent progress in 3D object generation has greatly improved both the quality and efficiency. However, most existing methods generate a single mesh with all parts fused together, which limits the ability to edit or manipulate individual parts. A key challenge is that different objects may have a varying number of parts. To address this, we propose a new end-to-end framework for part-level 3D object generation. Given a single input image, our method generates high-quality 3D objects with an arbitrary number of complete and semantically meaningful parts. We introduce a dual volume packing strategy that organizes all parts into two complementary volumes, allowing for the creation of complete and interleaved parts that assemble into the final object. Experiments show that our model achieves better quality, diversity, and generalization than previous image-based part-level generation methods.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
ChatSplat: 3D Conversational Gaussian Splatting
Dec 01, 2024
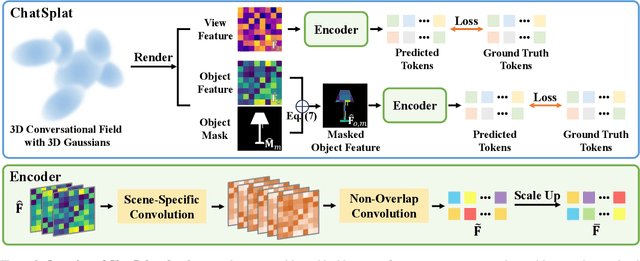

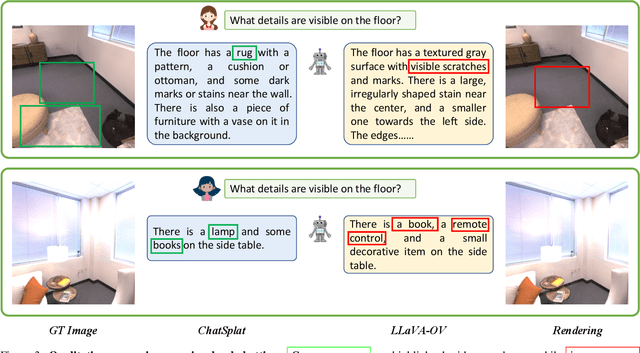
Humans naturally interact with their 3D surroundings using language, and modeling 3D language fields for scene understanding and interaction has gained growing interest. This paper introduces ChatSplat, a system that constructs a 3D language field, enabling rich chat-based interaction within 3D space. Unlike existing methods that primarily use CLIP-derived language features focused solely on segmentation, ChatSplat facilitates interaction on three levels: objects, views, and the entire 3D scene. For view-level interaction, we designed an encoder that encodes the rendered feature map of each view into tokens, which are then processed by a large language model (LLM) for conversation. At the scene level, ChatSplat combines multi-view tokens, enabling interactions that consider the entire scene. For object-level interaction, ChatSplat uses a patch-wise language embedding, unlike LangSplat's pixel-wise language embedding that implicitly includes mask and embedding. Here, we explicitly decouple the language embedding into separate mask and feature map representations, allowing more flexible object-level interaction. To address the challenge of learning 3D Gaussians posed by the complex and diverse distribution of language embeddings used in the LLM, we introduce a learnable normalization technique to standardize these embeddings, facilitating effective learning. Extensive experimental results demonstrate that ChatSplat supports multi-level interactions -- object, view, and scene -- within 3D space, enhancing both understanding and engagement.
Edify 3D: Scalable High-Quality 3D Asset Generation
Nov 11, 2024
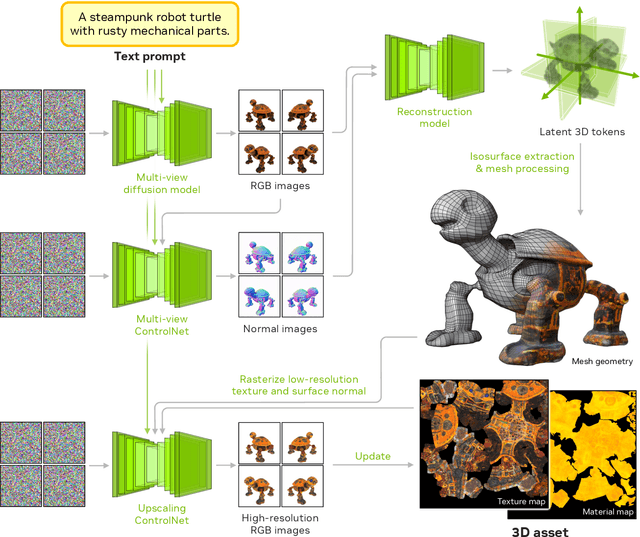
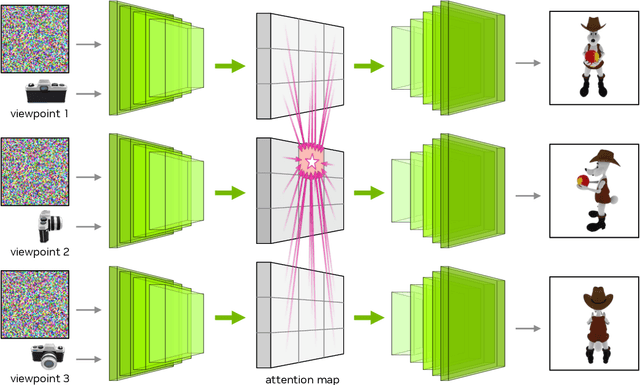

We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
VCR-GauS: View Consistent Depth-Normal Regularizer for Gaussian Surface Reconstruction
Jun 09, 2024
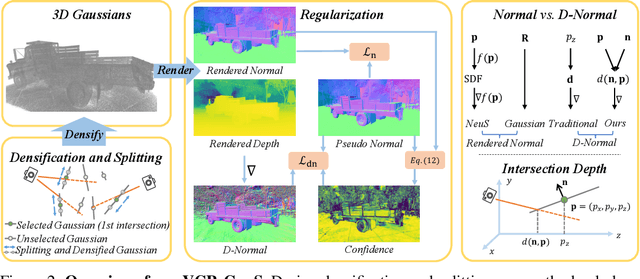


Although 3D Gaussian Splatting has been widely studied because of its realistic and efficient novel-view synthesis, it is still challenging to extract a high-quality surface from the point-based representation. Previous works improve the surface by incorporating geometric priors from the off-the-shelf normal estimator. However, there are two main limitations: 1) Supervising normal rendered from 3D Gaussians updates only the rotation parameter while neglecting other geometric parameters; 2) The inconsistency of predicted normal maps across multiple views may lead to severe reconstruction artifacts. In this paper, we propose a Depth-Normal regularizer that directly couples normal with other geometric parameters, leading to full updates of the geometric parameters from normal regularization. We further propose a confidence term to mitigate inconsistencies of normal predictions across multiple views. Moreover, we also introduce a densification and splitting strategy to regularize the size and distribution of 3D Gaussians for more accurate surface modeling. Compared with Gaussian-based baselines, experiments show that our approach obtains better reconstruction quality and maintains competitive appearance quality at faster training speed and 100+ FPS rendering. Our code will be made open-source upon paper acceptance.
4D Gaussian Splatting: Towards Efficient Novel View Synthesis for Dynamic Scenes
Feb 07, 2024We consider the problem of novel view synthesis (NVS) for dynamic scenes. Recent neural approaches have accomplished exceptional NVS results for static 3D scenes, but extensions to 4D time-varying scenes remain non-trivial. Prior efforts often encode dynamics by learning a canonical space plus implicit or explicit deformation fields, which struggle in challenging scenarios like sudden movements or capturing high-fidelity renderings. In this paper, we introduce 4D Gaussian Splatting (4DGS), a novel method that represents dynamic scenes with anisotropic 4D XYZT Gaussians, inspired by the success of 3D Gaussian Splatting in static scenes. We model dynamics at each timestamp by temporally slicing the 4D Gaussians, which naturally compose dynamic 3D Gaussians and can be seamlessly projected into images. As an explicit spatial-temporal representation, 4DGS demonstrates powerful capabilities for modeling complicated dynamics and fine details, especially for scenes with abrupt motions. We further implement our temporal slicing and splatting techniques in a highly optimized CUDA acceleration framework, achieving real-time inference rendering speeds of up to 277 FPS on an RTX 3090 GPU and 583 FPS on an RTX 4090 GPU. Rigorous evaluations on scenes with diverse motions showcase the superior efficiency and effectiveness of 4DGS, which consistently outperforms existing methods both quantitatively and qualitatively.