 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
SceneAssistant: A Visual Feedback Agent for Open-Vocabulary 3D Scene Generation
Mar 12, 2026Text-to-3D scene generation from natural language is highly desirable for digital content creation. However, existing methods are largely domain-restricted or reliant on predefined spatial relationships, limiting their capacity for unconstrained, open-vocabulary 3D scene synthesis. In this paper, we introduce SceneAssistant, a visual-feedback-driven agent designed for open-vocabulary 3D scene generation. Our framework leverages modern 3D object generation model along with the spatial reasoning and planning capabilities of Vision-Language Models (VLMs). To enable open-vocabulary scene composition, we provide the VLMs with a comprehensive set of atomic operations (e.g., Scale, Rotate, FocusOn). At each interaction step, the VLM receives rendered visual feedback and takes actions accordingly, iteratively refining the scene to achieve more coherent spatial arrangements and better alignment with the input text. Experimental results demonstrate that our method can generate diverse, open-vocabulary, and high-quality 3D scenes. Both qualitative analysis and quantitative human evaluations demonstrate the superiority of our approach over existing methods. Furthermore, our method allows users to instruct the agent to edit existing scenes based on natural language commands. Our code is available at https://github.com/ROUJINN/SceneAssistant
GaussianFluent: Gaussian Simulation for Dynamic Scenes with Mixed Materials
Jan 14, 20263D Gaussian Splatting (3DGS) has emerged as a prominent 3D representation for high-fidelity and real-time rendering. Prior work has coupled physics simulation with Gaussians, but predominantly targets soft, deformable materials, leaving brittle fracture largely unresolved. This stems from two key obstacles: the lack of volumetric interiors with coherent textures in GS representation, and the absence of fracture-aware simulation methods for Gaussians. To address these challenges, we introduce GaussianFluent, a unified framework for realistic simulation and rendering of dynamic object states. First, it synthesizes photorealistic interiors by densifying internal Gaussians guided by generative models. Second, it integrates an optimized Continuum Damage Material Point Method (CD-MPM) to enable brittle fracture simulation at remarkably high speed. Our approach handles complex scenarios including mixed-material objects and multi-stage fracture propagation, achieving results infeasible with previous methods. Experiments clearly demonstrate GaussianFluent's capability for photo-realistic, real-time rendering with structurally consistent interiors, highlighting its potential for downstream application, such as VR and Robotics.
Efficient Part-level 3D Object Generation via Dual Volume Packing
Jun 11, 2025Recent progress in 3D object generation has greatly improved both the quality and efficiency. However, most existing methods generate a single mesh with all parts fused together, which limits the ability to edit or manipulate individual parts. A key challenge is that different objects may have a varying number of parts. To address this, we propose a new end-to-end framework for part-level 3D object generation. Given a single input image, our method generates high-quality 3D objects with an arbitrary number of complete and semantically meaningful parts. We introduce a dual volume packing strategy that organizes all parts into two complementary volumes, allowing for the creation of complete and interleaved parts that assemble into the final object. Experiments show that our model achieves better quality, diversity, and generalization than previous image-based part-level generation methods.
Decompositional Neural Scene Reconstruction with Generative Diffusion Prior
Mar 19, 2025Decompositional reconstruction of 3D scenes, with complete shapes and detailed texture of all objects within, is intriguing for downstream applications but remains challenging, particularly with sparse views as input. Recent approaches incorporate semantic or geometric regularization to address this issue, but they suffer significant degradation in underconstrained areas and fail to recover occluded regions. We argue that the key to solving this problem lies in supplementing missing information for these areas. To this end, we propose DP-Recon, which employs diffusion priors in the form of Score Distillation Sampling (SDS) to optimize the neural representation of each individual object under novel views. This provides additional information for the underconstrained areas, but directly incorporating diffusion prior raises potential conflicts between the reconstruction and generative guidance. Therefore, we further introduce a visibility-guided approach to dynamically adjust the per-pixel SDS loss weights. Together these components enhance both geometry and appearance recovery while remaining faithful to input images. Extensive experiments across Replica and ScanNet++ demonstrate that our method significantly outperforms SOTA methods. Notably, it achieves better object reconstruction under 10 views than the baselines under 100 views. Our method enables seamless text-based editing for geometry and appearance through SDS optimization and produces decomposed object meshes with detailed UV maps that support photorealistic Visual effects (VFX) editing. The project page is available at https://dp-recon.github.io/.
TACO: Taming Diffusion for in-the-wild Video Amodal Completion
Mar 15, 2025Humans can infer complete shapes and appearances of objects from limited visual cues, relying on extensive prior knowledge of the physical world. However, completing partially observable objects while ensuring consistency across video frames remains challenging for existing models, especially for unstructured, in-the-wild videos. This paper tackles the task of Video Amodal Completion (VAC), which aims to generate the complete object consistently throughout the video given a visual prompt specifying the object of interest. Leveraging the rich, consistent manifolds learned by pre-trained video diffusion models, we propose a conditional diffusion model, TACO, that repurposes these manifolds for VAC. To enable its effective and robust generalization to challenging in-the-wild scenarios, we curate a large-scale synthetic dataset with multiple difficulty levels by systematically imposing occlusions onto un-occluded videos. Building on this, we devise a progressive fine-tuning paradigm that starts with simpler recovery tasks and gradually advances to more complex ones. We demonstrate TACO's versatility on a wide range of in-the-wild videos from Internet, as well as on diverse, unseen datasets commonly used in autonomous driving, robotic manipulation, and scene understanding. Moreover, we show that TACO can be effectively applied to various downstream tasks like object reconstruction and pose estimation, highlighting its potential to facilitate physical world understanding and reasoning. Our project page is available at https://jason-aplp.github.io/TACO.
Building Interactable Replicas of Complex Articulated Objects via Gaussian Splatting
Feb 26, 2025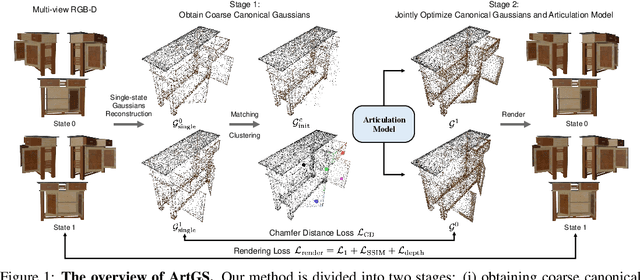
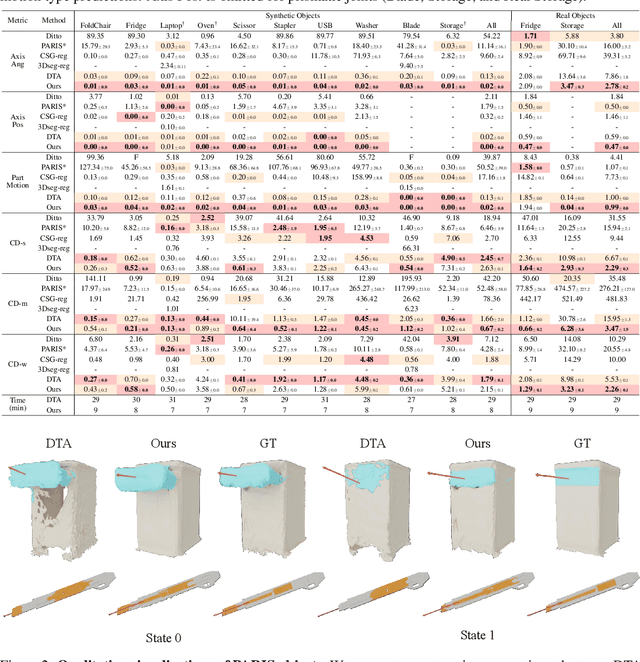

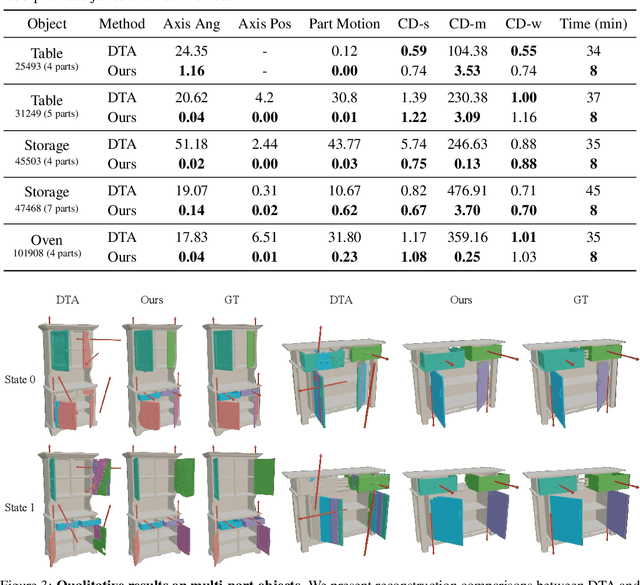
Building articulated objects is a key challenge in computer vision. Existing methods often fail to effectively integrate information across different object states, limiting the accuracy of part-mesh reconstruction and part dynamics modeling, particularly for complex multi-part articulated objects. We introduce ArtGS, a novel approach that leverages 3D Gaussians as a flexible and efficient representation to address these issues. Our method incorporates canonical Gaussians with coarse-to-fine initialization and updates for aligning articulated part information across different object states, and employs a skinning-inspired part dynamics modeling module to improve both part-mesh reconstruction and articulation learning. Extensive experiments on both synthetic and real-world datasets, including a new benchmark for complex multi-part objects, demonstrate that ArtGS achieves state-of-the-art performance in joint parameter estimation and part mesh reconstruction. Our approach significantly improves reconstruction quality and efficiency, especially for multi-part articulated objects. Additionally, we provide comprehensive analyses of our design choices, validating the effectiveness of each component to highlight potential areas for future improvement.
MOVIS: Enhancing Multi-Object Novel View Synthesis for Indoor Scenes
Dec 16, 2024



Repurposing pre-trained diffusion models has been proven to be effective for NVS. However, these methods are mostly limited to a single object; directly applying such methods to compositional multi-object scenarios yields inferior results, especially incorrect object placement and inconsistent shape and appearance under novel views. How to enhance and systematically evaluate the cross-view consistency of such models remains under-explored. To address this issue, we propose MOVIS to enhance the structural awareness of the view-conditioned diffusion model for multi-object NVS in terms of model inputs, auxiliary tasks, and training strategy. First, we inject structure-aware features, including depth and object mask, into the denoising U-Net to enhance the model's comprehension of object instances and their spatial relationships. Second, we introduce an auxiliary task requiring the model to simultaneously predict novel view object masks, further improving the model's capability in differentiating and placing objects. Finally, we conduct an in-depth analysis of the diffusion sampling process and carefully devise a structure-guided timestep sampling scheduler during training, which balances the learning of global object placement and fine-grained detail recovery. To systematically evaluate the plausibility of synthesized images, we propose to assess cross-view consistency and novel view object placement alongside existing image-level NVS metrics. Extensive experiments on challenging synthetic and realistic datasets demonstrate that our method exhibits strong generalization capabilities and produces consistent novel view synthesis, highlighting its potential to guide future 3D-aware multi-object NVS tasks.
Template-free Articulated Gaussian Splatting for Real-time Reposable Dynamic View Synthesis
Dec 07, 2024While novel view synthesis for dynamic scenes has made significant progress, capturing skeleton models of objects and re-posing them remains a challenging task. To tackle this problem, in this paper, we propose a novel approach to automatically discover the associated skeleton model for dynamic objects from videos without the need for object-specific templates. Our approach utilizes 3D Gaussian Splatting and superpoints to reconstruct dynamic objects. Treating superpoints as rigid parts, we can discover the underlying skeleton model through intuitive cues and optimize it using the kinematic model. Besides, an adaptive control strategy is applied to avoid the emergence of redundant superpoints. Extensive experiments demonstrate the effectiveness and efficiency of our method in obtaining re-posable 3D objects. Not only can our approach achieve excellent visual fidelity, but it also allows for the real-time rendering of high-resolution images.
Superpoint Gaussian Splatting for Real-Time High-Fidelity Dynamic Scene Reconstruction
Jun 06, 2024Rendering novel view images in dynamic scenes is a crucial yet challenging task. Current methods mainly utilize NeRF-based methods to represent the static scene and an additional time-variant MLP to model scene deformations, resulting in relatively low rendering quality as well as slow inference speed. To tackle these challenges, we propose a novel framework named Superpoint Gaussian Splatting (SP-GS). Specifically, our framework first employs explicit 3D Gaussians to reconstruct the scene and then clusters Gaussians with similar properties (e.g., rotation, translation, and location) into superpoints. Empowered by these superpoints, our method manages to extend 3D Gaussian splatting to dynamic scenes with only a slight increase in computational expense. Apart from achieving state-of-the-art visual quality and real-time rendering under high resolutions, the superpoint representation provides a stronger manipulation capability. Extensive experiments demonstrate the practicality and effectiveness of our approach on both synthetic and real-world datasets. Please see our project page at https://dnvtmf.github.io/SP_GS.github.io.