 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifting Unlabeled Internet-level Data for 3D Scene Understanding
Apr 02, 2026Annotated 3D scene data is scarce and expensive to acquire, while abundant unlabeled videos are readily available on the internet. In this paper, we demonstrate that carefully designed data engines can leverage web-curated, unlabeled videos to automatically generate training data, to facilitate end-to-end models in 3D scene understanding alongside human-annotated datasets. We identify and analyze bottlenecks in automated data generation, revealing critical factors that determine the efficiency and effectiveness of learning from unlabeled data. To validate our approach across different perception granularities, we evaluate on three tasks spanning low-level perception, i.e., 3D object detection and instance segmentation, to high-evel reasoning, i.e., 3D spatial Visual Question Answering (VQA) and Vision-Lanugage Navigation (VLN). Models trained on our generated data demonstrate strong zero-shot performance and show further improvement after finetuning. This demonstrates the viability of leveraging readily available web data as a path toward more capable scene understanding systems.
Learning Physics-Grounded 4D Dynamics with Neural Gaussian Force Fields
Jan 29, 2026Predicting physical dynamics from raw visual data remains a major challenge in AI. While recent video generation models have achieved impressive visual quality, they still cannot consistently generate physically plausible videos due to a lack of modeling of physical laws. Recent approaches combining 3D Gaussian splatting and physics engines can produce physically plausible videos, but are hindered by high computational costs in both reconstruction and simulation, and often lack robustness in complex real-world scenarios. To address these issues, we introduce Neural Gaussian Force Field (NGFF), an end-to-end neural framework that integrates 3D Gaussian perception with physics-based dynamic modeling to generate interactive, physically realistic 4D videos from multi-view RGB inputs, achieving two orders of magnitude faster than prior Gaussian simulators. To support training, we also present GSCollision, a 4D Gaussian dataset featuring diverse materials, multi-object interactions, and complex scenes, totaling over 640k rendered physical videos (~4 TB). Evaluations on synthetic and real 3D scenarios show NGFF's strong generalization and robustness in physical reasoning, advancing video prediction towards physics-grounded world models.
3D Scene Change Modeling With Consistent Multi-View Aggregation
Dec 28, 2025Change detection plays a vital role in scene monitoring, exploration, and continual reconstruction. Existing 3D change detection methods often exhibit spatial inconsistency in the detected changes and fail to explicitly separate pre- and post-change states. To address these limitations, we propose SCaR-3D, a novel 3D scene change detection framework that identifies object-level changes from a dense-view pre-change image sequence and sparse-view post-change images. Our approach consists of a signed-distance-based 2D differencing module followed by multi-view aggregation with voting and pruning, leveraging the consistent nature of 3DGS to robustly separate pre- and post-change states. We further develop a continual scene reconstruction strategy that selectively updates dynamic regions while preserving the unchanged areas. We also contribute CCS3D, a challenging synthetic dataset that allows flexible combinations of 3D change types to support controlled evaluations. Extensive experiments demonstrate that our method achieves both high accuracy and efficiency, outperforming existing methods.
Decompositional Neural Scene Reconstruction with Generative Diffusion Prior
Mar 19, 2025Decompositional reconstruction of 3D scenes, with complete shapes and detailed texture of all objects within, is intriguing for downstream applications but remains challenging, particularly with sparse views as input. Recent approaches incorporate semantic or geometric regularization to address this issue, but they suffer significant degradation in underconstrained areas and fail to recover occluded regions. We argue that the key to solving this problem lies in supplementing missing information for these areas. To this end, we propose DP-Recon, which employs diffusion priors in the form of Score Distillation Sampling (SDS) to optimize the neural representation of each individual object under novel views. This provides additional information for the underconstrained areas, but directly incorporating diffusion prior raises potential conflicts between the reconstruction and generative guidance. Therefore, we further introduce a visibility-guided approach to dynamically adjust the per-pixel SDS loss weights. Together these components enhance both geometry and appearance recovery while remaining faithful to input images. Extensive experiments across Replica and ScanNet++ demonstrate that our method significantly outperforms SOTA methods. Notably, it achieves better object reconstruction under 10 views than the baselines under 100 views. Our method enables seamless text-based editing for geometry and appearance through SDS optimization and produces decomposed object meshes with detailed UV maps that support photorealistic Visual effects (VFX) editing. The project page is available at https://dp-recon.github.io/.
TACO: Taming Diffusion for in-the-wild Video Amodal Completion
Mar 15, 2025Humans can infer complete shapes and appearances of objects from limited visual cues, relying on extensive prior knowledge of the physical world. However, completing partially observable objects while ensuring consistency across video frames remains challenging for existing models, especially for unstructured, in-the-wild videos. This paper tackles the task of Video Amodal Completion (VAC), which aims to generate the complete object consistently throughout the video given a visual prompt specifying the object of interest. Leveraging the rich, consistent manifolds learned by pre-trained video diffusion models, we propose a conditional diffusion model, TACO, that repurposes these manifolds for VAC. To enable its effective and robust generalization to challenging in-the-wild scenarios, we curate a large-scale synthetic dataset with multiple difficulty levels by systematically imposing occlusions onto un-occluded videos. Building on this, we devise a progressive fine-tuning paradigm that starts with simpler recovery tasks and gradually advances to more complex ones. We demonstrate TACO's versatility on a wide range of in-the-wild videos from Internet, as well as on diverse, unseen datasets commonly used in autonomous driving, robotic manipulation, and scene understanding. Moreover, we show that TACO can be effectively applied to various downstream tasks like object reconstruction and pose estimation, highlighting its potential to facilitate physical world understanding and reasoning. Our project page is available at https://jason-aplp.github.io/TACO.
Building Interactable Replicas of Complex Articulated Objects via Gaussian Splatting
Feb 26, 2025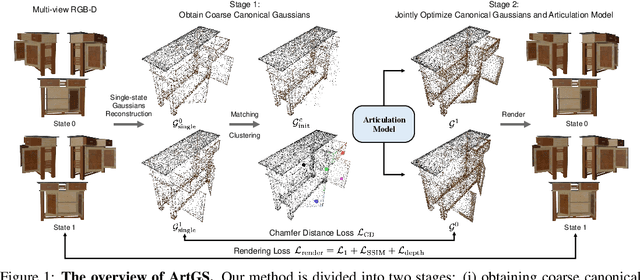
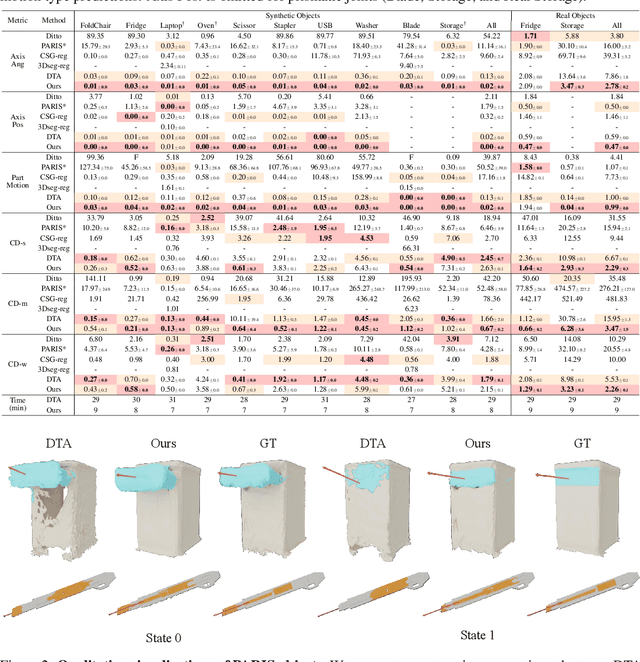

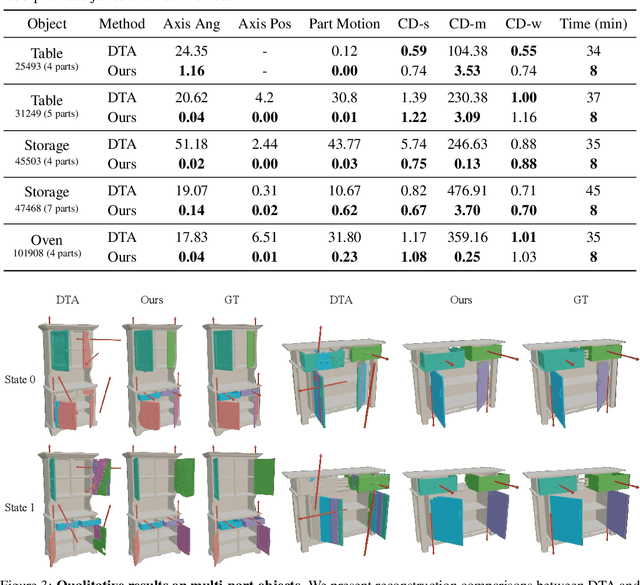
Building articulated objects is a key challenge in computer vision. Existing methods often fail to effectively integrate information across different object states, limiting the accuracy of part-mesh reconstruction and part dynamics modeling, particularly for complex multi-part articulated objects. We introduce ArtGS, a novel approach that leverages 3D Gaussians as a flexible and efficient representation to address these issues. Our method incorporates canonical Gaussians with coarse-to-fine initialization and updates for aligning articulated part information across different object states, and employs a skinning-inspired part dynamics modeling module to improve both part-mesh reconstruction and articulation learning. Extensive experiments on both synthetic and real-world datasets, including a new benchmark for complex multi-part objects, demonstrate that ArtGS achieves state-of-the-art performance in joint parameter estimation and part mesh reconstruction. Our approach significantly improves reconstruction quality and efficiency, especially for multi-part articulated objects. Additionally, we provide comprehensive analyses of our design choices, validating the effectiveness of each component to highlight potential areas for future improvement.
MOVIS: Enhancing Multi-Object Novel View Synthesis for Indoor Scenes
Dec 16, 2024



Repurposing pre-trained diffusion models has been proven to be effective for NVS. However, these methods are mostly limited to a single object; directly applying such methods to compositional multi-object scenarios yields inferior results, especially incorrect object placement and inconsistent shape and appearance under novel views. How to enhance and systematically evaluate the cross-view consistency of such models remains under-explored. To address this issue, we propose MOVIS to enhance the structural awareness of the view-conditioned diffusion model for multi-object NVS in terms of model inputs, auxiliary tasks, and training strategy. First, we inject structure-aware features, including depth and object mask, into the denoising U-Net to enhance the model's comprehension of object instances and their spatial relationships. Second, we introduce an auxiliary task requiring the model to simultaneously predict novel view object masks, further improving the model's capability in differentiating and placing objects. Finally, we conduct an in-depth analysis of the diffusion sampling process and carefully devise a structure-guided timestep sampling scheduler during training, which balances the learning of global object placement and fine-grained detail recovery. To systematically evaluate the plausibility of synthesized images, we propose to assess cross-view consistency and novel view object placement alongside existing image-level NVS metrics. Extensive experiments on challenging synthetic and realistic datasets demonstrate that our method exhibits strong generalization capabilities and produces consistent novel view synthesis, highlighting its potential to guide future 3D-aware multi-object NVS tasks.
PhyRecon: Physically Plausible Neural Scene Reconstruction
Apr 28, 2024



While neural implicit representations have gained popularity in multi-view 3D reconstruction, previous work struggles to yield physically plausible results, thereby limiting their applications in physics-demanding domains like embodied AI and robotics. The lack of plausibility originates from both the absence of physics modeling in the existing pipeline and their inability to recover intricate geometrical structures. In this paper, we introduce PhyRecon, which stands as the first approach to harness both differentiable rendering and differentiable physics simulation to learn implicit surface representations. Our framework proposes a novel differentiable particle-based physical simulator seamlessly integrated with the neural implicit representation. At its core is an efficient transformation between SDF-based implicit representation and explicit surface points by our proposed algorithm, Surface Points Marching Cubes (SP-MC), enabling differentiable learning with both rendering and physical losses. Moreover, we model both rendering and physical uncertainty to identify and compensate for the inconsistent and inaccurate monocular geometric priors. The physical uncertainty additionally enables a physics-guided pixel sampling to enhance the learning of slender structures. By amalgamating these techniques, our model facilitates efficient joint modeling with appearance, geometry, and physics. Extensive experiments demonstrate that PhyRecon significantly outperforms all state-of-the-art methods in terms of reconstruction quality. Our reconstruction results also yield superior physical stability, verified by Isaac Gym, with at least a 40% improvement across all datasets, opening broader avenues for future physics-based applications.
Single-view 3D Scene Reconstruction with High-fidelity Shape and Texture
Nov 01, 2023Reconstructing detailed 3D scenes from single-view images remains a challenging task due to limitations in existing approaches, which primarily focus on geometric shape recovery, overlooking object appearances and fine shape details. To address these challenges, we propose a novel framework for simultaneous high-fidelity recovery of object shapes and textures from single-view images. Our approach utilizes the proposed Single-view neural implicit Shape and Radiance field (SSR) representations to leverage both explicit 3D shape supervision and volume rendering of color, depth, and surface normal images. To overcome shape-appearance ambiguity under partial observations, we introduce a two-stage learning curriculum incorporating both 3D and 2D supervisions. A distinctive feature of our framework is its ability to generate fine-grained textured meshes while seamlessly integrating rendering capabilities into the single-view 3D reconstruction model. This integration enables not only improved textured 3D object reconstruction by 27.7% and 11.6% on the 3D-FRONT and Pix3D datasets, respectively, but also supports the rendering of images from novel viewpoints. Beyond individual objects, our approach facilitates composing object-level representations into flexible scene representations, thereby enabling applications such as holistic scene understanding and 3D scene editing. We conduct extensive experiments to demonstrate the effectiveness of our method.