 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOAgents: Multi-Agent Framework to Learn and Navigate Routing Problems Search Space
May 20, 2026Although Vehicle Routing Problems (VRP) are essential to many real-world systems, they remain computationally intractable at scale due to their combinatorial complexity. Traditional heuristics rely on handcrafted rules for local improvements and occasional \textit{jumps} to escape local minima, but often struggle to generalize across diverse instances. We introduce \textbf{COAgents}, a cooperative multi-agent framework that models the search process as a graph: nodes represent solutions, and edges correspond to either local refinements or large perturbations for diversification (i.e., jumps). A \textit{Partial Search Graph} (PSG) is dynamically constructed during search, enabling COAgents to train a Node Selection Agent and a Move Selection Agent to guide intensification, and a Jump Agent to trigger well-timed explorations of new regions. Unlike end-to-end learning approaches, COAgents cleanly separates problem-agnostic search control from compact domain-specific encoding, facilitating adaptability across tasks. Extensive experiments on the CVRP and VRPTW benchmarks show that COAgents remains competitive with several learn-to-search baselines on CVRP and sets a new state of the art among learning-based methods on the more challenging VRPTW instances, reducing the gap to the best-known solutions by 14\% at $N\!=\!100$ and 44\% at $N\!=\!50$ relative to the strongest neural solver (POMO), and by 21\% and 40\% respectively relative to ALNS. Code is available at https://github.com/mahdims/COAgents.
AIvilization v0: Toward Large-Scale Artificial Social Simulation with a Unified Agent Architecture and Adaptive Agent Profiles
Feb 11, 2026AIvilization v0 is a publicly deployed large-scale artificial society that couples a resource-constrained sandbox economy with a unified LLM-agent architecture, aiming to sustain long-horizon autonomy while remaining executable under rapidly changing environment. To mitigate the tension between goal stability and reactive correctness, we introduce (i) a hierarchical branch-thinking planner that decomposes life goals into parallel objective branches and uses simulation-guided validation plus tiered re-planning to ensure feasibility; (ii) an adaptive agent profile with dual-process memory that separates short-term execution traces from long-term semantic consolidation, enabling persistent yet evolving identity; and (iii) a human-in-the-loop steering interface that injects long-horizon objectives and short commands at appropriate abstraction levels, with effects propagated through memory rather than brittle prompt overrides. The environment integrates physiological survival costs, non-substitutable multi-tier production, an AMM-based price mechanism, and a gated education-occupation system. Using high-frequency transactions from the platforms mature phase, we find stable markets that reproduce key stylized facts (heavy-tailed returns and volatility clustering) and produce structured wealth stratification driven by education and access constraints. Ablations show simplified planners can match performance on narrow tasks, while the full architecture is more robust under multi-objective, long-horizon settings, supporting delayed investment and sustained exploration.
3D Scene Change Modeling With Consistent Multi-View Aggregation
Dec 28, 2025Change detection plays a vital role in scene monitoring, exploration, and continual reconstruction. Existing 3D change detection methods often exhibit spatial inconsistency in the detected changes and fail to explicitly separate pre- and post-change states. To address these limitations, we propose SCaR-3D, a novel 3D scene change detection framework that identifies object-level changes from a dense-view pre-change image sequence and sparse-view post-change images. Our approach consists of a signed-distance-based 2D differencing module followed by multi-view aggregation with voting and pruning, leveraging the consistent nature of 3DGS to robustly separate pre- and post-change states. We further develop a continual scene reconstruction strategy that selectively updates dynamic regions while preserving the unchanged areas. We also contribute CCS3D, a challenging synthetic dataset that allows flexible combinations of 3D change types to support controlled evaluations. Extensive experiments demonstrate that our method achieves both high accuracy and efficiency, outperforming existing methods.
SMARTAPS: Tool-augmented LLMs for Operations Management
Jul 23, 2025Large language models (LLMs) present intriguing opportunities to enhance user interaction with traditional algorithms and tools in real-world applications. An advanced planning system (APS) is a sophisticated software that leverages optimization to help operations planners create, interpret, and modify an operational plan. While highly beneficial, many customers are priced out of using an APS due to the ongoing costs of consultants responsible for customization and maintenance. To address the need for a more accessible APS expressed by supply chain planners, we present SmartAPS, a conversational system built on a tool-augmented LLM. Our system provides operations planners with an intuitive natural language chat interface, allowing them to query information, perform counterfactual reasoning, receive recommendations, and execute scenario analysis to better manage their operation. A short video demonstrating the system has been released: https://youtu.be/KtIrJjlDbyw
Decompositional Neural Scene Reconstruction with Generative Diffusion Prior
Mar 19, 2025Decompositional reconstruction of 3D scenes, with complete shapes and detailed texture of all objects within, is intriguing for downstream applications but remains challenging, particularly with sparse views as input. Recent approaches incorporate semantic or geometric regularization to address this issue, but they suffer significant degradation in underconstrained areas and fail to recover occluded regions. We argue that the key to solving this problem lies in supplementing missing information for these areas. To this end, we propose DP-Recon, which employs diffusion priors in the form of Score Distillation Sampling (SDS) to optimize the neural representation of each individual object under novel views. This provides additional information for the underconstrained areas, but directly incorporating diffusion prior raises potential conflicts between the reconstruction and generative guidance. Therefore, we further introduce a visibility-guided approach to dynamically adjust the per-pixel SDS loss weights. Together these components enhance both geometry and appearance recovery while remaining faithful to input images. Extensive experiments across Replica and ScanNet++ demonstrate that our method significantly outperforms SOTA methods. Notably, it achieves better object reconstruction under 10 views than the baselines under 100 views. Our method enables seamless text-based editing for geometry and appearance through SDS optimization and produces decomposed object meshes with detailed UV maps that support photorealistic Visual effects (VFX) editing. The project page is available at https://dp-recon.github.io/.
Evaluating LLM Reasoning in the Operations Research Domain with ORQA
Dec 22, 2024

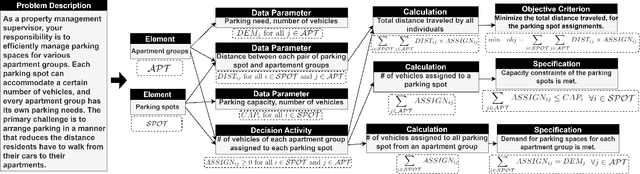
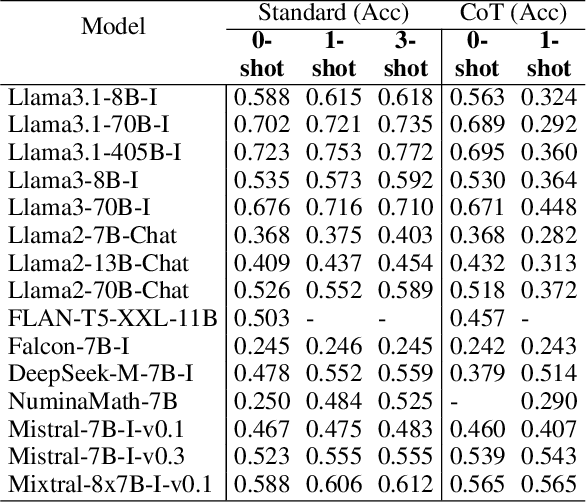
In this paper, we introduce and apply Operations Research Question Answering (ORQA), a new benchmark designed to assess the generalization capabilities of Large Language Models (LLMs) in the specialized technical domain of Operations Research (OR). This benchmark evaluates whether LLMs can emulate the knowledge and reasoning skills of OR experts when confronted with diverse and complex optimization problems. The dataset, developed by OR experts, features real-world optimization problems that demand multistep reasoning to construct their mathematical models. Our evaluations of various open source LLMs, such as LLaMA 3.1, DeepSeek, and Mixtral, reveal their modest performance, highlighting a gap in their ability to generalize to specialized technical domains. This work contributes to the ongoing discourse on LLMs generalization capabilities, offering valuable insights for future research in this area. The dataset and evaluation code are publicly available.
GeoPro-Net: Learning Interpretable Spatiotemporal Prediction Models through Statistically-Guided Geo-Prototyping
Dec 19, 2024
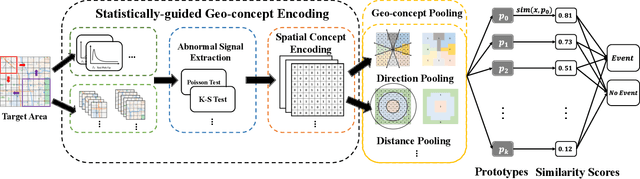
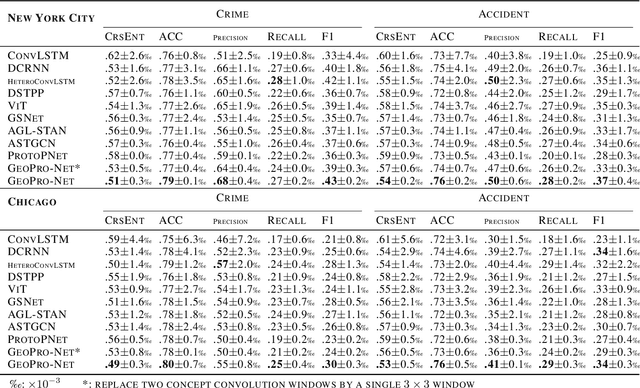
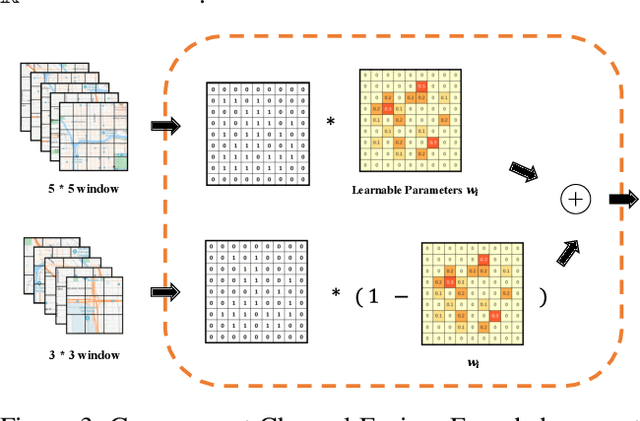
The problem of forecasting spatiotemporal events such as crimes and accidents is crucial to public safety and city management. Besides accuracy, interpretability is also a key requirement for spatiotemporal forecasting models to justify the decisions. Interpretation of the spatiotemporal forecasting mechanism is, however, challenging due to the complexity of multi-source spatiotemporal features, the non-intuitive nature of spatiotemporal patterns for non-expert users, and the presence of spatial heterogeneity in the data. Currently, no existing deep learning model intrinsically interprets the complex predictive process learned from multi-source spatiotemporal features. To bridge the gap, we propose GeoPro-Net, an intrinsically interpretable spatiotemporal model for spatiotemporal event forecasting problems. GeoPro-Net introduces a novel Geo-concept convolution operation, which employs statistical tests to extract predictive patterns in the input as Geo-concepts, and condenses the Geo-concept-encoded input through interpretable channel fusion and geographic-based pooling. In addition, GeoPro-Net learns different sets of prototypes of concepts inherently, and projects them to real-world cases for interpretation. Comprehensive experiments and case studies on four real-world datasets demonstrate that GeoPro-Net provides better interpretability while still achieving competitive prediction performance compared with state-of-the-art baselines.
Learn2Aggregate: Supervised Generation of Chvátal-Gomory Cuts Using Graph Neural Networks
Sep 10, 2024
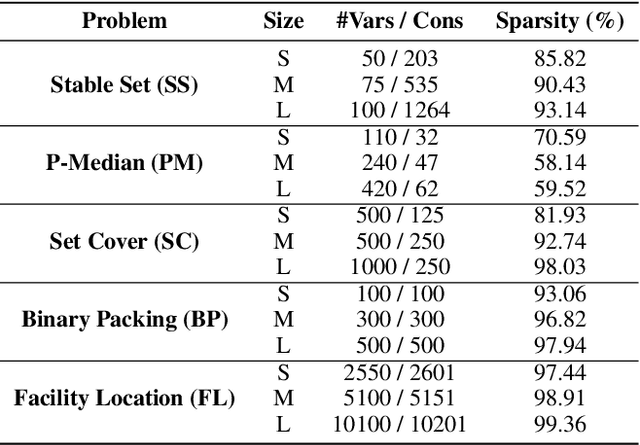
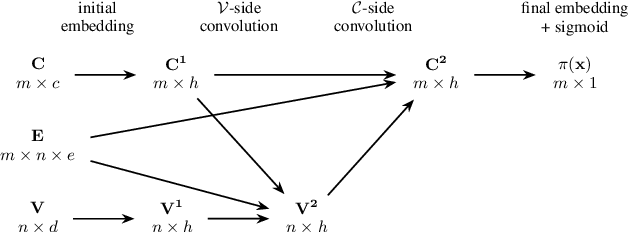
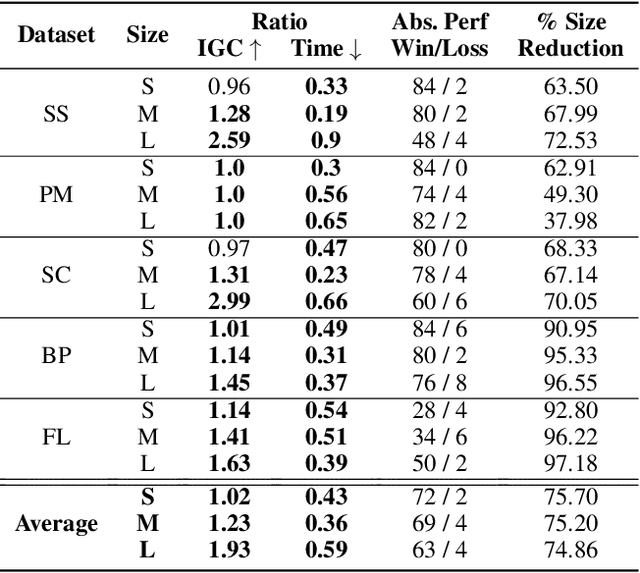
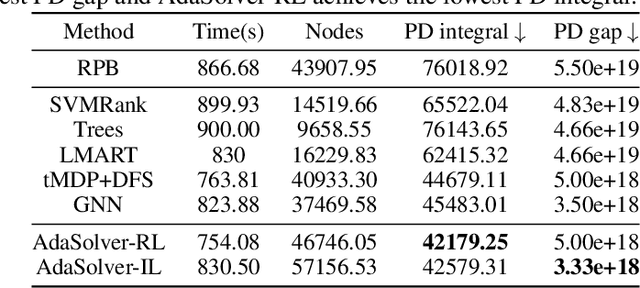
We present $\textit{Learn2Aggregate}$, a machine learning (ML) framework for optimizing the generation of Chv\'atal-Gomory (CG) cuts in mixed integer linear programming (MILP). The framework trains a graph neural network to classify useful constraints for aggregation in CG cut generation. The ML-driven CG separator selectively focuses on a small set of impactful constraints, improving runtimes without compromising the strength of the generated cuts. Key to our approach is the formulation of a constraint classification task which favours sparse aggregation of constraints, consistent with empirical findings. This, in conjunction with a careful constraint labeling scheme and a hybrid of deep learning and feature engineering, results in enhanced CG cut generation across five diverse MILP benchmarks. On the largest test sets, our method closes roughly $\textit{twice}$ as much of the integrality gap as the standard CG method while running 40$% faster. This performance improvement is due to our method eliminating 75% of the constraints prior to aggregation.
Gait Patterns as Biomarkers: A Video-Based Approach for Classifying Scoliosis
Jul 09, 2024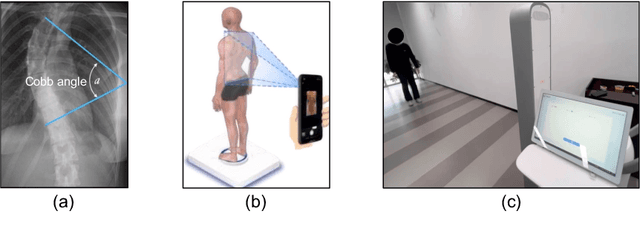
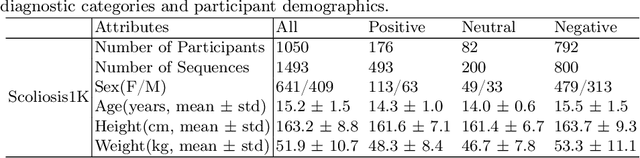

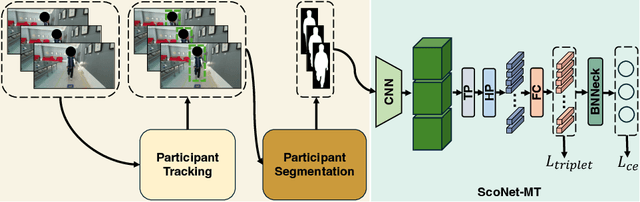
Scoliosis poses significant diagnostic challenges, particularly in adolescents, where early detection is crucial for effective treatment. Traditional diagnostic and follow-up methods, which rely on physical examinations and radiography, face limitations due to the need for clinical expertise and the risk of radiation exposure, thus restricting their use for widespread early screening. In response, we introduce a novel, video-based, non-invasive method for scoliosis classification using gait analysis, which circumvents these limitations. This study presents Scoliosis1K, the first large-scale dataset tailored for video-based scoliosis classification, encompassing over one thousand adolescents. Leveraging this dataset, we developed ScoNet, an initial model that encountered challenges in dealing with the complexities of real-world data. This led to the creation of ScoNet-MT, an enhanced model incorporating multi-task learning, which exhibits promising diagnostic accuracy for application purposes. Our findings demonstrate that gait can be a non-invasive biomarker for scoliosis, revolutionizing screening practices with deep learning and setting a precedent for non-invasive diagnostic methodologies. The dataset and code are publicly available at https://zhouzi180.github.io/Scoliosis1K/.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024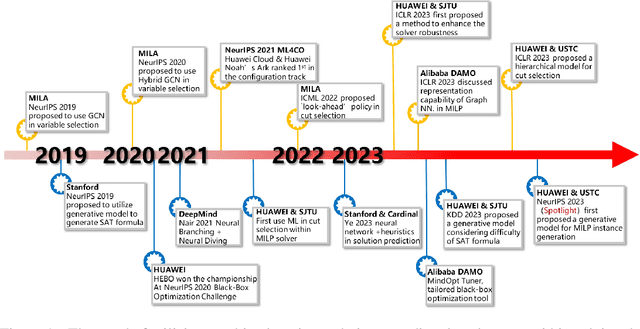

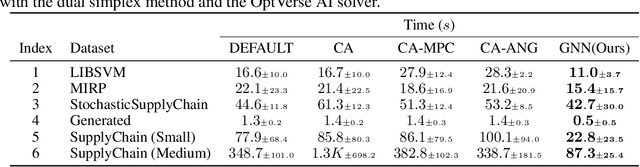
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.