 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECKBench: Benchmarking Multi-Agent Frameworks for Academic Slide Generation and Editing
Feb 10, 2026Automatically generating and iteratively editing academic slide decks requires more than document summarization. It demands faithful content selection, coherent slide organization, layout-aware rendering, and robust multi-turn instruction following. However, existing benchmarks and evaluation protocols do not adequately measure these challenges. To address this gap, we introduce the Deck Edits and Compliance Kit Benchmark (DECKBench), an evaluation framework for multi-agent slide generation and editing. DECKBench is built on a curated dataset of paper to slide pairs augmented with realistic, simulated editing instructions. Our evaluation protocol systematically assesses slide-level and deck-level fidelity, coherence, layout quality, and multi-turn instruction following. We further implement a modular multi-agent baseline system that decomposes the slide generation and editing task into paper parsing and summarization, slide planning, HTML creation, and iterative editing. Experimental results demonstrate that the proposed benchmark highlights strengths, exposes failure modes, and provides actionable insights for improving multi-agent slide generation and editing systems. Overall, this work establishes a standardized foundation for reproducible and comparable evaluation of academic presentation generation and editing. Code and data are publicly available at https://github.com/morgan-heisler/DeckBench .
MEPIC: Memory Efficient Position Independent Caching for LLM Serving
Dec 18, 2025Modern LLM applications such as deep-research assistants, coding agents, and Retrieval-Augmented Generation (RAG) systems, repeatedly process long prompt histories containing shared document or code chunks, creating significant pressure on the Key Value (KV) cache, which must operate within limited memory while sustaining high throughput and low latency. Prefix caching partially alleviates some of these costs by reusing KV cache for previously processed tokens, but limited by strict prefix matching. Position-independent caching (PIC) enables chunk-level reuse at arbitrary positions, but requires selective recomputation and positional-encoding (PE) adjustments. However, because these operations vary across queries, KV for the same chunk diverges across requests. Moreover, without page alignment, chunk KV layouts diverge in memory, preventing page sharing. These issues result in only modest HBM savings even when many requests reuse the same content. We present MEPIC, a memory-efficient PIC system that enables chunk KV reuse across positions, requests, and batches. MEPIC aligns chunk KV to paged storage, shifts recomputation from token- to block-level so only the first block is request-specific, removes positional encodings via Rotary Position Embedding (RoPE) fusion in the attention kernel, and makes remaining blocks fully shareable. These techniques eliminate most duplicate chunk KV in HBM, reducing usage by up to 2x over state-of-the-art PIC at comparable latency and accuracy, and up to 5x for long prompts, without any model changes.
Enhancing Learned Knowledge in LoRA Adapters Through Efficient Contrastive Decoding on Ascend NPUs
May 20, 2025Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and scalable method to fine-tune and customize large language models (LLMs) for application-specific needs. However, tasks that require complex reasoning or deep contextual understanding are often hindered by biases or interference from the base model when using typical decoding methods like greedy or beam search. These biases can lead to generic or task-agnostic responses from the base model instead of leveraging the LoRA-specific adaptations. In this paper, we introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed to maximize the use of task-specific knowledge in LoRA-adapted models, resulting in better downstream performance. CoLD uses contrastive decoding by scoring candidate tokens based on the divergence between the probability distributions of a LoRA-adapted expert model and the corresponding base model. This approach prioritizes tokens that better align with the LoRA's learned representations, enhancing performance for specialized tasks. While effective, a naive implementation of CoLD is computationally expensive because each decoding step requires evaluating multiple token candidates across both models. To address this, we developed an optimized kernel for Huawei's Ascend NPU. CoLD achieves up to a 5.54% increase in task accuracy while reducing end-to-end latency by 28% compared to greedy decoding. This work provides practical and efficient decoding strategies for fine-tuned LLMs in resource-constrained environments and has broad implications for applied data science in both cloud and on-premises settings.
Learn2Aggregate: Supervised Generation of Chvátal-Gomory Cuts Using Graph Neural Networks
Sep 10, 2024
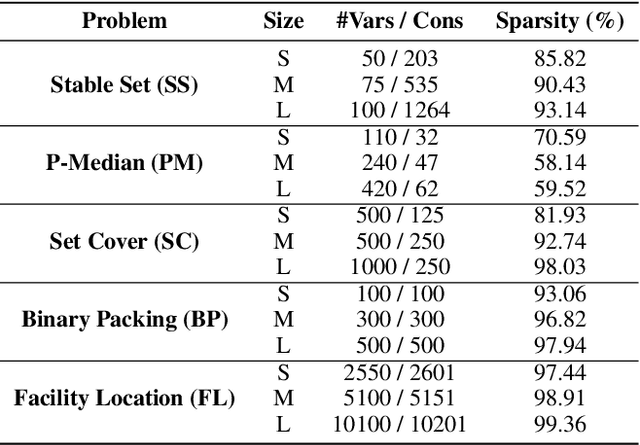
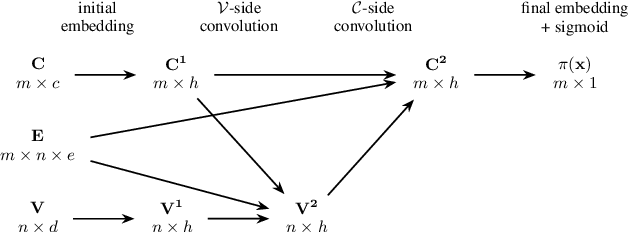
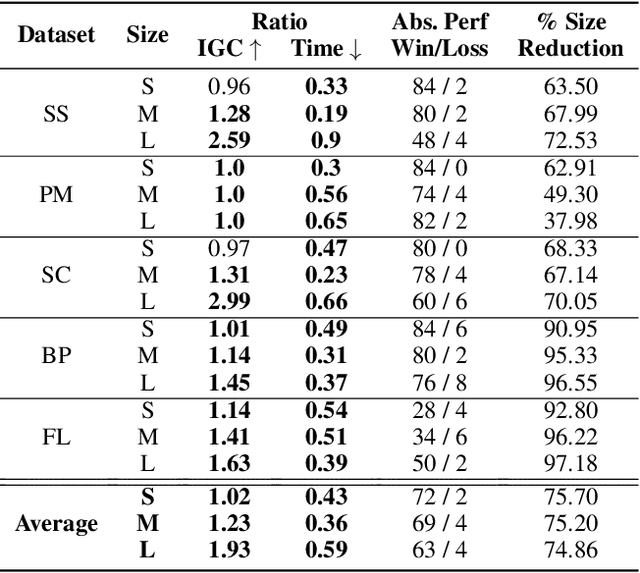
We present $\textit{Learn2Aggregate}$, a machine learning (ML) framework for optimizing the generation of Chv\'atal-Gomory (CG) cuts in mixed integer linear programming (MILP). The framework trains a graph neural network to classify useful constraints for aggregation in CG cut generation. The ML-driven CG separator selectively focuses on a small set of impactful constraints, improving runtimes without compromising the strength of the generated cuts. Key to our approach is the formulation of a constraint classification task which favours sparse aggregation of constraints, consistent with empirical findings. This, in conjunction with a careful constraint labeling scheme and a hybrid of deep learning and feature engineering, results in enhanced CG cut generation across five diverse MILP benchmarks. On the largest test sets, our method closes roughly $\textit{twice}$ as much of the integrality gap as the standard CG method while running 40$% faster. This performance improvement is due to our method eliminating 75% of the constraints prior to aggregation.
DeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning
Jun 12, 2024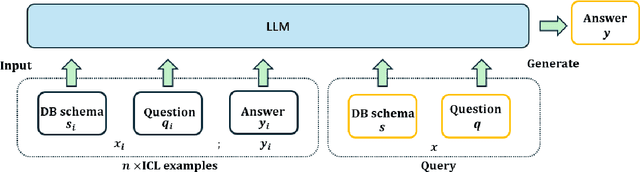

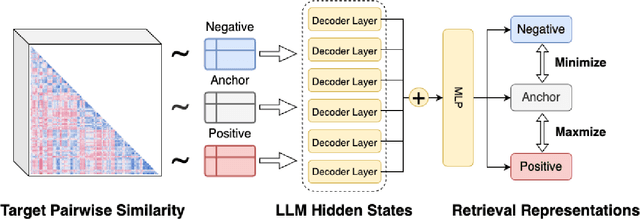

While in-context Learning (ICL) has proven to be an effective technique to improve the performance of Large Language Models (LLMs) in a variety of complex tasks, notably in translating natural language questions into Structured Query Language (NL2SQL), the question of how to select the most beneficial demonstration examples remains an open research problem. While prior works often adapted off-the-shelf encoders to retrieve examples dynamically, an inherent discrepancy exists in the representational capacities between the external retrievers and the LLMs. Further, optimizing the selection of examples is a non-trivial task, since there are no straightforward methods to assess the relative benefits of examples without performing pairwise inference. To address these shortcomings, we propose DeTriever, a novel demonstration retrieval framework that learns a weighted combination of LLM hidden states, where rich semantic information is encoded. To train the model, we propose a proxy score that estimates the relative benefits of examples based on the similarities between output queries. Experiments on two popular NL2SQL benchmarks demonstrate that our method significantly outperforms the state-of-the-art baselines on one-shot NL2SQL tasks.
SQL-Encoder: Improving NL2SQL In-Context Learning Through a Context-Aware Encoder
Mar 24, 2024
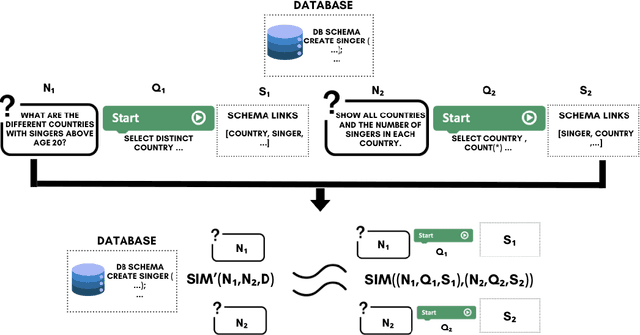
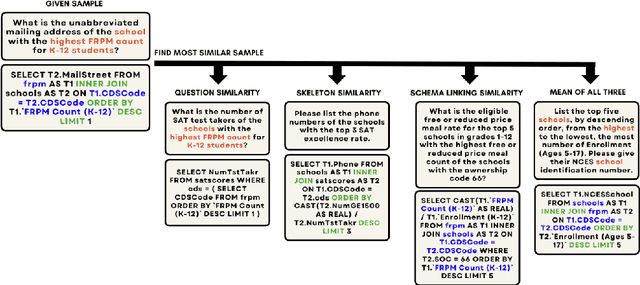

Detecting structural similarity between queries is essential for selecting examples in in-context learning models. However, assessing structural similarity based solely on the natural language expressions of queries, without considering SQL queries, presents a significant challenge. This paper explores the significance of this similarity metric and proposes a model for accurately estimating it. To achieve this, we leverage a dataset comprising 170k question pairs, meticulously curated to train a similarity prediction model. Our comprehensive evaluation demonstrates that the proposed model adeptly captures the structural similarity between questions, as evidenced by improvements in Kendall-Tau distance and precision@k metrics. Notably, our model outperforms strong competitive embedding models from OpenAI and Cohere. Furthermore, compared to these competitive models, our proposed encoder enhances the downstream performance of NL2SQL models in 1-shot in-context learning scenarios by 1-2\% for GPT-3.5-turbo, 4-8\% for CodeLlama-7B, and 2-3\% for CodeLlama-13B.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024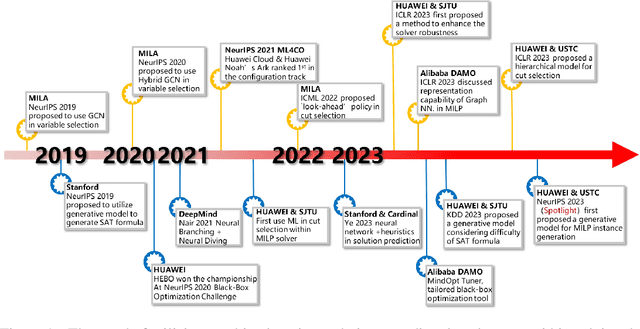
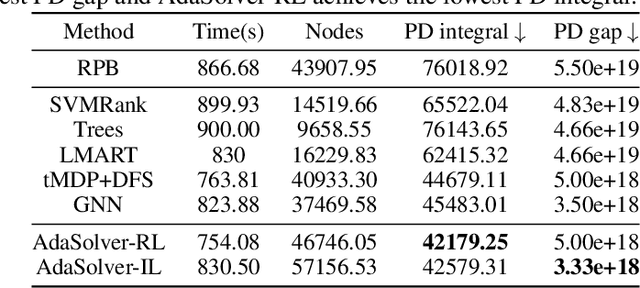

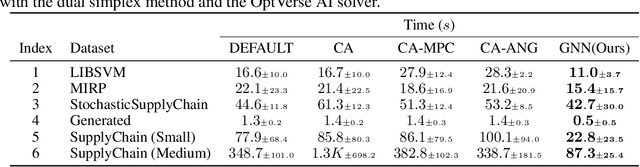
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Artificial Intelligence for Operations Research: Revolutionizing the Operations Research Process
Jan 06, 2024
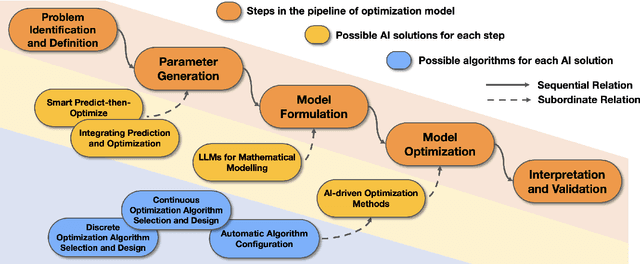
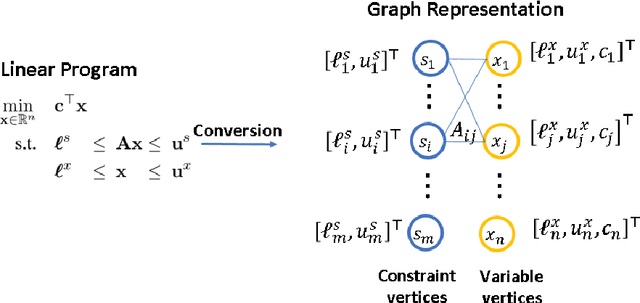
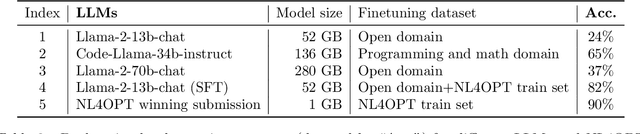
The rapid advancement of artificial intelligence (AI) techniques has opened up new opportunities to revolutionize various fields, including operations research (OR). This survey paper explores the integration of AI within the OR process (AI4OR) to enhance its effectiveness and efficiency across multiple stages, such as parameter generation, model formulation, and model optimization. By providing a comprehensive overview of the state-of-the-art and examining the potential of AI to transform OR, this paper aims to inspire further research and innovation in the development of AI-enhanced OR methods and tools. The synergy between AI and OR is poised to drive significant advancements and novel solutions in a multitude of domains, ultimately leading to more effective and efficient decision-making.
Knowledge-Injected Federated Learning
Aug 16, 2022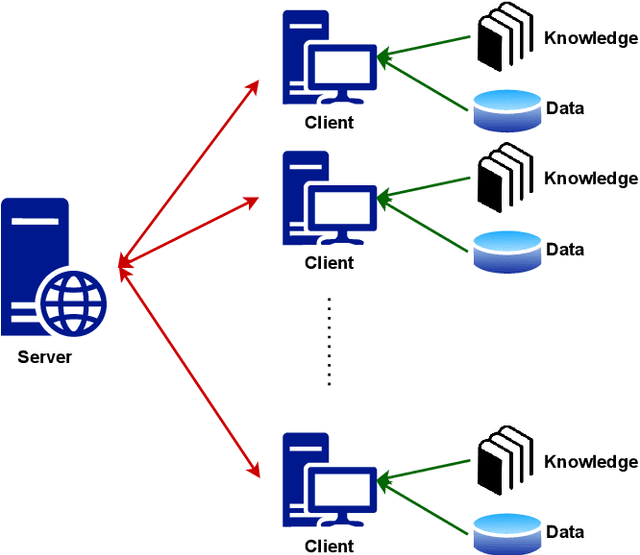

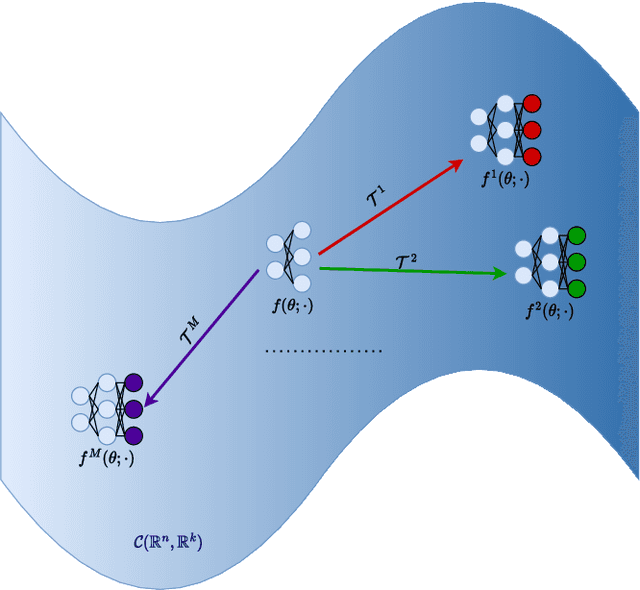
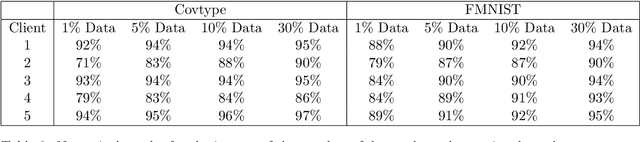
Federated learning is an emerging technique for training models from decentralized data sets. In many applications, data owners participating in the federated learning system hold not only the data but also a set of domain knowledge. Such knowledge includes human know-how and craftsmanship that can be extremely helpful to the federated learning task. In this work, we propose a federated learning framework that allows the injection of participants' domain knowledge, where the key idea is to refine the global model with knowledge locally. The scenario we consider is motivated by a real industry-level application, and we demonstrate the effectiveness of our approach to this application.
A dual approach for federated learning
Feb 04, 2022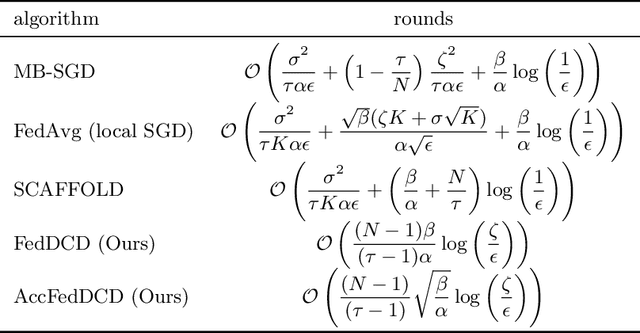
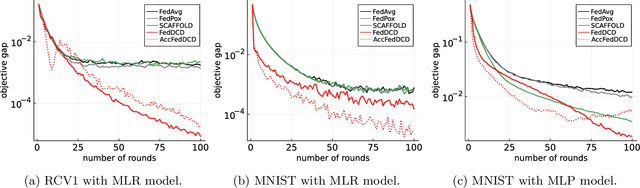
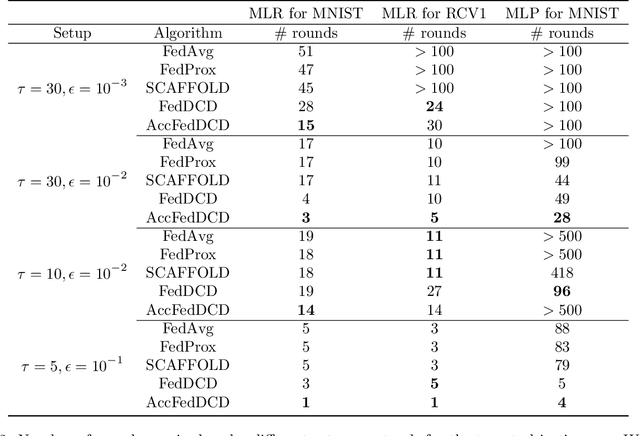
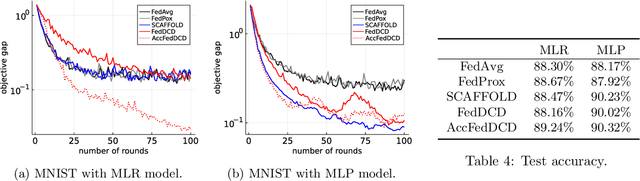
We study the federated optimization problem from a dual perspective and propose a new algorithm termed federated dual coordinate descent (FedDCD), which is based on a type of coordinate descent method developed by Necora et al.[Journal of Optimization Theory and Applications, 2017]. Additionally, we enhance the FedDCD method with inexact gradient oracles and Nesterov's acceleration. We demonstrate theoretically that our proposed approach achieves better convergence rates than the state-of-the-art primal federated optimization algorithms under certain situations. Numerical experiments on real-world datasets support our analysis.