 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich English Do LLMs Prefer? Triangulating Structural Bias Towards American English in Foundation Models
Apr 05, 2026Large language models (LLMs) are increasingly deployed in high-stakes domains, yet they expose only limited language settings, most notably "English (US)," despite the global diversity and colonial history of English. Through a postcolonial framing to explain the broader significance, we investigate how geopolitical histories of data curation, digital dominance, and linguistic standardization shape the LLM development pipeline. Focusing on two dominant standard varieties, American English (AmE) and British English (BrE), we construct a curated corpus of 1,813 AmE--BrE variants and introduce DiAlign, a dynamic, training-free method for estimating dialectal alignment using distributional evidence. We operationalize structural bias by triangulating evidence across three stages: (i) audits of six major pretraining corpora reveal systematic skew toward AmE, (ii) tokenizer analyses show that BrE forms incur higher segmentation costs, and (iii) generative evaluations show a persistent AmE preference in model outputs. To our knowledge, this is the first systematic and multi-faceted examination of dialectal asymmetries in standard English varieties across the phases of LLM development. We find that contemporary LLMs privilege AmE as the de facto norm, raising concerns about linguistic homogenization, epistemic injustice, and inequity in global AI deployment, while motivating practical steps toward more dialectally inclusive language technologies.
Rethinking Schema Linking: A Context-Aware Bidirectional Retrieval Approach for Text-to-SQL
Oct 16, 2025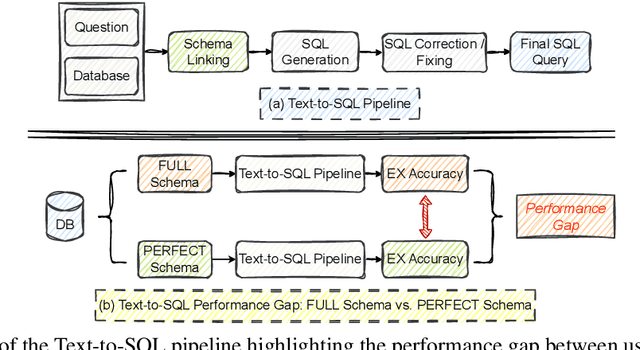
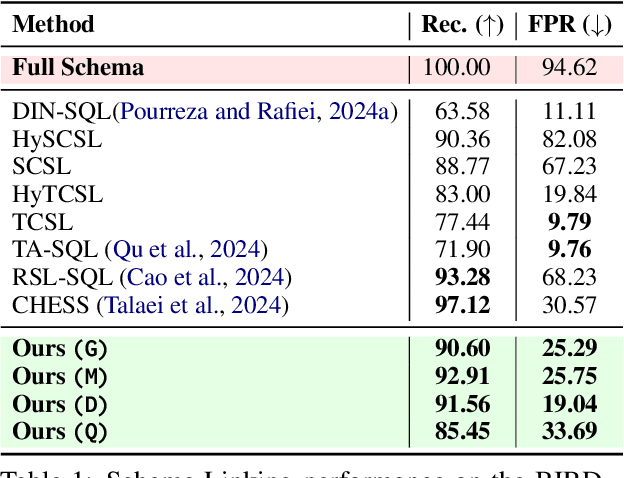
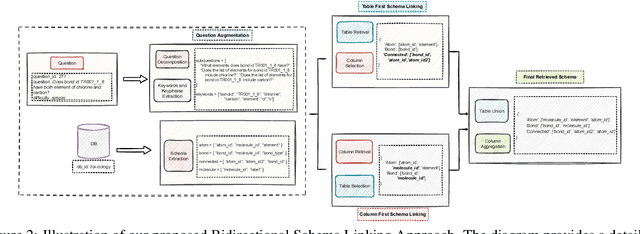
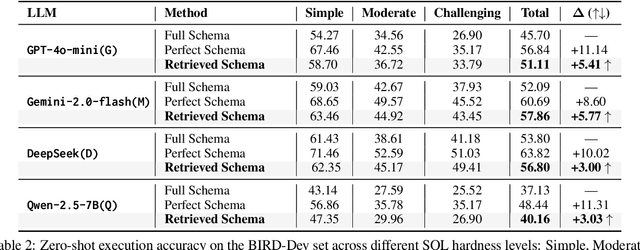
Schema linking -- the process of aligning natural language questions with database schema elements -- is a critical yet underexplored component of Text-to-SQL systems. While recent methods have focused primarily on improving SQL generation, they often neglect the retrieval of relevant schema elements, which can lead to hallucinations and execution failures. In this work, we propose a context-aware bidirectional schema retrieval framework that treats schema linking as a standalone problem. Our approach combines two complementary strategies: table-first retrieval followed by column selection, and column-first retrieval followed by table selection. It is further augmented with techniques such as question decomposition, keyword extraction, and keyphrase extraction. Through comprehensive evaluations on challenging benchmarks such as BIRD and Spider, we demonstrate that our method significantly improves schema recall while reducing false positives. Moreover, SQL generation using our retrieved schema consistently outperforms full-schema baselines and closely approaches oracle performance, all without requiring query refinement. Notably, our method narrows the performance gap between full and perfect schema settings by 50\%. Our findings highlight schema linking as a powerful lever for enhancing Text-to-SQL accuracy and efficiency.
PRISM: Agentic Retrieval with LLMs for Multi-Hop Question Answering
Oct 16, 2025Retrieval plays a central role in multi-hop question answering (QA), where answering complex questions requires gathering multiple pieces of evidence. We introduce an Agentic Retrieval System that leverages large language models (LLMs) in a structured loop to retrieve relevant evidence with high precision and recall. Our framework consists of three specialized agents: a Question Analyzer that decomposes a multi-hop question into sub-questions, a Selector that identifies the most relevant context for each sub-question (focusing on precision), and an Adder that brings in any missing evidence (focusing on recall). The iterative interaction between Selector and Adder yields a compact yet comprehensive set of supporting passages. In particular, it achieves higher retrieval accuracy while filtering out distracting content, enabling downstream QA models to surpass full-context answer accuracy while relying on significantly less irrelevant information. Experiments on four multi-hop QA benchmarks -- HotpotQA, 2WikiMultiHopQA, MuSiQue, and MultiHopRAG -- demonstrates that our approach consistently outperforms strong baselines.
Do LLMs Align with My Task? Evaluating Text-to-SQL via Dataset Alignment
Oct 06, 2025

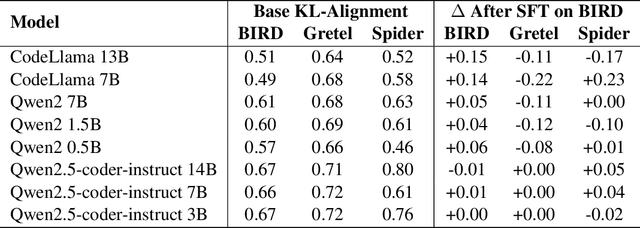

Supervised Fine-Tuning (SFT) is an effective method for adapting Large Language Models (LLMs) on downstream tasks. However, variability in training data can hinder a model's ability to generalize across domains. This paper studies the problem of dataset alignment for Natural Language to SQL (NL2SQL or text to SQL), examining how well SFT training data matches the structural characteristics of target queries and how this alignment impacts model performance. We hypothesize that alignment can be accurately estimated by comparing the distributions of structural SQL features across the training set, target data, and the model's predictions prior to SFT. Through comprehensive experiments on three large cross-domain NL2SQL benchmarks and multiple model families, we show that structural alignment is a strong predictor of fine-tuning success. When alignment is high, SFT yields substantial gains in accuracy and SQL generation quality; when alignment is low, improvements are marginal or absent. These findings highlight the importance of alignment-aware data selection for effective fine-tuning and generalization in NL2SQL tasks.
SurveyGen: Quality-Aware Scientific Survey Generation with Large Language Models
Aug 25, 2025Automatic survey generation has emerged as a key task in scientific document processing. While large language models (LLMs) have shown promise in generating survey texts, the lack of standardized evaluation datasets critically hampers rigorous assessment of their performance against human-written surveys. In this work, we present SurveyGen, a large-scale dataset comprising over 4,200 human-written surveys across diverse scientific domains, along with 242,143 cited references and extensive quality-related metadata for both the surveys and the cited papers. Leveraging this resource, we build QUAL-SG, a novel quality-aware framework for survey generation that enhances the standard Retrieval-Augmented Generation (RAG) pipeline by incorporating quality-aware indicators into literature retrieval to assess and select higher-quality source papers. Using this dataset and framework, we systematically evaluate state-of-the-art LLMs under varying levels of human involvement - from fully automatic generation to human-guided writing. Experimental results and human evaluations show that while semi-automatic pipelines can achieve partially competitive outcomes, fully automatic survey generation still suffers from low citation quality and limited critical analysis.
LongRecall: A Structured Approach for Robust Recall Evaluation in Long-Form Text
Aug 20, 2025LongRecall. The completeness of machine-generated text, ensuring that it captures all relevant information, is crucial in domains such as medicine and law and in tasks like list-based question answering (QA), where omissions can have serious consequences. However, existing recall metrics often depend on lexical overlap, leading to errors with unsubstantiated entities and paraphrased answers, while LLM-as-a-Judge methods with long holistic prompts capture broader semantics but remain prone to misalignment and hallucinations without structured verification. We introduce LongRecall, a general three-stage recall evaluation framework that decomposes answers into self-contained facts, successively narrows plausible candidate matches through lexical and semantic filtering, and verifies their alignment through structured entailment checks. This design reduces false positives and false negatives while accommodating diverse phrasings and contextual variations, serving as a foundational building block for systematic recall assessment. We evaluate LongRecall on three challenging long-form QA benchmarks using both human annotations and LLM-based judges, demonstrating substantial improvements in recall accuracy over strong lexical and LLM-as-a-Judge baselines.
SQL-Exchange: Transforming SQL Queries Across Domains
Aug 09, 2025We introduce SQL-Exchange, a framework for mapping SQL queries across different database schemas by preserving the source query structure while adapting domain-specific elements to align with the target schema. We investigate the conditions under which such mappings are feasible and beneficial, and examine their impact on enhancing the in-context learning performance of text-to-SQL systems as a downstream task. Our comprehensive evaluation across multiple model families and benchmark datasets--assessing structural alignment with source queries, execution validity on target databases, and semantic correctness--demonstrates that SQL-Exchange is effective across a wide range of schemas and query types. Our results further show that using mapped queries as in-context examples consistently improves text-to-SQL performance over using queries from the source schema.
eC-Tab2Text: Aspect-Based Text Generation from e-Commerce Product Tables
Feb 20, 2025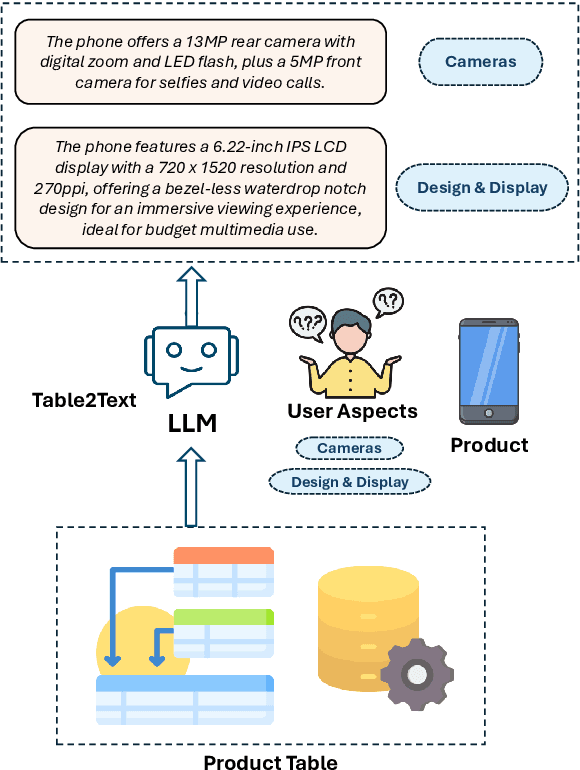
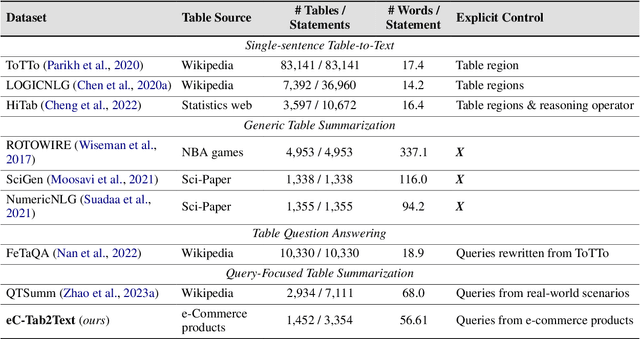

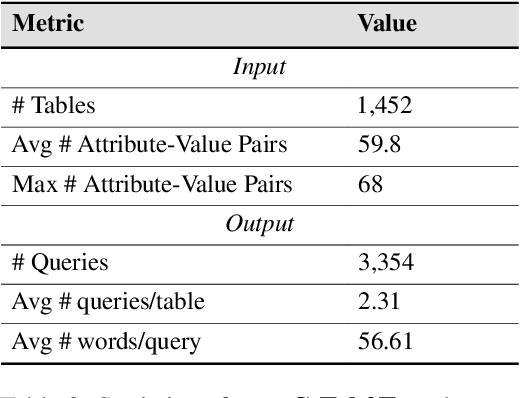
Large Language Models (LLMs) have demonstrated exceptional versatility across diverse domains, yet their application in e-commerce remains underexplored due to a lack of domain-specific datasets. To address this gap, we introduce eC-Tab2Text, a novel dataset designed to capture the intricacies of e-commerce, including detailed product attributes and user-specific queries. Leveraging eC-Tab2Text, we focus on text generation from product tables, enabling LLMs to produce high-quality, attribute-specific product reviews from structured tabular data. Fine-tuned models were rigorously evaluated using standard Table2Text metrics, alongside correctness, faithfulness, and fluency assessments. Our results demonstrate substantial improvements in generating contextually accurate reviews, highlighting the transformative potential of tailored datasets and fine-tuning methodologies in optimizing e-commerce workflows. This work highlights the potential of LLMs in e-commerce workflows and the essential role of domain-specific datasets in tailoring them to industry-specific challenges.
TabulaX: Leveraging Large Language Models for Multi-Class Table Transformations
Nov 26, 2024The integration of tabular data from diverse sources is often hindered by inconsistencies in formatting and representation, posing significant challenges for data analysts and personal digital assistants. Existing methods for automating tabular data transformations are limited in scope, often focusing on specific types of transformations or lacking interpretability. In this paper, we introduce TabulaX, a novel framework that leverages Large Language Models (LLMs) for multi-class tabular transformations. TabulaX first classifies input tables into four transformation classes (string-based, numerical, algorithmic, and general) and then applies tailored methods to generate human-interpretable transformation functions, such as numeric formulas or programming code. This approach enhances transparency and allows users to understand and modify the mappings. Through extensive experiments on real-world datasets from various domains, we demonstrate that TabulaX outperforms existing state-of-the-art approaches in terms of accuracy, supports a broader class of transformations, and generates interpretable transformations that can be efficiently applied.
LFOSum: Summarizing Long-form Opinions with Large Language Models
Oct 16, 2024Online reviews play a pivotal role in influencing consumer decisions across various domains, from purchasing products to selecting hotels or restaurants. However, the sheer volume of reviews -- often containing repetitive or irrelevant content -- leads to information overload, making it challenging for users to extract meaningful insights. Traditional opinion summarization models face challenges in handling long inputs and large volumes of reviews, while newer Large Language Model (LLM) approaches often fail to generate accurate and faithful summaries. To address those challenges, this paper introduces (1) a new dataset of long-form user reviews, each entity comprising over a thousand reviews, (2) two training-free LLM-based summarization approaches that scale to long inputs, and (3) automatic evaluation metrics. Our dataset of user reviews is paired with in-depth and unbiased critical summaries by domain experts, serving as a reference for evaluation. Additionally, our novel reference-free evaluation metrics provide a more granular, context-sensitive assessment of summary faithfulness. We benchmark several open-source and closed-source LLMs using our methods. Our evaluation reveals that LLMs still face challenges in balancing sentiment and format adherence in long-form summaries, though open-source models can narrow the gap when relevant information is retrieved in a focused manner.