 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Agentic Retrieval with LLMs for Multi-Hop Question Answering
Oct 16, 2025Retrieval plays a central role in multi-hop question answering (QA), where answering complex questions requires gathering multiple pieces of evidence. We introduce an Agentic Retrieval System that leverages large language models (LLMs) in a structured loop to retrieve relevant evidence with high precision and recall. Our framework consists of three specialized agents: a Question Analyzer that decomposes a multi-hop question into sub-questions, a Selector that identifies the most relevant context for each sub-question (focusing on precision), and an Adder that brings in any missing evidence (focusing on recall). The iterative interaction between Selector and Adder yields a compact yet comprehensive set of supporting passages. In particular, it achieves higher retrieval accuracy while filtering out distracting content, enabling downstream QA models to surpass full-context answer accuracy while relying on significantly less irrelevant information. Experiments on four multi-hop QA benchmarks -- HotpotQA, 2WikiMultiHopQA, MuSiQue, and MultiHopRAG -- demonstrates that our approach consistently outperforms strong baselines.
Rethinking Schema Linking: A Context-Aware Bidirectional Retrieval Approach for Text-to-SQL
Oct 16, 2025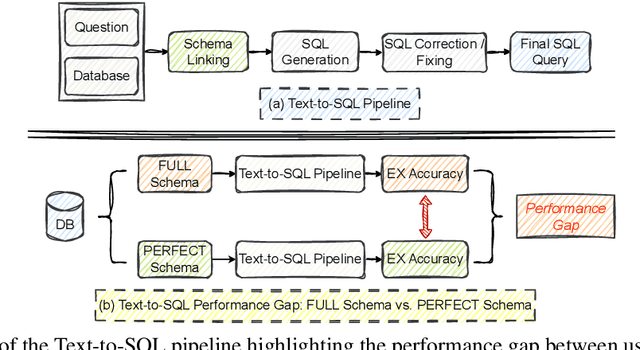
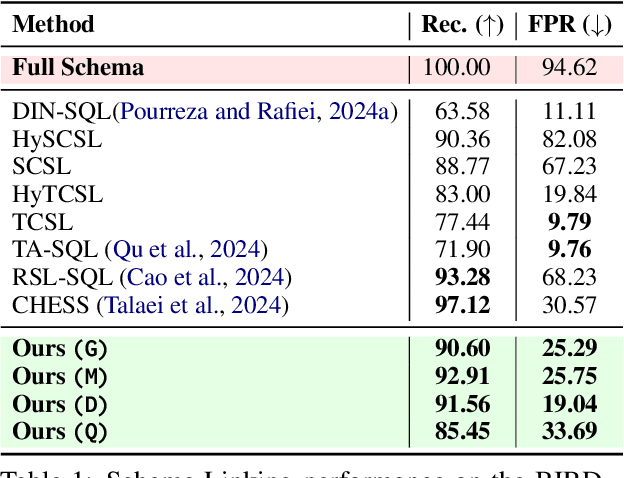
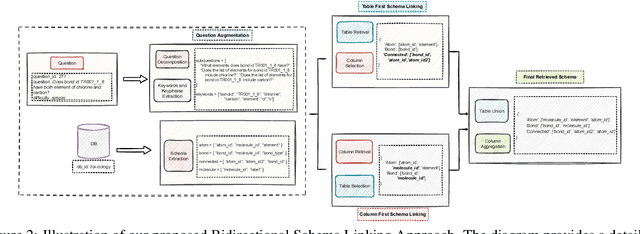
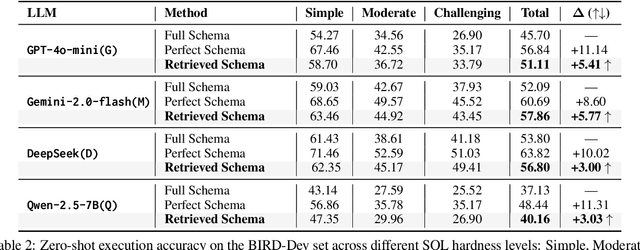
Schema linking -- the process of aligning natural language questions with database schema elements -- is a critical yet underexplored component of Text-to-SQL systems. While recent methods have focused primarily on improving SQL generation, they often neglect the retrieval of relevant schema elements, which can lead to hallucinations and execution failures. In this work, we propose a context-aware bidirectional schema retrieval framework that treats schema linking as a standalone problem. Our approach combines two complementary strategies: table-first retrieval followed by column selection, and column-first retrieval followed by table selection. It is further augmented with techniques such as question decomposition, keyword extraction, and keyphrase extraction. Through comprehensive evaluations on challenging benchmarks such as BIRD and Spider, we demonstrate that our method significantly improves schema recall while reducing false positives. Moreover, SQL generation using our retrieved schema consistently outperforms full-schema baselines and closely approaches oracle performance, all without requiring query refinement. Notably, our method narrows the performance gap between full and perfect schema settings by 50\%. Our findings highlight schema linking as a powerful lever for enhancing Text-to-SQL accuracy and efficiency.
SafeSynthDP: Leveraging Large Language Models for Privacy-Preserving Synthetic Data Generation Using Differential Privacy
Dec 30, 2024Machine learning (ML) models frequently rely on training data that may include sensitive or personal information, raising substantial privacy concerns. Legislative frameworks such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) have necessitated the development of strategies that preserve privacy while maintaining the utility of data. In this paper, we investigate the capability of Large Language Models (LLMs) to generate synthetic datasets integrated with Differential Privacy (DP) mechanisms, thereby enabling data-driven research and model training without direct exposure of sensitive information. Our approach incorporates DP-based noise injection methods, including Laplace and Gaussian distributions, into the data generation process. We then evaluate the utility of these DP-enhanced synthetic datasets by comparing the performance of ML models trained on them against models trained on the original data. To substantiate privacy guarantees, we assess the resilience of the generated synthetic data to membership inference attacks and related threats. The experimental results demonstrate that integrating DP within LLM-driven synthetic data generation offers a viable balance between privacy protection and data utility. This study provides a foundational methodology and insight into the privacy-preserving capabilities of LLMs, paving the way for compliant and effective ML research and applications.
NormTab: Improving Symbolic Reasoning in LLMs Through Tabular Data Normalization
Jun 25, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in parsing textual data and generating code. However, their performance in tasks involving tabular data, especially those requiring symbolic reasoning, faces challenges due to the structural variance and inconsistency in table cell values often found in web tables. In this paper, we introduce NormTab, a novel framework aimed at enhancing the symbolic reasoning performance of LLMs by normalizing web tables. We study table normalization as a stand-alone, one-time preprocessing step using LLMs to support symbolic reasoning on tabular data. Our experimental evaluation, conducted on challenging web table datasets such as WikiTableQuestion and TabFact, demonstrates that leveraging NormTab significantly improves symbolic reasoning performance, showcasing the importance and effectiveness of web table normalization for enhancing LLM-based symbolic reasoning tasks.
TabSQLify: Enhancing Reasoning Capabilities of LLMs Through Table Decomposition
Apr 15, 2024Table reasoning is a challenging task that requires understanding both natural language questions and structured tabular data. Large language models (LLMs) have shown impressive capabilities in natural language understanding and generation, but they often struggle with large tables due to their limited input length. In this paper, we propose TabSQLify, a novel method that leverages text-to-SQL generation to decompose tables into smaller and relevant sub-tables, containing only essential information for answering questions or verifying statements, before performing the reasoning task. In our comprehensive evaluation on four challenging datasets, our approach demonstrates comparable or superior performance compared to prevailing methods reliant on full tables as input. Moreover, our method can reduce the input context length significantly, making it more scalable and efficient for large-scale table reasoning applications. Our method performs remarkably well on the WikiTQ benchmark, achieving an accuracy of 64.7%. Additionally, on the TabFact benchmark, it achieves a high accuracy of 79.5%. These results surpass other LLM-based baseline models on gpt-3.5-turbo (chatgpt). TabSQLify can reduce the table size significantly alleviating the computational load on LLMs when handling large tables without compromising performance.
Comprehending Real Numbers: Development of Bengali Real Number Speech Corpus
Mar 27, 2018



Speech recognition has received a less attention in Bengali literature due to the lack of a comprehensive dataset. In this paper, we describe the development process of the first comprehensive Bengali speech dataset on real numbers. It comprehends all the possible words that may arise in uttering any Bengali real number. The corpus has ten speakers from the different regions of Bengali native people. It comprises of more than two thousands of speech samples in a total duration of closed to four hours. We also provide a deep analysis of our corpus, highlight some of the notable features of it, and finally evaluate the performances of two of the notable Bengali speech recognizers on it.