 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Align with My Task? Evaluating Text-to-SQL via Dataset Alignment
Oct 06, 2025

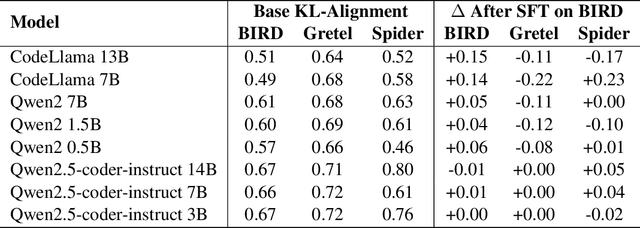

Supervised Fine-Tuning (SFT) is an effective method for adapting Large Language Models (LLMs) on downstream tasks. However, variability in training data can hinder a model's ability to generalize across domains. This paper studies the problem of dataset alignment for Natural Language to SQL (NL2SQL or text to SQL), examining how well SFT training data matches the structural characteristics of target queries and how this alignment impacts model performance. We hypothesize that alignment can be accurately estimated by comparing the distributions of structural SQL features across the training set, target data, and the model's predictions prior to SFT. Through comprehensive experiments on three large cross-domain NL2SQL benchmarks and multiple model families, we show that structural alignment is a strong predictor of fine-tuning success. When alignment is high, SFT yields substantial gains in accuracy and SQL generation quality; when alignment is low, improvements are marginal or absent. These findings highlight the importance of alignment-aware data selection for effective fine-tuning and generalization in NL2SQL tasks.
SPRINT: Enabling Interleaved Planning and Parallelized Execution in Reasoning Models
Jun 06, 2025Large reasoning models (LRMs) excel at complex reasoning tasks but typically generate lengthy sequential chains-of-thought, resulting in long inference times before arriving at the final answer. To address this challenge, we introduce SPRINT, a novel post-training and inference-time framework designed to enable LRMs to dynamically identify and exploit opportunities for parallelization during their reasoning process. SPRINT incorporates an innovative data curation pipeline that reorganizes natural language reasoning trajectories into structured rounds of long-horizon planning and parallel execution. By fine-tuning LRMs on a small amount of such curated data, the models learn to dynamically identify independent subtasks within extended reasoning processes and effectively execute them in parallel. Through extensive evaluations, we show that the models fine-tuned with the SPRINT framework match the performance of reasoning models on complex domains such as mathematics while generating up to ~39% fewer sequential tokens on problems requiring more than 8000 output tokens. Finally, we observe consistent results transferred to two out-of-distribution tasks of GPQA and Countdown with up to 45% and 65% reduction in average sequential tokens for longer reasoning trajectories, while achieving the performance of the fine-tuned reasoning model.
Review, Refine, Repeat: Understanding Iterative Decoding of AI Agents with Dynamic Evaluation and Selection
Apr 02, 2025While AI agents have shown remarkable performance at various tasks, they still struggle with complex multi-modal applications, structured generation and strategic planning. Improvements via standard fine-tuning is often impractical, as solving agentic tasks usually relies on black box API access without control over model parameters. Inference-time methods such as Best-of-N (BON) sampling offer a simple yet effective alternative to improve performance. However, BON lacks iterative feedback integration mechanism. Hence, we propose Iterative Agent Decoding (IAD) which combines iterative refinement with dynamic candidate evaluation and selection guided by a verifier. IAD differs in how feedback is designed and integrated, specifically optimized to extract maximal signal from reward scores. We conduct a detailed comparison of baselines across key metrics on Sketch2Code, Text2SQL, and Webshop where IAD consistently outperforms baselines, achieving 3--6% absolute gains on Sketch2Code and Text2SQL (with and without LLM judges) and 8--10% gains on Webshop across multiple metrics. To better understand the source of IAD's gains, we perform controlled experiments to disentangle the effect of adaptive feedback from stochastic sampling, and find that IAD's improvements are primarily driven by verifier-guided refinement, not merely sampling diversity. We also show that both IAD and BON exhibit inference-time scaling with increased compute when guided by an optimal verifier. Our analysis highlights the critical role of verifier quality in effective inference-time optimization and examines the impact of noisy and sparse rewards on scaling behavior. Together, these findings offer key insights into the trade-offs and principles of effective inference-time optimization.
Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
Apr 01, 2025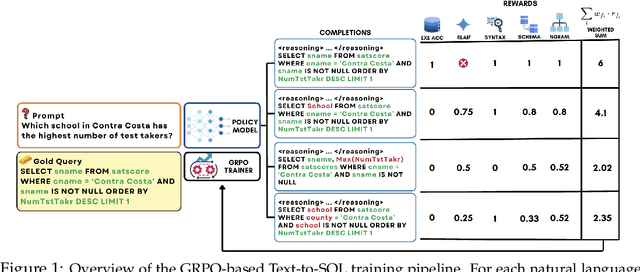
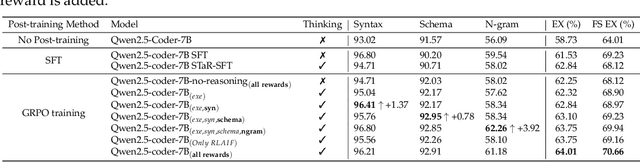
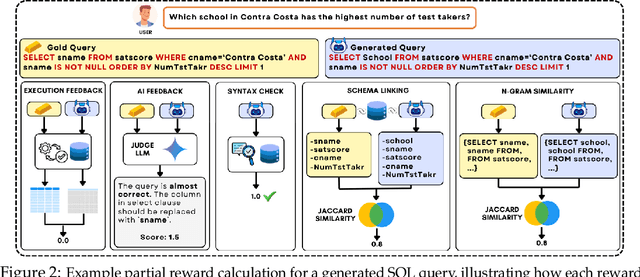
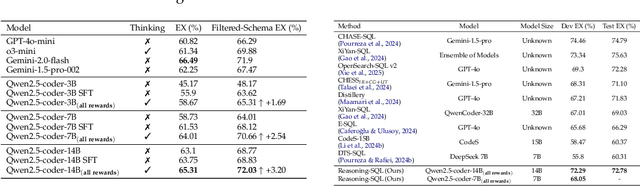
Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Oct 02, 2024



In tackling the challenges of large language model (LLM) performance for Text-to-SQL tasks, we introduce CHASE-SQL, a new framework that employs innovative strategies, using test-time compute in multi-agent modeling to improve candidate generation and selection. CHASE-SQL leverages LLMs' intrinsic knowledge to generate diverse and high-quality SQL candidates using different LLM generators with: (1) a divide-and-conquer method that decomposes complex queries into manageable sub-queries in a single LLM call; (2) chain-of-thought reasoning based on query execution plans, reflecting the steps a database engine takes during execution; and (3) a unique instance-aware synthetic example generation technique, which offers specific few-shot demonstrations tailored to test questions.To identify the best candidate, a selection agent is employed to rank the candidates through pairwise comparisons with a fine-tuned binary-candidates selection LLM. This selection approach has been demonstrated to be more robust over alternatives. The proposed generators-selector framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods. Overall, our proposed CHASE-SQL achieves the state-of-the-art execution accuracy of 73.0% and 73.01% on the test set and development set of the notable BIRD Text-to-SQL dataset benchmark, rendering CHASE-SQL the top submission of the leaderboard (at the time of paper submission).
SQL-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging
Aug 22, 2024



Text-to-SQL systems, which convert natural language queries into SQL commands, have seen significant progress primarily for the SQLite dialect. However, adapting these systems to other SQL dialects like BigQuery and PostgreSQL remains a challenge due to the diversity in SQL syntax and functions. We introduce SQL-GEN, a framework for generating high-quality dialect-specific synthetic data guided by dialect-specific tutorials, and demonstrate its effectiveness in creating training datasets for multiple dialects. Our approach significantly improves performance, by up to 20\%, over previous methods and reduces the gap with large-scale human-annotated datasets. Moreover, combining our synthetic data with human-annotated data provides additional performance boosts of 3.3\% to 5.6\%. We also introduce a novel Mixture of Experts (MoE) initialization method that integrates dialect-specific models into a unified system by merging self-attention layers and initializing the gates with dialect-specific keywords, further enhancing performance across different SQL dialects.
S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language Models
Jul 02, 2024



Deployment of autoregressive large language models (LLMs) is costly, and as these models increase in size, the associated costs will become even more considerable. Consequently, different methods have been proposed to accelerate the token generation process and reduce costs. Speculative decoding (SD) is among the most promising approaches to speed up the LLM decoding process by verifying multiple tokens in parallel and using an auxiliary smaller draft model to generate the possible tokens. In SD, usually, one draft model is used to serve a specific target model; however, in practice, LLMs are diverse, and we might need to deal with many target models or more than one target model simultaneously. In this scenario, it is not clear which draft model should be used for which target model, and searching among different draft models or training customized draft models can further increase deployment costs. In this paper, we first introduce a novel multi-target scenario for the deployment of draft models for faster inference. Then, we present a novel, more efficient sorted speculative decoding mechanism that outperforms regular baselines in multi-target settings. We evaluated our method on Spec-Bench in different settings, including base models such as Vicuna 7B, 13B, and LLama Chat 70B. Our results suggest that our draft models perform better than baselines for multiple target models at the same time.
DeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning
Jun 12, 2024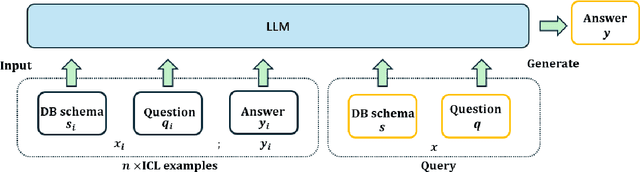

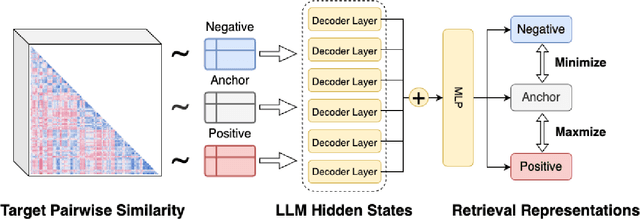

While in-context Learning (ICL) has proven to be an effective technique to improve the performance of Large Language Models (LLMs) in a variety of complex tasks, notably in translating natural language questions into Structured Query Language (NL2SQL), the question of how to select the most beneficial demonstration examples remains an open research problem. While prior works often adapted off-the-shelf encoders to retrieve examples dynamically, an inherent discrepancy exists in the representational capacities between the external retrievers and the LLMs. Further, optimizing the selection of examples is a non-trivial task, since there are no straightforward methods to assess the relative benefits of examples without performing pairwise inference. To address these shortcomings, we propose DeTriever, a novel demonstration retrieval framework that learns a weighted combination of LLM hidden states, where rich semantic information is encoded. To train the model, we propose a proxy score that estimates the relative benefits of examples based on the similarities between output queries. Experiments on two popular NL2SQL benchmarks demonstrate that our method significantly outperforms the state-of-the-art baselines on one-shot NL2SQL tasks.
CHESS: Contextual Harnessing for Efficient SQL Synthesis
May 27, 2024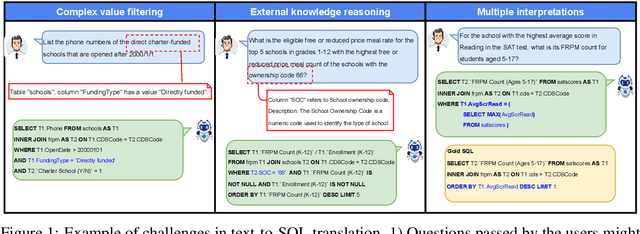
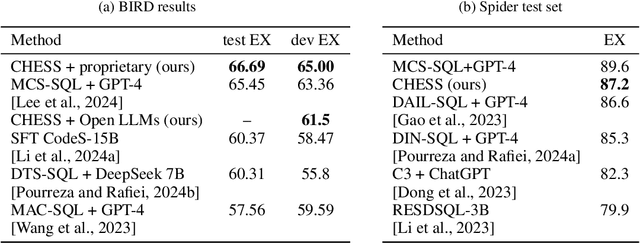
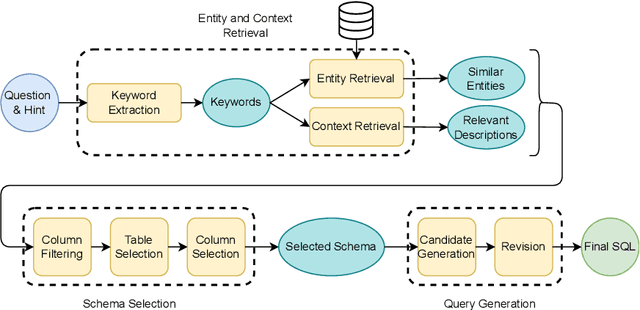

Utilizing large language models (LLMs) for transforming natural language questions into SQL queries (text-to-SQL) is a promising yet challenging approach, particularly when applied to real-world databases with complex and extensive schemas. In particular, effectively incorporating data catalogs and database values for SQL generation remains an obstacle, leading to suboptimal solutions. We address this problem by proposing a new pipeline that effectively retrieves relevant data and context, selects an efficient schema, and synthesizes correct and efficient SQL queries. To increase retrieval precision, our pipeline introduces a hierarchical retrieval method leveraging model-generated keywords, locality-sensitive hashing indexing, and vector databases. Additionally, we have developed an adaptive schema pruning technique that adjusts based on the complexity of the problem and the model's context size. Our approach generalizes to both frontier proprietary models like GPT-4 and open-source models such as Llama-3-70B. Through a series of ablation studies, we demonstrate the effectiveness of each component of our pipeline and its impact on the end-to-end performance. Our method achieves new state-of-the-art performance on the cross-domain challenging BIRD dataset.
SQL-Encoder: Improving NL2SQL In-Context Learning Through a Context-Aware Encoder
Mar 24, 2024
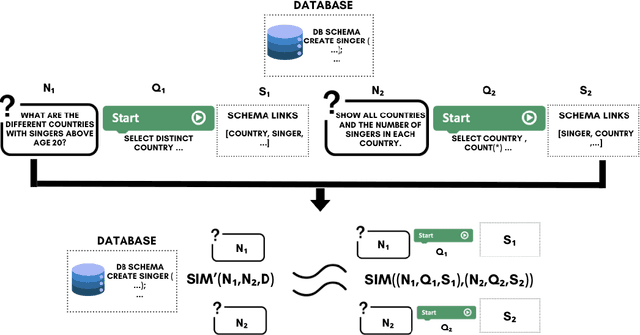
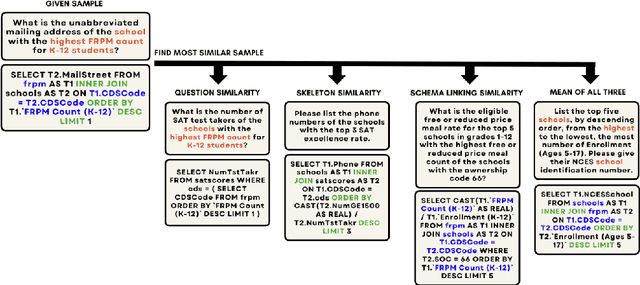

Detecting structural similarity between queries is essential for selecting examples in in-context learning models. However, assessing structural similarity based solely on the natural language expressions of queries, without considering SQL queries, presents a significant challenge. This paper explores the significance of this similarity metric and proposes a model for accurately estimating it. To achieve this, we leverage a dataset comprising 170k question pairs, meticulously curated to train a similarity prediction model. Our comprehensive evaluation demonstrates that the proposed model adeptly captures the structural similarity between questions, as evidenced by improvements in Kendall-Tau distance and precision@k metrics. Notably, our model outperforms strong competitive embedding models from OpenAI and Cohere. Furthermore, compared to these competitive models, our proposed encoder enhances the downstream performance of NL2SQL models in 1-shot in-context learning scenarios by 1-2\% for GPT-3.5-turbo, 4-8\% for CodeLlama-7B, and 2-3\% for CodeLlama-13B.