 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity And Complex Test Data Generation For Real-World SQL Code Generation Services
Apr 24, 2025



The demand for high-fidelity test data is paramount in industrial settings where access to production data is largely restricted. Traditional data generation methods often fall short, struggling with low-fidelity and the ability to model complex data structures and semantic relationships that are critical for testing complex SQL code generation services like Natural Language to SQL (NL2SQL). In this paper, we address the critical need for generating syntactically correct and semantically ``meaningful'' mock data for complex schema that includes columns with nested structures that we frequently encounter in Google SQL code generation workloads. We highlight the limitations of existing approaches used in production, particularly their inability to handle large and complex schema, as well as the lack of semantically coherent test data that lead to limited test coverage. We demonstrate that by leveraging Large Language Models (LLMs) and incorporating strategic pre- and post-processing steps, we can generate realistic high-fidelity test data that adheres to complex structural constraints and maintains semantic integrity to the test targets (SQL queries/functions). This approach supports comprehensive testing of complex SQL queries involving joins, aggregations, and even deeply nested subqueries, ensuring robust evaluation of SQL code generation services, like NL2SQL and SQL Code Assistant services. Our results demonstrate the practical utility of an out-of-the-box LLM (\textit{gemini}) based test data generation for industrial SQL code generation services where generating realistic test data is essential due to the frequent unavailability of production datasets.
Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQL
Jan 21, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities across a range of natural language processing tasks. In particular, improvements in reasoning abilities and the expansion of context windows have opened new avenues for leveraging these powerful models. NL2SQL is challenging in that the natural language question is inherently ambiguous, while the SQL generation requires a precise understanding of complex data schema and semantics. One approach to this semantic ambiguous problem is to provide more and sufficient contextual information. In this work, we explore the performance and the latency trade-offs of the extended context window (a.k.a., long context) offered by Google's state-of-the-art LLM (\textit{gemini-1.5-pro}). We study the impact of various contextual information, including column example values, question and SQL query pairs, user-provided hints, SQL documentation, and schema. To the best of our knowledge, this is the first work to study how the extended context window and extra contextual information can help NL2SQL generation with respect to both accuracy and latency cost. We show that long context LLMs are robust and do not get lost in the extended contextual information. Additionally, our long-context NL2SQL pipeline based on Google's \textit{gemini-pro-1.5} achieve a strong performance with 67.41\% on BIRD benchmark (dev) without finetuning and expensive self-consistency based techniques.
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Oct 02, 2024



In tackling the challenges of large language model (LLM) performance for Text-to-SQL tasks, we introduce CHASE-SQL, a new framework that employs innovative strategies, using test-time compute in multi-agent modeling to improve candidate generation and selection. CHASE-SQL leverages LLMs' intrinsic knowledge to generate diverse and high-quality SQL candidates using different LLM generators with: (1) a divide-and-conquer method that decomposes complex queries into manageable sub-queries in a single LLM call; (2) chain-of-thought reasoning based on query execution plans, reflecting the steps a database engine takes during execution; and (3) a unique instance-aware synthetic example generation technique, which offers specific few-shot demonstrations tailored to test questions.To identify the best candidate, a selection agent is employed to rank the candidates through pairwise comparisons with a fine-tuned binary-candidates selection LLM. This selection approach has been demonstrated to be more robust over alternatives. The proposed generators-selector framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods. Overall, our proposed CHASE-SQL achieves the state-of-the-art execution accuracy of 73.0% and 73.01% on the test set and development set of the notable BIRD Text-to-SQL dataset benchmark, rendering CHASE-SQL the top submission of the leaderboard (at the time of paper submission).
Unknown Examples & Machine Learning Model Generalization
Aug 24, 2018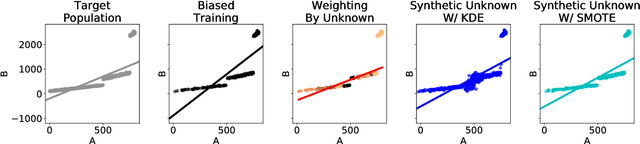
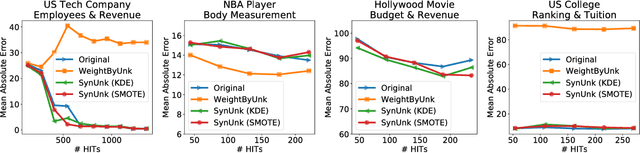
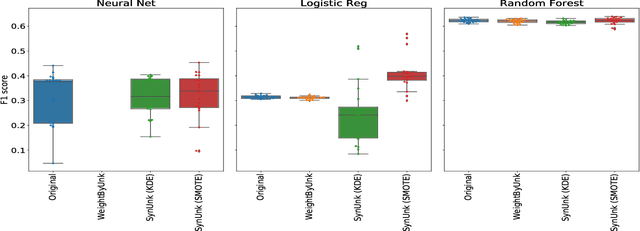
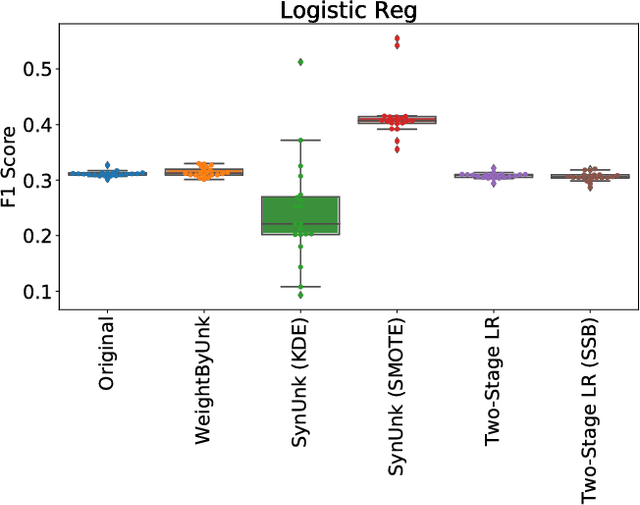
Over the past decades, researchers and ML practitioners have come up with better and better ways to build, understand and improve the quality of ML models, but mostly under the key assumption that the training data is distributed identically to the testing data. In many real-world applications, however, some potential training examples are unknown to the modeler, due to sample selection bias or, more generally, covariate shift, i.e., a distribution shift between the training and deployment stage. The resulting discrepancy between training and testing distributions leads to poor generalization performance of the ML model and hence biased predictions. We provide novel algorithms that estimate the number and properties of these unknown training examples---unknown unknowns. This information can then be used to correct the training set, prior to seeing any test data. The key idea is to combine species-estimation techniques with data-driven methods for estimating the feature values for the unknown unknowns. Experiments on a variety of ML models and datasets indicate that taking the unknown examples into account can yield a more robust ML model that generalizes better.
Slice Finder: Automated Data Slicing for Model Validation
Aug 01, 2018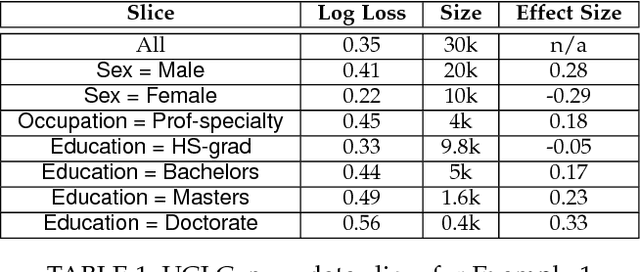
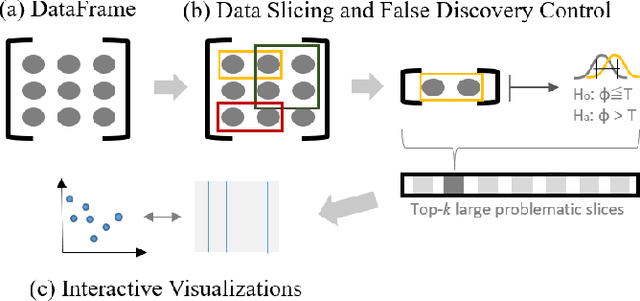

As machine learning (ML) systems become democratized, it becomes increasingly important to help users easily debug their models. However, current data tools are still primitive when it comes to helping users trace model performance problems all the way to the data. We focus on the particular problem of slicing data to identify subsets of the validation data where the model performs poorly. This is an important problem in model validation because the overall model performance can fail to reflect that of the smaller subsets, and slicing allows users to analyze the model performance on a more granular-level. Unlike general techniques (e.g., clustering) that can find arbitrary slices, our goal is to find interpretable slices (which are easier to take action compared to arbitrary subsets) that are problematic and large. We propose Slice Finder, which is an interactive framework for identifying such slices using statistical techniques. Applications include diagnosing model fairness and fraud detection, where identifying slices that are interpretable to humans is crucial.
A Behavior Analysis-Based Game Bot Detection Approach Considering Various Play Styles
Sep 08, 2015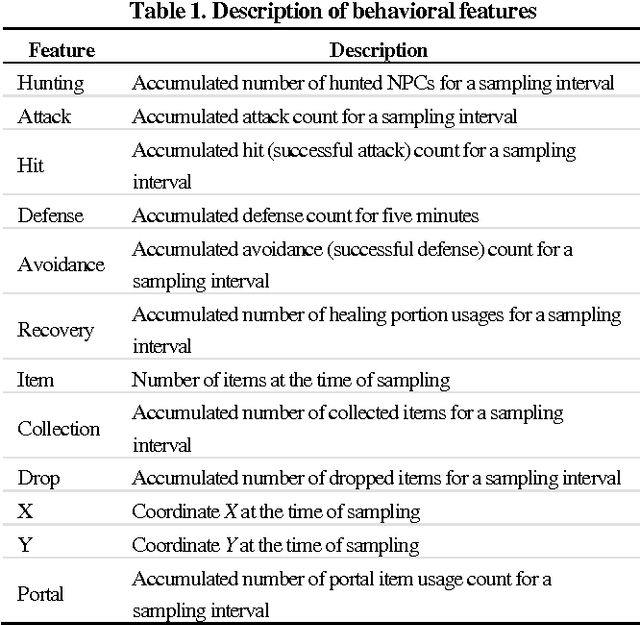
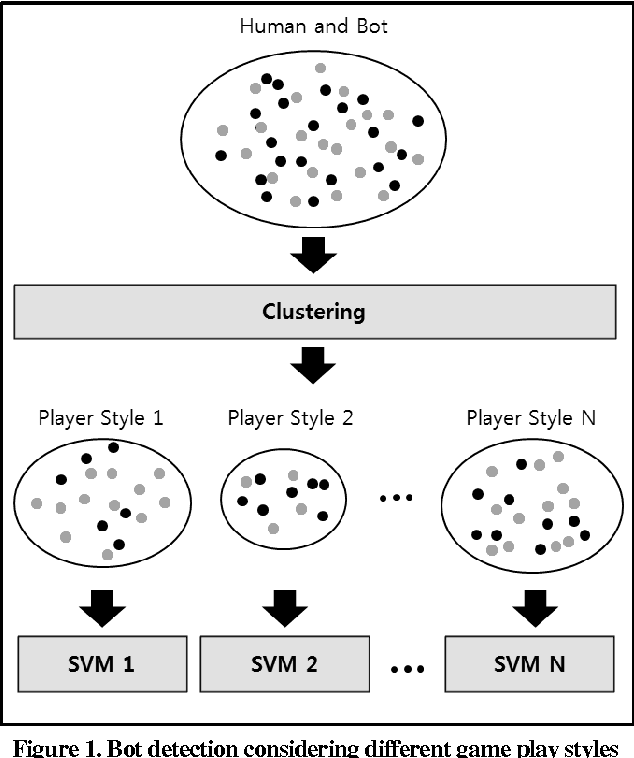
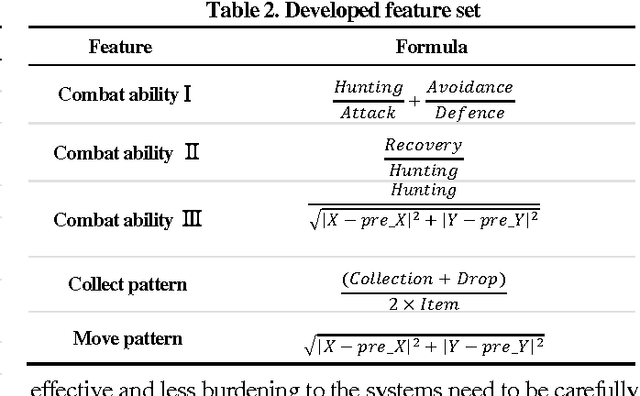
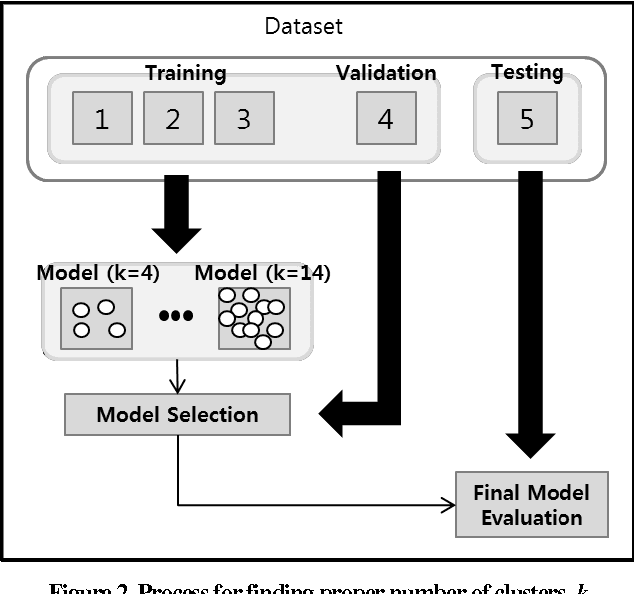
An approach for game bot detection in MMORPGs is proposed based on the analysis of game playing behavior. Since MMORPGs are large scale games, users can play in various ways. This variety in playing behavior makes it hard to detect game bots based on play behaviors. In order to cope with this problem, the proposed approach observes game playing behaviors of users and groups them by their behavioral similarities. Then, it develops a local bot detection model for each player group. Since the locally optimized models can more accurately detect game bots within each player group, the combination of those models brings about overall improvement. For a practical purpose of reducing the workloads of the game servers in service, the game data is collected at a low resolution in time. Behavioral features are selected and developed to accurately detect game bots with the low resolution data, considering common aspects of MMORPG playing. Through the experiment with the real data from a game currently in service, it is shown that the proposed local model approach yields more accurate results.