 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnknown Examples & Machine Learning Model Generalization
Paper and Code
Aug 24, 2018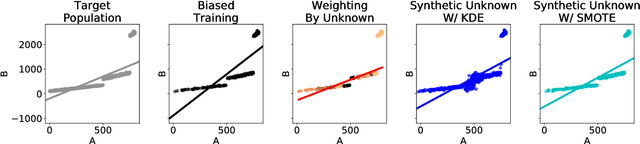
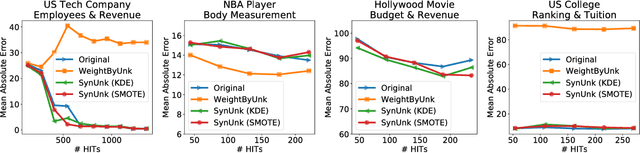
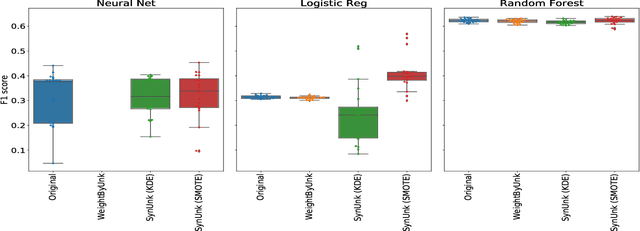
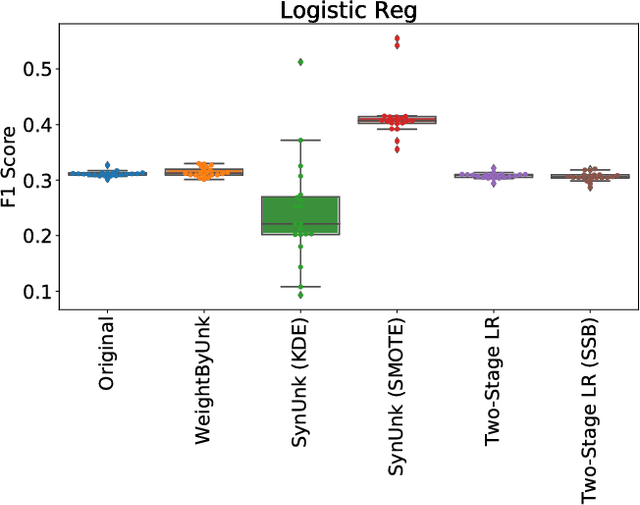
Over the past decades, researchers and ML practitioners have come up with better and better ways to build, understand and improve the quality of ML models, but mostly under the key assumption that the training data is distributed identically to the testing data. In many real-world applications, however, some potential training examples are unknown to the modeler, due to sample selection bias or, more generally, covariate shift, i.e., a distribution shift between the training and deployment stage. The resulting discrepancy between training and testing distributions leads to poor generalization performance of the ML model and hence biased predictions. We provide novel algorithms that estimate the number and properties of these unknown training examples---unknown unknowns. This information can then be used to correct the training set, prior to seeing any test data. The key idea is to combine species-estimation techniques with data-driven methods for estimating the feature values for the unknown unknowns. Experiments on a variety of ML models and datasets indicate that taking the unknown examples into account can yield a more robust ML model that generalizes better.