 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Decision Making via Interactive What-If Analysis
Sep 21, 2021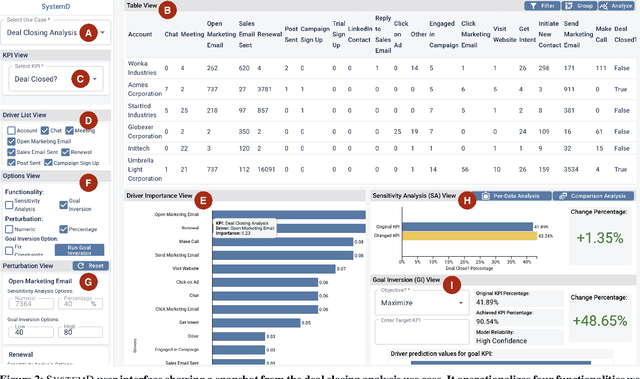

The fundamental goal of business data analysis is to improve business decisions using data. Business users such as sales, marketing, product, or operations managers often make decisions to achieve key performance indicator (KPI) goals such as increasing customer retention, decreasing cost, and increasing sales. To discover the relationship between data attributes hypothesized to be drivers and those corresponding to KPIs of interest, business users currently need to perform lengthy exploratory analyses, considering multitudes of combinations and scenarios, slicing, dicing, and transforming the data accordingly. For example, analyzing customer retention across quarters of the year or suggesting optimal media channels across strata of customers. However, the increasing complexity of datasets combined with the cognitive limitations of humans makes it challenging to carry over multiple hypotheses, even for simple datasets. Therefore mentally performing such analyses is hard. Existing commercial tools either provide partial solutions whose effectiveness remains unclear or fail to cater to business users. Here we argue for four functionalities that we believe are necessary to enable business users to interactively learn and reason about the relationships (functions) between sets of data attributes, facilitating data-driven decision making. We implement these functionalities in SystemD, an interactive visual analysis system enabling business users to experiment with the data by asking what-if questions. We evaluate the system through three business use cases: marketing mix modeling analysis, customer retention analysis, and deal closing analysis, and report on feedback from multiple business users. Overall, business users find SystemD intuitive and useful for quick testing and validation of their hypotheses around interested KPI as well as in making effective and fast data-driven decisions.
Temporally-Biased Sampling Schemes for Online Model Management
Jun 11, 2019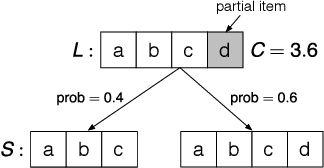
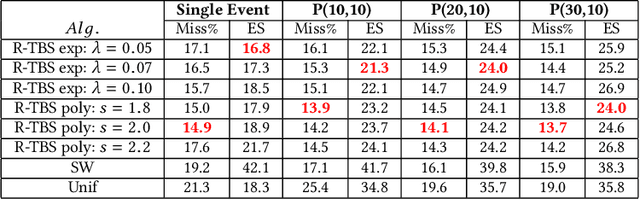
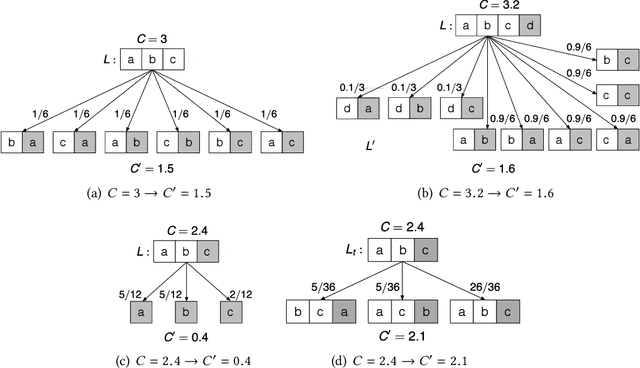
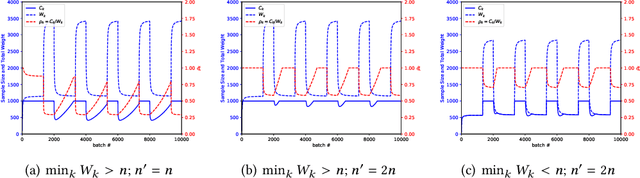
To maintain the accuracy of supervised learning models in the presence of evolving data streams, we provide temporally-biased sampling schemes that weight recent data most heavily, with inclusion probabilities for a given data item decaying over time according to a specified "decay function". We then periodically retrain the models on the current sample. This approach speeds up the training process relative to training on all of the data. Moreover, time-biasing lets the models adapt to recent changes in the data while---unlike in a sliding-window approach---still keeping some old data to ensure robustness in the face of temporary fluctuations and periodicities in the data values. In addition, the sampling-based approach allows existing analytic algorithms for static data to be applied to dynamic streaming data essentially without change. We provide and analyze both a simple sampling scheme (T-TBS) that probabilistically maintains a target sample size and a novel reservoir-based scheme (R-TBS) that is the first to provide both control over the decay rate and a guaranteed upper bound on the sample size. If the decay function is exponential, then control over the decay rate is complete, and R-TBS maximizes both expected sample size and sample-size stability. For general decay functions, the actual item inclusion probabilities can be made arbitrarily close to the nominal probabilities, and we provide a scheme that allows a trade-off between sample footprint and sample-size stability. The R-TBS and T-TBS schemes are of independent interest, extending the known set of unequal-probability sampling schemes. We discuss distributed implementation strategies; experiments in Spark illuminate the performance and scalability of the algorithms, and show that our approach can increase machine learning robustness in the face of evolving data.
Unknown Examples & Machine Learning Model Generalization
Aug 24, 2018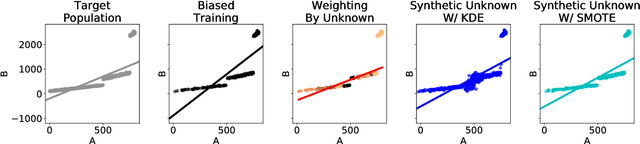
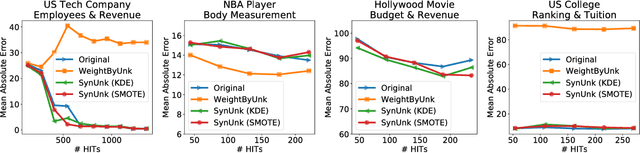
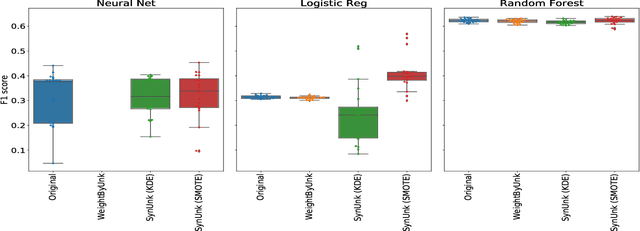
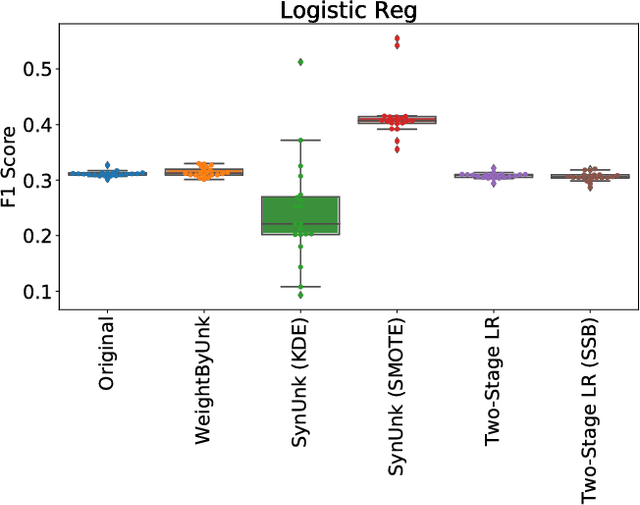
Over the past decades, researchers and ML practitioners have come up with better and better ways to build, understand and improve the quality of ML models, but mostly under the key assumption that the training data is distributed identically to the testing data. In many real-world applications, however, some potential training examples are unknown to the modeler, due to sample selection bias or, more generally, covariate shift, i.e., a distribution shift between the training and deployment stage. The resulting discrepancy between training and testing distributions leads to poor generalization performance of the ML model and hence biased predictions. We provide novel algorithms that estimate the number and properties of these unknown training examples---unknown unknowns. This information can then be used to correct the training set, prior to seeing any test data. The key idea is to combine species-estimation techniques with data-driven methods for estimating the feature values for the unknown unknowns. Experiments on a variety of ML models and datasets indicate that taking the unknown examples into account can yield a more robust ML model that generalizes better.