 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally-Biased Sampling Schemes for Online Model Management
Paper and Code
Jun 11, 2019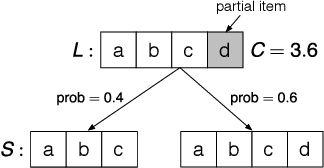
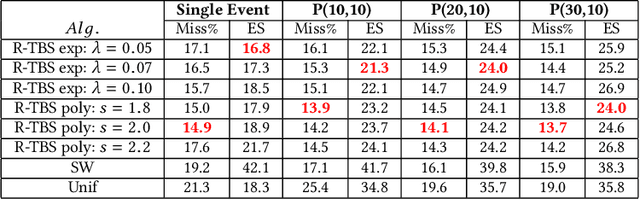
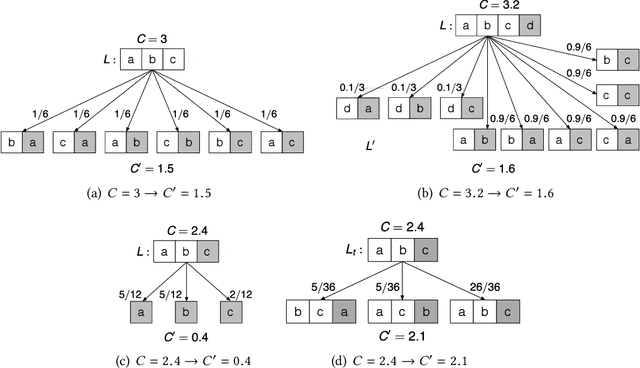
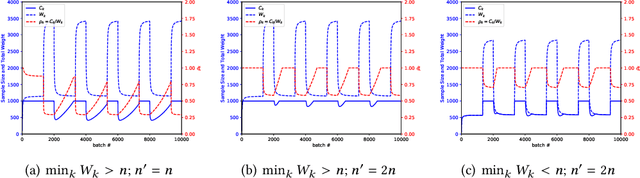
To maintain the accuracy of supervised learning models in the presence of evolving data streams, we provide temporally-biased sampling schemes that weight recent data most heavily, with inclusion probabilities for a given data item decaying over time according to a specified "decay function". We then periodically retrain the models on the current sample. This approach speeds up the training process relative to training on all of the data. Moreover, time-biasing lets the models adapt to recent changes in the data while---unlike in a sliding-window approach---still keeping some old data to ensure robustness in the face of temporary fluctuations and periodicities in the data values. In addition, the sampling-based approach allows existing analytic algorithms for static data to be applied to dynamic streaming data essentially without change. We provide and analyze both a simple sampling scheme (T-TBS) that probabilistically maintains a target sample size and a novel reservoir-based scheme (R-TBS) that is the first to provide both control over the decay rate and a guaranteed upper bound on the sample size. If the decay function is exponential, then control over the decay rate is complete, and R-TBS maximizes both expected sample size and sample-size stability. For general decay functions, the actual item inclusion probabilities can be made arbitrarily close to the nominal probabilities, and we provide a scheme that allows a trade-off between sample footprint and sample-size stability. The R-TBS and T-TBS schemes are of independent interest, extending the known set of unequal-probability sampling schemes. We discuss distributed implementation strategies; experiments in Spark illuminate the performance and scalability of the algorithms, and show that our approach can increase machine learning robustness in the face of evolving data.