 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum repeaters enhanced by vacuum beam guides
Apr 22, 2025The development of large-scale quantum communication networks faces critical challenges due to photon loss and decoherence in optical fiber channels. These fundamentally limit transmission distances and demand dense networks of repeater stations. This work investigates using vacuum beam guides (VBGs)-a promising ultra-low-loss transmission platform-as an alternative to traditional fiber links. By incorporating VBGs into repeater-based architectures, we demonstrate that the inter-repeater spacing can be substantially extended, resulting in fewer required nodes and significantly reducing hardware and operational complexity. We perform a cost-function analysis to quantify performance trade-offs across first, second, and third-generation repeaters. Our results show that first-generation repeaters reduce costs dramatically by eliminating entanglement purification. Third-generation repeaters benefit from improved link transmission success, which is crucial for quantum error correction. In contrast, second-generation repeaters exhibit a more nuanced response; although transmission loss is reduced, their performance remains primarily limited by logical gate errors rather than channel loss. These findings highlight that while all repeater generations benefit from reduced photon loss, the magnitude of improvement depends critically on the underlying error mechanisms. Vacuum beam guides thus emerge as a powerful enabler for scalable, high-performance quantum networks, particularly in conjunction with near-term quantum hardware capabilities.
Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQL
Jan 21, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities across a range of natural language processing tasks. In particular, improvements in reasoning abilities and the expansion of context windows have opened new avenues for leveraging these powerful models. NL2SQL is challenging in that the natural language question is inherently ambiguous, while the SQL generation requires a precise understanding of complex data schema and semantics. One approach to this semantic ambiguous problem is to provide more and sufficient contextual information. In this work, we explore the performance and the latency trade-offs of the extended context window (a.k.a., long context) offered by Google's state-of-the-art LLM (\textit{gemini-1.5-pro}). We study the impact of various contextual information, including column example values, question and SQL query pairs, user-provided hints, SQL documentation, and schema. To the best of our knowledge, this is the first work to study how the extended context window and extra contextual information can help NL2SQL generation with respect to both accuracy and latency cost. We show that long context LLMs are robust and do not get lost in the extended contextual information. Additionally, our long-context NL2SQL pipeline based on Google's \textit{gemini-pro-1.5} achieve a strong performance with 67.41\% on BIRD benchmark (dev) without finetuning and expensive self-consistency based techniques.
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Oct 02, 2024



In tackling the challenges of large language model (LLM) performance for Text-to-SQL tasks, we introduce CHASE-SQL, a new framework that employs innovative strategies, using test-time compute in multi-agent modeling to improve candidate generation and selection. CHASE-SQL leverages LLMs' intrinsic knowledge to generate diverse and high-quality SQL candidates using different LLM generators with: (1) a divide-and-conquer method that decomposes complex queries into manageable sub-queries in a single LLM call; (2) chain-of-thought reasoning based on query execution plans, reflecting the steps a database engine takes during execution; and (3) a unique instance-aware synthetic example generation technique, which offers specific few-shot demonstrations tailored to test questions.To identify the best candidate, a selection agent is employed to rank the candidates through pairwise comparisons with a fine-tuned binary-candidates selection LLM. This selection approach has been demonstrated to be more robust over alternatives. The proposed generators-selector framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods. Overall, our proposed CHASE-SQL achieves the state-of-the-art execution accuracy of 73.0% and 73.01% on the test set and development set of the notable BIRD Text-to-SQL dataset benchmark, rendering CHASE-SQL the top submission of the leaderboard (at the time of paper submission).
Enhancing Screen Time Identification in Children with a Multi-View Vision Language Model and Screen Time Tracker
Oct 02, 2024



Being able to accurately monitor the screen exposure of young children is important for research on phenomena linked to screen use such as childhood obesity, physical activity, and social interaction. Most existing studies rely upon self-report or manual measures from bulky wearable sensors, thus lacking efficiency and accuracy in capturing quantitative screen exposure data. In this work, we developed a novel sensor informatics framework that utilizes egocentric images from a wearable sensor, termed the screen time tracker (STT), and a vision language model (VLM). In particular, we devised a multi-view VLM that takes multiple views from egocentric image sequences and interprets screen exposure dynamically. We validated our approach by using a dataset of children's free-living activities, demonstrating significant improvement over existing methods in plain vision language models and object detection models. Results supported the promise of this monitoring approach, which could optimize behavioral research on screen exposure in children's naturalistic settings.
A Two-Stage Proactive Dialogue Generator for Efficient Clinical Information Collection Using Large Language Model
Oct 02, 2024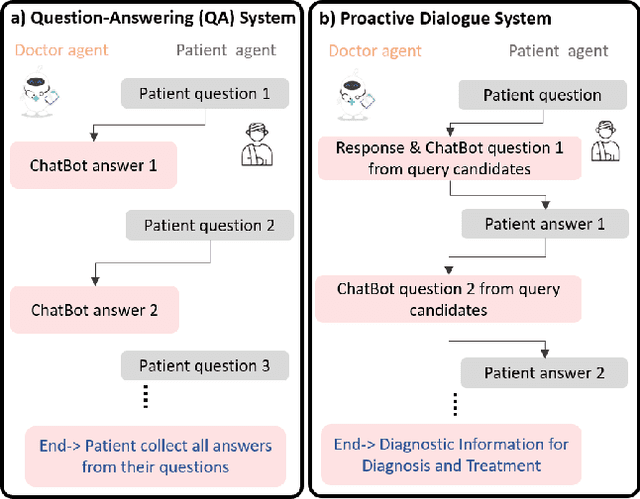

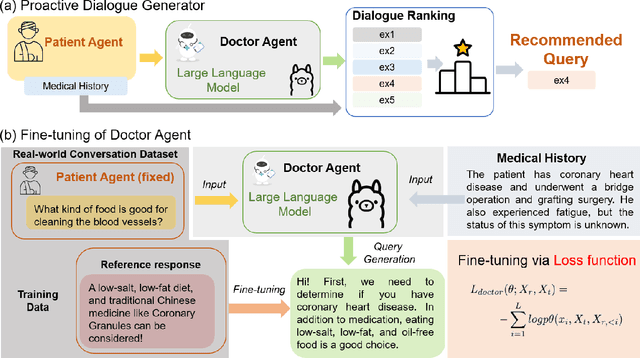

Efficient patient-doctor interaction is among the key factors for a successful disease diagnosis. During the conversation, the doctor could query complementary diagnostic information, such as the patient's symptoms, previous surgery, and other related information that goes beyond medical evidence data (test results) to enhance disease diagnosis. However, this procedure is usually time-consuming and less-efficient, which can be potentially optimized through computer-assisted systems. As such, we propose a diagnostic dialogue system to automate the patient information collection procedure. By exploiting medical history and conversation logic, our conversation agents, particularly the doctor agent, can pose multi-round clinical queries to effectively collect the most relevant disease diagnostic information. Moreover, benefiting from our two-stage recommendation structure, carefully designed ranking criteria, and interactive patient agent, our model is able to overcome the under-exploration and non-flexible challenges in dialogue generation. Our experimental results on a real-world medical conversation dataset show that our model can generate clinical queries that mimic the conversation style of real doctors, with efficient fluency, professionalism, and safety, while effectively collecting relevant disease diagnostic information.
CardBench: A Benchmark for Learned Cardinality Estimation in Relational Databases
Aug 28, 2024Cardinality estimation is crucial for enabling high query performance in relational databases. Recently learned cardinality estimation models have been proposed to improve accuracy but there is no systematic benchmark or datasets which allows researchers to evaluate the progress made by new learned approaches and even systematically develop new learned approaches. In this paper, we are releasing a benchmark, containing thousands of queries over 20 distinct real-world databases for learned cardinality estimation. In contrast to other initial benchmarks, our benchmark is much more diverse and can be used for training and testing learned models systematically. Using this benchmark, we explored whether learned cardinality estimation can be transferred to an unseen dataset in a zero-shot manner. We trained GNN-based and transformer-based models to study the problem in three setups: 1-) instance-based, 2-) zero-shot, and 3-) fine-tuned. Our results show that while we get promising results for zero-shot cardinality estimation on simple single table queries; as soon as we add joins, the accuracy drops. However, we show that with fine-tuning, we can still utilize pre-trained models for cardinality estimation, significantly reducing training overheads compared to instance specific models. We are open sourcing our scripts to collect statistics, generate queries and training datasets to foster more extensive research, also from the ML community on the important problem of cardinality estimation and in particular improve on recent directions such as pre-trained cardinality estimation.
Push the Boundary of SAM: A Pseudo-label Correction Framework for Medical Segmentation
Aug 02, 2023Segment anything model (SAM) has emerged as the leading approach for zero-shot learning in segmentation, offering the advantage of avoiding pixel-wise annotation. It is particularly appealing in medical image segmentation where annotation is laborious and expertise-demanding. However, the direct application of SAM often yields inferior results compared to conventional fully supervised segmentation networks. While using SAM generated pseudo label could also benefit the training of fully supervised segmentation, the performance is limited by the quality of pseudo labels. In this paper, we propose a novel label corruption to push the boundary of SAM-based segmentation. Our model utilizes a novel noise detection module to distinguish between noisy labels from clean labels. This enables us to correct the noisy labels using an uncertainty-based self-correction module, thereby enriching the clean training set. Finally, we retrain the network with updated labels to optimize its weights for future predictions. One key advantage of our model is its ability to train deep networks using SAM-generated pseudo labels without relying on a subset of expert-level annotations. We demonstrate the effectiveness of our proposed model on both X-ray and lung CT datasets, indicating its ability to improve segmentation accuracy and outperform baseline methods in label correction.
SCPAT-GAN: Structural Constrained and Pathology Aware Convolutional Transformer-GAN for Virtual Histology Staining of Human Coronary OCT images
Jul 22, 2023There is a significant need for the generation of virtual histological information from coronary optical coherence tomography (OCT) images to better guide the treatment of coronary artery disease. However, existing methods either require a large pixel-wisely paired training dataset or have limited capability to map pathological regions. To address these issues, we proposed a structural constrained, pathology aware, transformer generative adversarial network, namely SCPAT-GAN, to generate virtual stained H&E histology from OCT images. The proposed SCPAT-GAN advances existing methods via a novel design to impose pathological guidance on structural layers using transformer-based network.
Frequency-aware optical coherence tomography image super-resolution via conditional generative adversarial neural network
Jul 20, 2023



Optical coherence tomography (OCT) has stimulated a wide range of medical image-based diagnosis and treatment in fields such as cardiology and ophthalmology. Such applications can be further facilitated by deep learning-based super-resolution technology, which improves the capability of resolving morphological structures. However, existing deep learning-based method only focuses on spatial distribution and disregard frequency fidelity in image reconstruction, leading to a frequency bias. To overcome this limitation, we propose a frequency-aware super-resolution framework that integrates three critical frequency-based modules (i.e., frequency transformation, frequency skip connection, and frequency alignment) and frequency-based loss function into a conditional generative adversarial network (cGAN). We conducted a large-scale quantitative study from an existing coronary OCT dataset to demonstrate the superiority of our proposed framework over existing deep learning frameworks. In addition, we confirmed the generalizability of our framework by applying it to fish corneal images and rat retinal images, demonstrating its capability to super-resolve morphological details in eye imaging.
Detecting and measuring human gastric peristalsis using magnetically controlled capsule endoscope
Jan 24, 2023
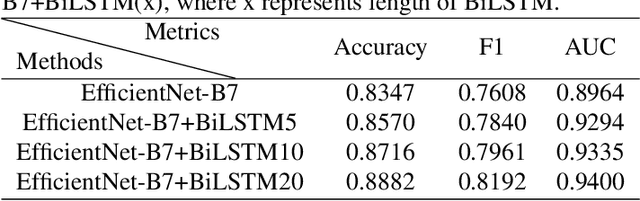
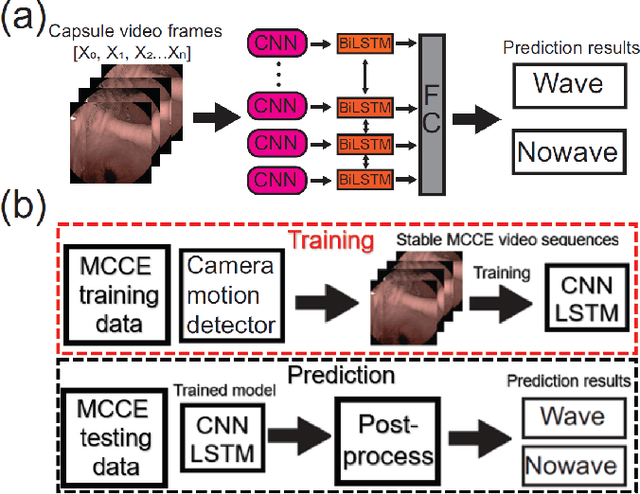

Magnetically controlled capsule endoscope (MCCE) is an emerging tool for the diagnosis of gastric diseases with the advantages of comfort, safety, and no anesthesia. In this paper, we develop algorithms to detect and measure human gastric peristalsis (contraction wave) using video sequences acquired by MCCE. We develop a spatial-temporal deep learning algorithm to detect gastric contraction waves and measure human gastric peristalsis periods. The quality of MCCE video sequences is prone to camera motion. We design a camera motion detector (CMD) to process the MCCE video sequences, mitigating the camera movement during MCCE examination. To the best of our knowledge, we are the first to propose computer vision-based solutions to detect and measure human gastric peristalsis. Our methods have great potential in assisting the diagnosis of gastric diseases by evaluating gastric motility.