 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Screen Time Identification in Children with a Multi-View Vision Language Model and Screen Time Tracker
Oct 02, 2024



Being able to accurately monitor the screen exposure of young children is important for research on phenomena linked to screen use such as childhood obesity, physical activity, and social interaction. Most existing studies rely upon self-report or manual measures from bulky wearable sensors, thus lacking efficiency and accuracy in capturing quantitative screen exposure data. In this work, we developed a novel sensor informatics framework that utilizes egocentric images from a wearable sensor, termed the screen time tracker (STT), and a vision language model (VLM). In particular, we devised a multi-view VLM that takes multiple views from egocentric image sequences and interprets screen exposure dynamically. We validated our approach by using a dataset of children's free-living activities, demonstrating significant improvement over existing methods in plain vision language models and object detection models. Results supported the promise of this monitoring approach, which could optimize behavioral research on screen exposure in children's naturalistic settings.
A Two-Stage Proactive Dialogue Generator for Efficient Clinical Information Collection Using Large Language Model
Oct 02, 2024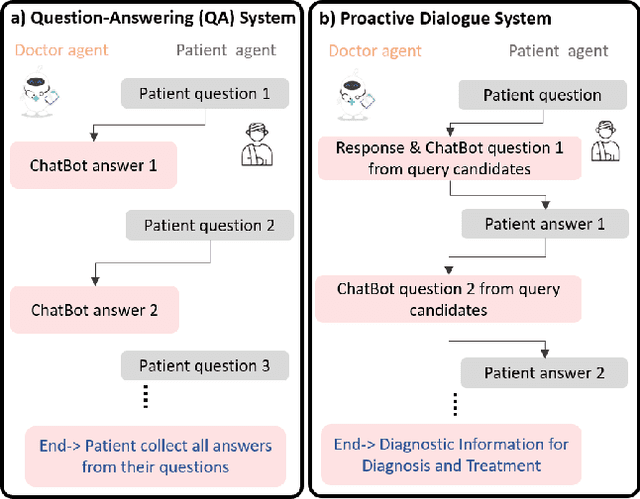

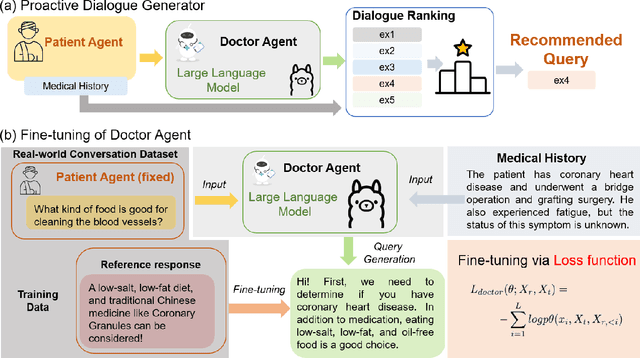

Efficient patient-doctor interaction is among the key factors for a successful disease diagnosis. During the conversation, the doctor could query complementary diagnostic information, such as the patient's symptoms, previous surgery, and other related information that goes beyond medical evidence data (test results) to enhance disease diagnosis. However, this procedure is usually time-consuming and less-efficient, which can be potentially optimized through computer-assisted systems. As such, we propose a diagnostic dialogue system to automate the patient information collection procedure. By exploiting medical history and conversation logic, our conversation agents, particularly the doctor agent, can pose multi-round clinical queries to effectively collect the most relevant disease diagnostic information. Moreover, benefiting from our two-stage recommendation structure, carefully designed ranking criteria, and interactive patient agent, our model is able to overcome the under-exploration and non-flexible challenges in dialogue generation. Our experimental results on a real-world medical conversation dataset show that our model can generate clinical queries that mimic the conversation style of real doctors, with efficient fluency, professionalism, and safety, while effectively collecting relevant disease diagnostic information.