 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Screen Time Identification in Children with a Multi-View Vision Language Model and Screen Time Tracker
Oct 02, 2024



Being able to accurately monitor the screen exposure of young children is important for research on phenomena linked to screen use such as childhood obesity, physical activity, and social interaction. Most existing studies rely upon self-report or manual measures from bulky wearable sensors, thus lacking efficiency and accuracy in capturing quantitative screen exposure data. In this work, we developed a novel sensor informatics framework that utilizes egocentric images from a wearable sensor, termed the screen time tracker (STT), and a vision language model (VLM). In particular, we devised a multi-view VLM that takes multiple views from egocentric image sequences and interprets screen exposure dynamically. We validated our approach by using a dataset of children's free-living activities, demonstrating significant improvement over existing methods in plain vision language models and object detection models. Results supported the promise of this monitoring approach, which could optimize behavioral research on screen exposure in children's naturalistic settings.
A Two-Stage Proactive Dialogue Generator for Efficient Clinical Information Collection Using Large Language Model
Oct 02, 2024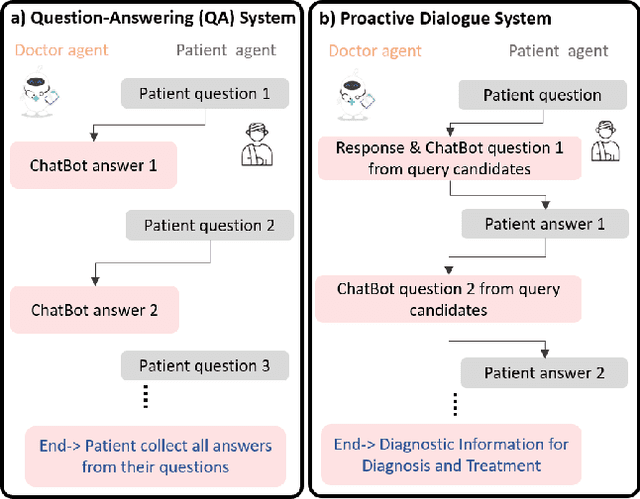

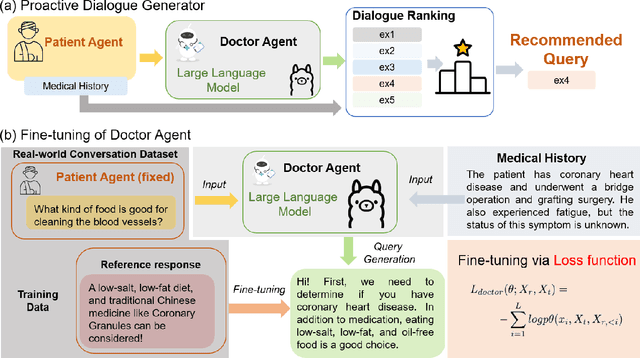

Efficient patient-doctor interaction is among the key factors for a successful disease diagnosis. During the conversation, the doctor could query complementary diagnostic information, such as the patient's symptoms, previous surgery, and other related information that goes beyond medical evidence data (test results) to enhance disease diagnosis. However, this procedure is usually time-consuming and less-efficient, which can be potentially optimized through computer-assisted systems. As such, we propose a diagnostic dialogue system to automate the patient information collection procedure. By exploiting medical history and conversation logic, our conversation agents, particularly the doctor agent, can pose multi-round clinical queries to effectively collect the most relevant disease diagnostic information. Moreover, benefiting from our two-stage recommendation structure, carefully designed ranking criteria, and interactive patient agent, our model is able to overcome the under-exploration and non-flexible challenges in dialogue generation. Our experimental results on a real-world medical conversation dataset show that our model can generate clinical queries that mimic the conversation style of real doctors, with efficient fluency, professionalism, and safety, while effectively collecting relevant disease diagnostic information.
SCPAT-GAN: Structural Constrained and Pathology Aware Convolutional Transformer-GAN for Virtual Histology Staining of Human Coronary OCT images
Jul 22, 2023There is a significant need for the generation of virtual histological information from coronary optical coherence tomography (OCT) images to better guide the treatment of coronary artery disease. However, existing methods either require a large pixel-wisely paired training dataset or have limited capability to map pathological regions. To address these issues, we proposed a structural constrained, pathology aware, transformer generative adversarial network, namely SCPAT-GAN, to generate virtual stained H&E histology from OCT images. The proposed SCPAT-GAN advances existing methods via a novel design to impose pathological guidance on structural layers using transformer-based network.
Frequency-aware optical coherence tomography image super-resolution via conditional generative adversarial neural network
Jul 20, 2023



Optical coherence tomography (OCT) has stimulated a wide range of medical image-based diagnosis and treatment in fields such as cardiology and ophthalmology. Such applications can be further facilitated by deep learning-based super-resolution technology, which improves the capability of resolving morphological structures. However, existing deep learning-based method only focuses on spatial distribution and disregard frequency fidelity in image reconstruction, leading to a frequency bias. To overcome this limitation, we propose a frequency-aware super-resolution framework that integrates three critical frequency-based modules (i.e., frequency transformation, frequency skip connection, and frequency alignment) and frequency-based loss function into a conditional generative adversarial network (cGAN). We conducted a large-scale quantitative study from an existing coronary OCT dataset to demonstrate the superiority of our proposed framework over existing deep learning frameworks. In addition, we confirmed the generalizability of our framework by applying it to fish corneal images and rat retinal images, demonstrating its capability to super-resolve morphological details in eye imaging.
Detecting and measuring human gastric peristalsis using magnetically controlled capsule endoscope
Jan 24, 2023
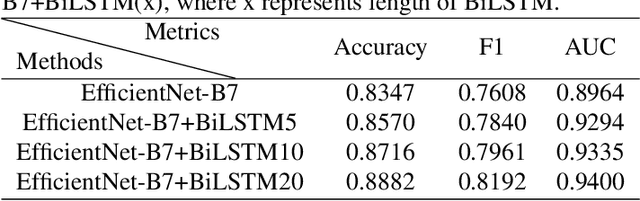
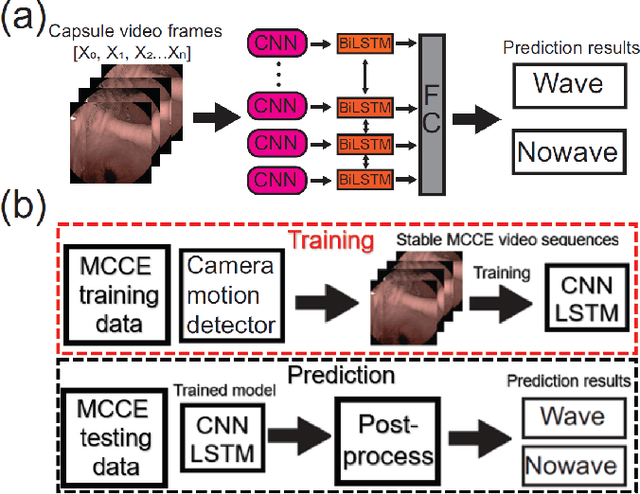

Magnetically controlled capsule endoscope (MCCE) is an emerging tool for the diagnosis of gastric diseases with the advantages of comfort, safety, and no anesthesia. In this paper, we develop algorithms to detect and measure human gastric peristalsis (contraction wave) using video sequences acquired by MCCE. We develop a spatial-temporal deep learning algorithm to detect gastric contraction waves and measure human gastric peristalsis periods. The quality of MCCE video sequences is prone to camera motion. We design a camera motion detector (CMD) to process the MCCE video sequences, mitigating the camera movement during MCCE examination. To the best of our knowledge, we are the first to propose computer vision-based solutions to detect and measure human gastric peristalsis. Our methods have great potential in assisting the diagnosis of gastric diseases by evaluating gastric motility.
Towards reliable calcification detection: calibration of uncertainty in coronary optical coherence tomography images
Nov 12, 2022Optical coherence tomography (OCT) has become increasingly essential in assisting the treatment of coronary artery disease (CAD). Image-guided solutions such as Percutaneous Coronary Intervention (PCI) are extensively used during the treatment of CAD. However, unidentified calcified regions within a narrowed artery could impair the outcome of the PCI. Prior to treatments, object detection is paramount to automatically procure accurate readings on the location and thickness of calcifications within the artery. Deep learning-based object detection methods have been explored in a variety of applications. The quality of object detection predictions could lead to uncertain results, which are not desirable in safety-critical scenarios. In this work, we implement an object detection model, You-Only-Look-Once v5 (YOLO), on a calcification detection framework within coronary OCT images. We evaluate the uncertainty of predictions based on the expected calibration errors, thus assessing the certainty level of detection results. To calibrate confidence scores of predictions, we implement dependent logistic calibration using each detection result's confidence and center coordinates. With the calibrated confidence score of each prediction, we lower the uncertainty of predictions in calcification detection. Our results show that the YOLO achieves higher precision and recall in comparison with the other object detection model, meanwhile producing more reliable results. The calibrated confidence of prediction results in a confidence error of approximately 0.13, suggesting that the confidence calibration on calcification detection could provide a more trustworthy result, indicating a great potential to assist clinical evaluation of treating the CAD during the imaging-guided procedure.
Structural constrained virtual histology staining for human coronary imaging using deep learning
Nov 12, 2022



Histopathological analysis is crucial in artery characterization for coronary artery disease (CAD). However, histology requires an invasive and time-consuming process. In this paper, we propose to generate virtual histology staining using Optical Coherence Tomography (OCT) images to enable real-time histological visualization. We develop a deep learning network, namely Coronary-GAN, to transfer coronary OCT images to virtual histology images. With a special consideration on the structural constraints in coronary OCT images, our method achieves better image generation performance than the conventional GAN-based method. The experimental results indicate that Coronary-GAN generates virtual histology images that are similar to real histology images, revealing the human coronary layers.
Multi-scale reconstruction of undersampled spectral-spatial OCT data for coronary imaging using deep learning
Apr 25, 2022
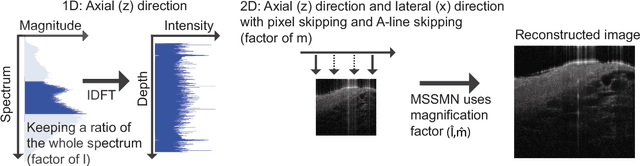
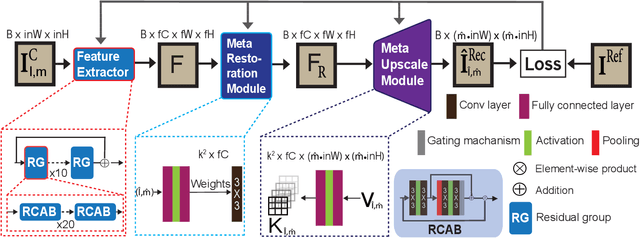

Coronary artery disease (CAD) is a cardiovascular condition with high morbidity and mortality. Intravascular optical coherence tomography (IVOCT) has been considered as an optimal imagining system for the diagnosis and treatment of CAD. Constrained by Nyquist theorem, dense sampling in IVOCT attains high resolving power to delineate cellular structures/ features. There is a trade-off between high spatial resolution and fast scanning rate for coronary imaging. In this paper, we propose a viable spectral-spatial acquisition method that down-scales the sampling process in both spectral and spatial domain while maintaining high quality in image reconstruction. The down-scaling schedule boosts data acquisition speed without any hardware modifications. Additionally, we propose a unified multi-scale reconstruction framework, namely Multiscale- Spectral-Spatial-Magnification Network (MSSMN), to resolve highly down-scaled (compressed) OCT images with flexible magnification factors. We incorporate the proposed methods into Spectral Domain OCT (SD-OCT) imaging of human coronary samples with clinical features such as stent and calcified lesions. Our experimental results demonstrate that spectral-spatial downscaled data can be better reconstructed than data that is downscaled solely in either spectral or spatial domain. Moreover, we observe better reconstruction performance using MSSMN than using existing reconstruction methods. Our acquisition method and multi-scale reconstruction framework, in combination, may allow faster SD-OCT inspection with high resolution during coronary intervention.