 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Screen Time Identification in Children with a Multi-View Vision Language Model and Screen Time Tracker
Oct 02, 2024



Being able to accurately monitor the screen exposure of young children is important for research on phenomena linked to screen use such as childhood obesity, physical activity, and social interaction. Most existing studies rely upon self-report or manual measures from bulky wearable sensors, thus lacking efficiency and accuracy in capturing quantitative screen exposure data. In this work, we developed a novel sensor informatics framework that utilizes egocentric images from a wearable sensor, termed the screen time tracker (STT), and a vision language model (VLM). In particular, we devised a multi-view VLM that takes multiple views from egocentric image sequences and interprets screen exposure dynamically. We validated our approach by using a dataset of children's free-living activities, demonstrating significant improvement over existing methods in plain vision language models and object detection models. Results supported the promise of this monitoring approach, which could optimize behavioral research on screen exposure in children's naturalistic settings.
Improving Food Detection For Images From a Wearable Egocentric Camera
Jan 19, 2023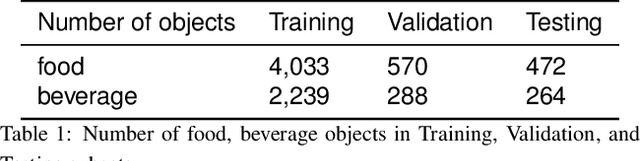
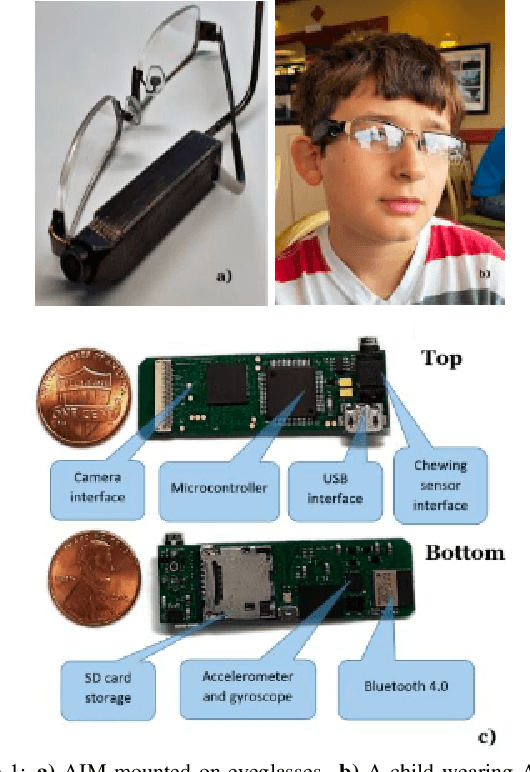

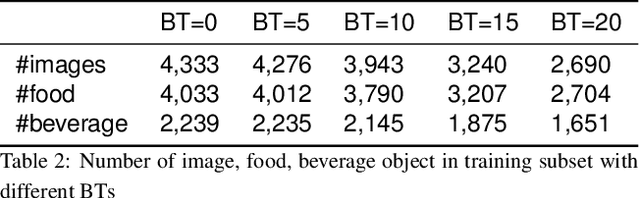
Diet is an important aspect of our health. Good dietary habits can contribute to the prevention of many diseases and improve the overall quality of life. To better understand the relationship between diet and health, image-based dietary assessment systems have been developed to collect dietary information. We introduce the Automatic Ingestion Monitor (AIM), a device that can be attached to one's eye glasses. It provides an automated hands-free approach to capture eating scene images. While AIM has several advantages, images captured by the AIM are sometimes blurry. Blurry images can significantly degrade the performance of food image analysis such as food detection. In this paper, we propose an approach to pre-process images collected by the AIM imaging sensor by rejecting extremely blurry images to improve the performance of food detection.
Clustering Egocentric Images in Passive Dietary Monitoring with Self-Supervised Learning
Aug 25, 2022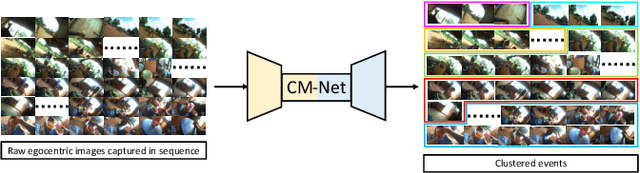
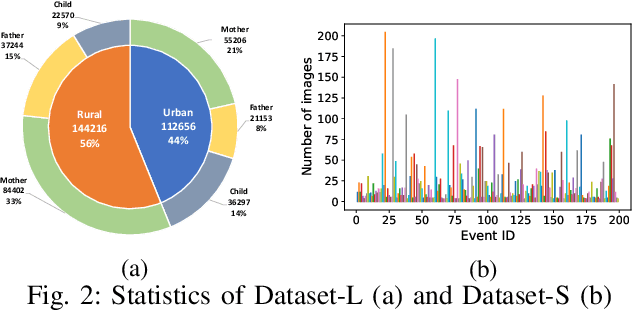
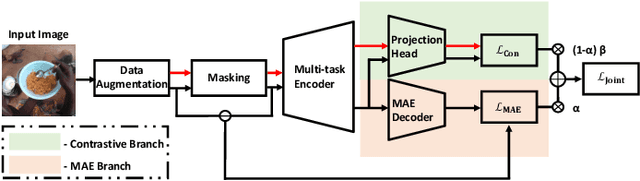
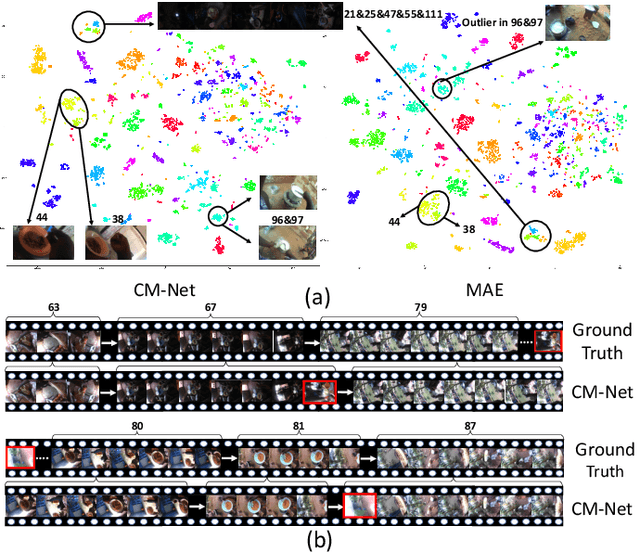
In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021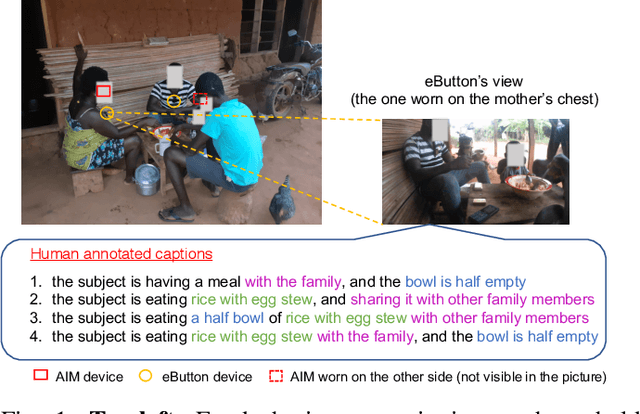
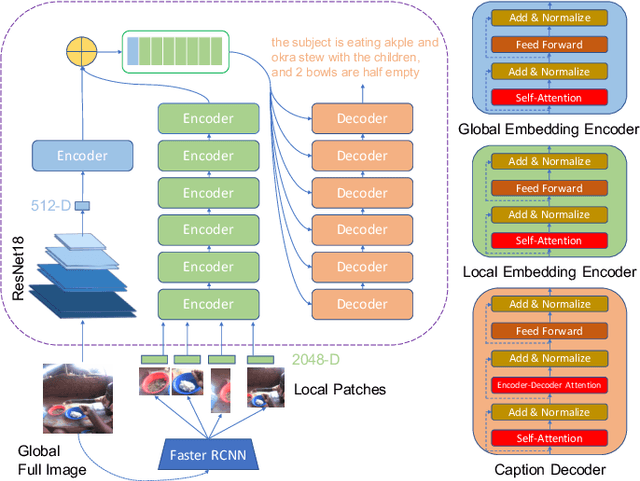
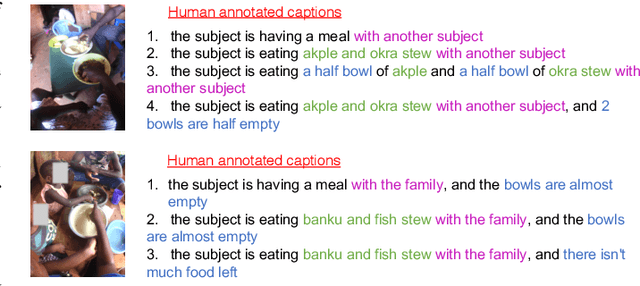
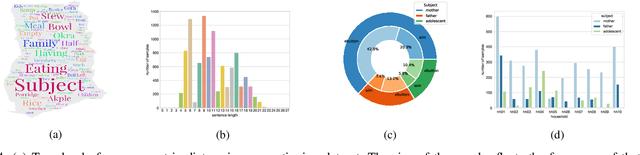
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.