 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHISPASpoof: A New Dataset For Spanish Speech Forensics
Sep 11, 2025Zero-shot Voice Cloning (VC) and Text-to-Speech (TTS) methods have advanced rapidly, enabling the generation of highly realistic synthetic speech and raising serious concerns about their misuse. While numerous detectors have been developed for English and Chinese, Spanish-spoken by over 600 million people worldwide-remains underrepresented in speech forensics. To address this gap, we introduce HISPASpoof, the first large-scale Spanish dataset designed for synthetic speech detection and attribution. It includes real speech from public corpora across six accents and synthetic speech generated with six zero-shot TTS systems. We evaluate five representative methods, showing that detectors trained on English fail to generalize to Spanish, while training on HISPASpoof substantially improves detection. We also evaluate synthetic speech attribution performance on HISPASpoof, i.e., identifying the generation method of synthetic speech. HISPASpoof thus provides a critical benchmark for advancing reliable and inclusive speech forensics in Spanish.
Comparative Analysis of ASR Methods for Speech Deepfake Detection
Nov 26, 2024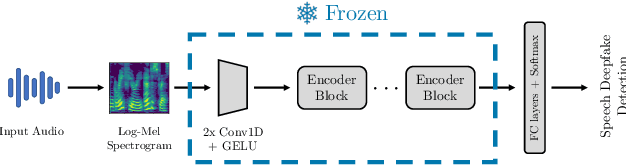
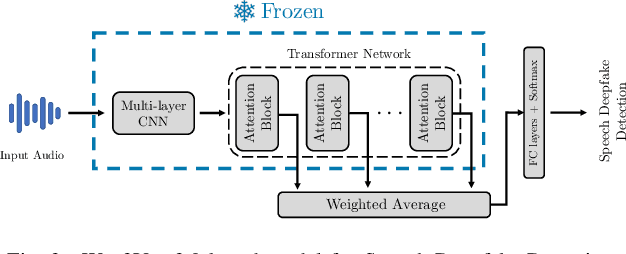
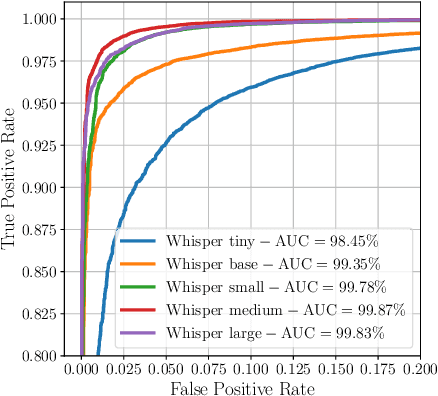
Recent techniques for speech deepfake detection often rely on pre-trained self-supervised models. These systems, initially developed for Automatic Speech Recognition (ASR), have proved their ability to offer a meaningful representation of speech signals, which can benefit various tasks, including deepfake detection. In this context, pre-trained models serve as feature extractors and are used to extract embeddings from input speech, which are then fed to a binary speech deepfake detector. The remarkable accuracy achieved through this approach underscores a potential relationship between ASR and speech deepfake detection. However, this connection is not yet entirely clear, and we do not know whether improved performance in ASR corresponds to higher speech deepfake detection capabilities. In this paper, we address this question through a systematic analysis. We consider two different pre-trained self-supervised ASR models, Whisper and Wav2Vec 2.0, and adapt them for the speech deepfake detection task. These models have been released in multiple versions, with increasing number of parameters and enhanced ASR performance. We investigate whether performance improvements in ASR correlate with improvements in speech deepfake detection. Our results provide insights into the relationship between these two tasks and offer valuable guidance for the development of more effective speech deepfake detectors.
FairSSD: Understanding Bias in Synthetic Speech Detectors
Apr 17, 2024
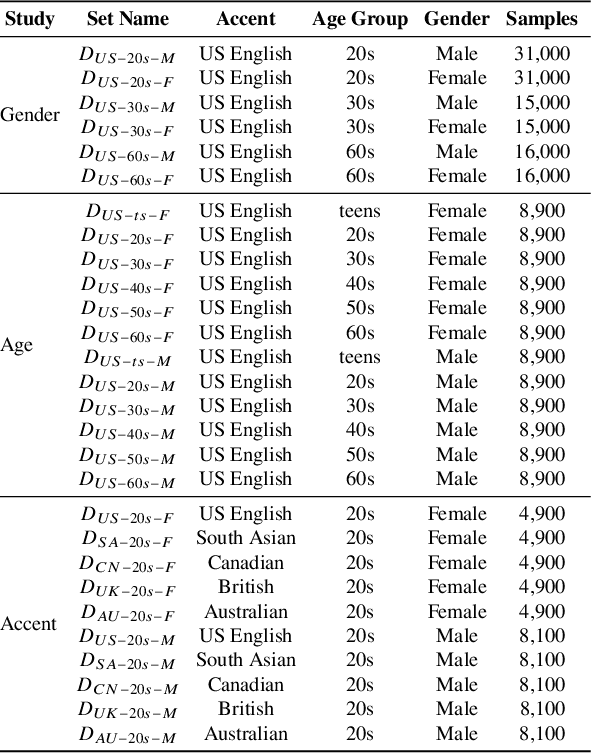
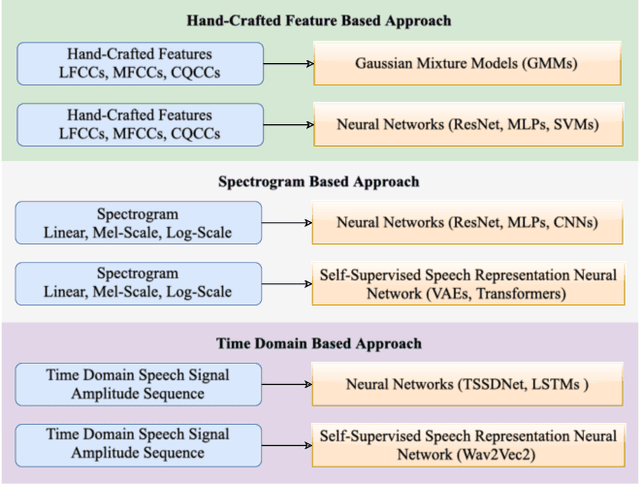
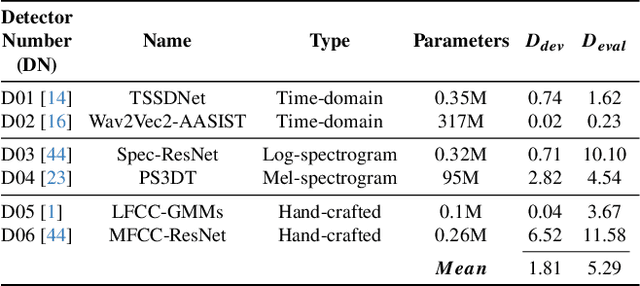
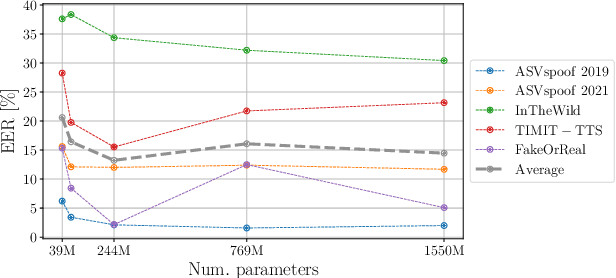
Methods that can generate synthetic speech which is perceptually indistinguishable from speech recorded by a human speaker, are easily available. Several incidents report misuse of synthetic speech generated from these methods to commit fraud. To counter such misuse, many methods have been proposed to detect synthetic speech. Some of these detectors are more interpretable, can generalize to detect synthetic speech in the wild and are robust to noise. However, limited work has been done on understanding bias in these detectors. In this work, we examine bias in existing synthetic speech detectors to determine if they will unfairly target a particular gender, age and accent group. We also inspect whether these detectors will have a higher misclassification rate for bona fide speech from speech-impaired speakers w.r.t fluent speakers. Extensive experiments on 6 existing synthetic speech detectors using more than 0.9 million speech signals demonstrate that most detectors are gender, age and accent biased, and future work is needed to ensure fairness. To support future research, we release our evaluation dataset, models used in our study and source code at https://gitlab.com/viper-purdue/fairssd.
Compression Robust Synthetic Speech Detection Using Patched Spectrogram Transformer
Feb 22, 2024



Many deep learning synthetic speech generation tools are readily available. The use of synthetic speech has caused financial fraud, impersonation of people, and misinformation to spread. For this reason forensic methods that can detect synthetic speech have been proposed. Existing methods often overfit on one dataset and their performance reduces substantially in practical scenarios such as detecting synthetic speech shared on social platforms. In this paper we propose, Patched Spectrogram Synthetic Speech Detection Transformer (PS3DT), a synthetic speech detector that converts a time domain speech signal to a mel-spectrogram and processes it in patches using a transformer neural network. We evaluate the detection performance of PS3DT on ASVspoof2019 dataset. Our experiments show that PS3DT performs well on ASVspoof2019 dataset compared to other approaches using spectrogram for synthetic speech detection. We also investigate generalization performance of PS3DT on In-the-Wild dataset. PS3DT generalizes well than several existing methods on detecting synthetic speech from an out-of-distribution dataset. We also evaluate robustness of PS3DT to detect telephone quality synthetic speech and synthetic speech shared on social platforms (compressed speech). PS3DT is robust to compression and can detect telephone quality synthetic speech better than several existing methods.
End-to-end Evaluation of Practical Video Analytics Systems for Face Detection and Recognition
Oct 10, 2023
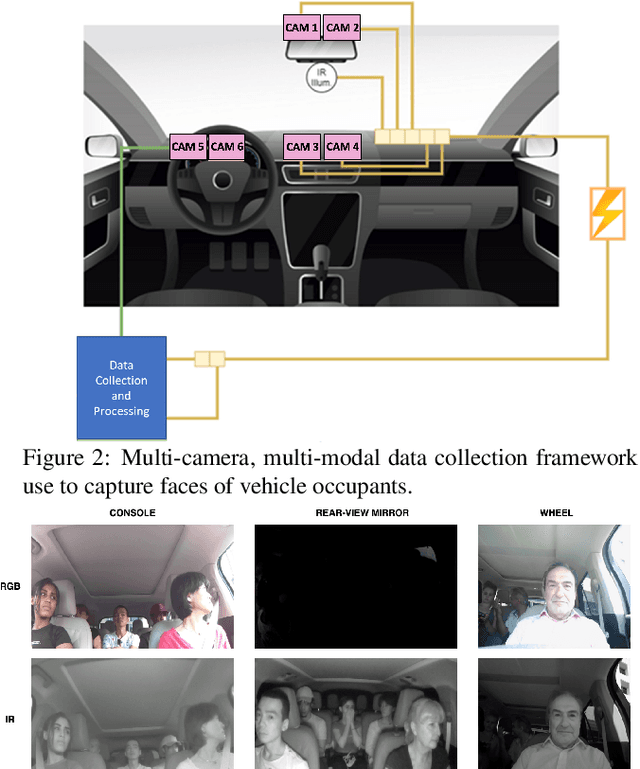


Practical video analytics systems that are deployed in bandwidth constrained environments like autonomous vehicles perform computer vision tasks such as face detection and recognition. In an end-to-end face analytics system, inputs are first compressed using popular video codecs like HEVC and then passed onto modules that perform face detection, alignment, and recognition sequentially. Typically, the modules of these systems are evaluated independently using task-specific imbalanced datasets that can misconstrue performance estimates. In this paper, we perform a thorough end-to-end evaluation of a face analytics system using a driving-specific dataset, which enables meaningful interpretations. We demonstrate how independent task evaluations, dataset imbalances, and inconsistent annotations can lead to incorrect system performance estimates. We propose strategies to create balanced evaluation subsets of our dataset and to make its annotations consistent across multiple analytics tasks and scenarios. We then evaluate the end-to-end system performance sequentially to account for task interdependencies. Our experiments show that our approach provides consistent, accurate, and interpretable estimates of the system's performance which is critical for real-world applications.
* Accepted to Autonomous Vehicles and Machines 2023 Conference, IS&T Electronic Imaging (EI) Symposium
Information Forensics and Security: A quarter-century-long journey
Sep 21, 2023Information Forensics and Security (IFS) is an active R&D area whose goal is to ensure that people use devices, data, and intellectual properties for authorized purposes and to facilitate the gathering of solid evidence to hold perpetrators accountable. For over a quarter century since the 1990s, the IFS research area has grown tremendously to address the societal needs of the digital information era. The IEEE Signal Processing Society (SPS) has emerged as an important hub and leader in this area, and the article below celebrates some landmark technical contributions. In particular, we highlight the major technological advances on some selected focus areas in the field developed in the last 25 years from the research community and present future trends.
Diffusion Model with Clustering-based Conditioning for Food Image Generation
Sep 01, 2023



Image-based dietary assessment serves as an efficient and accurate solution for recording and analyzing nutrition intake using eating occasion images as input. Deep learning-based techniques are commonly used to perform image analysis such as food classification, segmentation, and portion size estimation, which rely on large amounts of food images with annotations for training. However, such data dependency poses significant barriers to real-world applications, because acquiring a substantial, diverse, and balanced set of food images can be challenging. One potential solution is to use synthetic food images for data augmentation. Although existing work has explored the use of generative adversarial networks (GAN) based structures for generation, the quality of synthetic food images still remains subpar. In addition, while diffusion-based generative models have shown promising results for general image generation tasks, the generation of food images can be challenging due to the substantial intra-class variance. In this paper, we investigate the generation of synthetic food images based on the conditional diffusion model and propose an effective clustering-based training framework, named ClusDiff, for generating high-quality and representative food images. The proposed method is evaluated on the Food-101 dataset and shows improved performance when compared with existing image generation works. We also demonstrate that the synthetic food images generated by ClusDiff can help address the severe class imbalance issue in long-tailed food classification using the VFN-LT dataset.
Semi-Supervised Object Detection for Sorghum Panicles in UAV Imagery
May 16, 2023



The sorghum panicle is an important trait related to grain yield and plant development. Detecting and counting sorghum panicles can provide significant information for plant phenotyping. Current deep-learning-based object detection methods for panicles require a large amount of training data. The data labeling is time-consuming and not feasible for real application. In this paper, we present an approach to reduce the amount of training data for sorghum panicle detection via semi-supervised learning. Results show we can achieve similar performance as supervised methods for sorghum panicle detection by only using 10\% of original training data.
DSVAE: Interpretable Disentangled Representation for Synthetic Speech Detection
Apr 06, 2023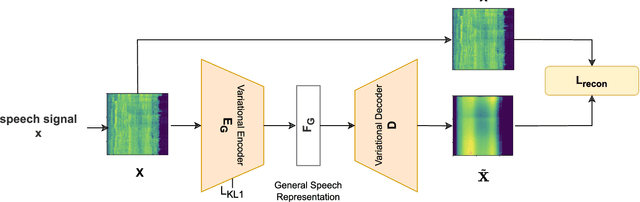
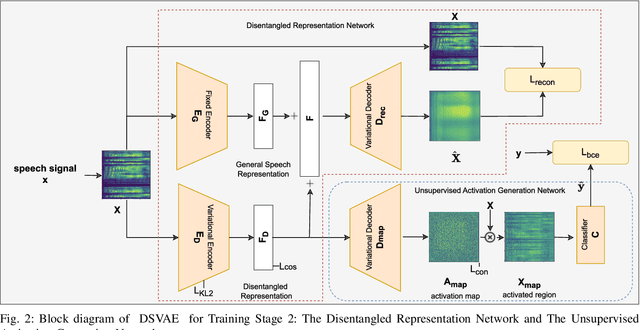
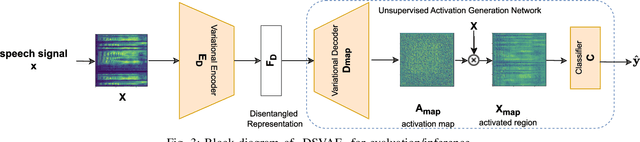
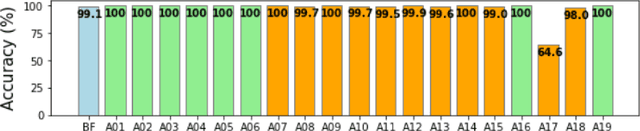
Tools to generate high quality synthetic speech signal that is perceptually indistinguishable from speech recorded from human speakers are easily available. Several approaches have been proposed for detecting synthetic speech. Many of these approaches use deep learning methods as a black box without providing reasoning for the decisions they make. This limits the interpretability of these approaches. In this paper, we propose Disentangled Spectrogram Variational Auto Encoder (DSVAE) which is a two staged trained variational autoencoder that processes spectrograms of speech using disentangled representation learning to generate interpretable representations of a speech signal for detecting synthetic speech. DSVAE also creates an activation map to highlight the spectrogram regions that discriminate synthetic and bona fide human speech signals. We evaluated the representations obtained from DSVAE using the ASVspoof2019 dataset. Our experimental results show high accuracy (>98%) on detecting synthetic speech from 6 known and 10 out of 11 unknown speech synthesizers. We also visualize the representation obtained from DSVAE for 17 different speech synthesizers and verify that they are indeed interpretable and discriminate bona fide and synthetic speech from each of the synthesizers.
Illumination Variation Correction Using Image Synthesis For Unsupervised Domain Adaptive Person Re-Identification
Jan 23, 2023



Unsupervised domain adaptive (UDA) person re-identification (re-ID) aims to learn identity information from labeled images in source domains and apply it to unlabeled images in a target domain. One major issue with many unsupervised re-identification methods is that they do not perform well relative to large domain variations such as illumination, viewpoint, and occlusions. In this paper, we propose a Synthesis Model Bank (SMB) to deal with illumination variation in unsupervised person re-ID. The proposed SMB consists of several convolutional neural networks (CNN) for feature extraction and Mahalanobis matrices for distance metrics. They are trained using synthetic data with different illumination conditions such that their synergistic effect makes the SMB robust against illumination variation. To better quantify the illumination intensity and improve the quality of synthetic images, we introduce a new 3D virtual-human dataset for GAN-based image synthesis. From our experiments, the proposed SMB outperforms other synthesis methods on several re-ID benchmarks.