 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiDetect: Weibull Distribution-Based Defense against Poisoning Attacks in Federated Learning for Network Intrusion Detection Systems
Apr 06, 2025In the era of data expansion, ensuring data privacy has become increasingly critical, posing significant challenges to traditional AI-based applications. In addition, the increasing adoption of IoT devices has introduced significant cybersecurity challenges, making traditional Network Intrusion Detection Systems (NIDS) less effective against evolving threats, and privacy concerns and regulatory restrictions limit their deployment. Federated Learning (FL) has emerged as a promising solution, allowing decentralized model training while maintaining data privacy to solve these issues. However, despite implementing privacy-preserving technologies, FL systems remain vulnerable to adversarial attacks. Furthermore, data distribution among clients is not heterogeneous in the FL scenario. We propose WeiDetect, a two-phase, server-side defense mechanism for FL-based NIDS that detects malicious participants to address these challenges. In the first phase, local models are evaluated using a validation dataset to generate validation scores. These scores are then analyzed using a Weibull distribution, identifying and removing malicious models. We conducted experiments to evaluate the effectiveness of our approach in diverse attack settings. Our evaluation included two popular datasets, CIC-Darknet2020 and CSE-CIC-IDS2018, tested under non-IID data distributions. Our findings highlight that WeiDetect outperforms state-of-the-art defense approaches, improving higher target class recall up to 70% and enhancing the global model's F1 score by 1% to 14%.
FakeScope: Large Multimodal Expert Model for Transparent AI-Generated Image Forensics
Mar 31, 2025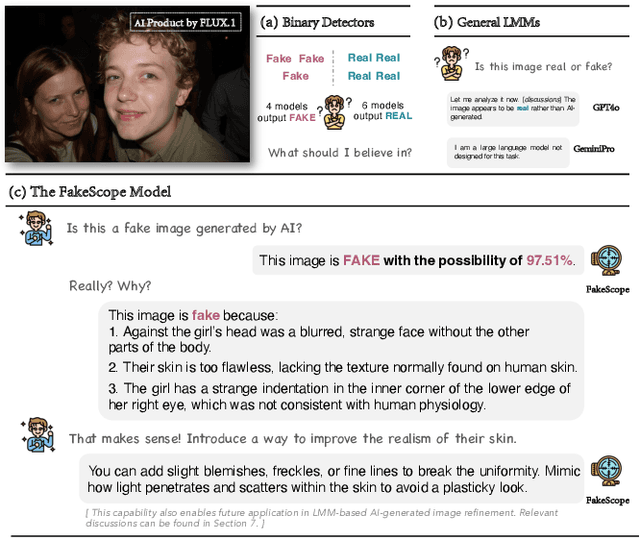



The rapid and unrestrained advancement of generative artificial intelligence (AI) presents a double-edged sword: while enabling unprecedented creativity, it also facilitates the generation of highly convincing deceptive content, undermining societal trust. As image generation techniques become increasingly sophisticated, detecting synthetic images is no longer just a binary task: it necessitates interpretable, context-aware methodologies that enhance trustworthiness and transparency. However, existing detection models primarily focus on classification, offering limited explanatory insights into image authenticity. In this work, we propose FakeScope, an expert multimodal model (LMM) tailored for AI-generated image forensics, which not only identifies AI-synthetic images with high accuracy but also provides rich, interpretable, and query-driven forensic insights. We first construct FakeChain dataset that contains linguistic authenticity reasoning based on visual trace evidence, developed through a novel human-machine collaborative framework. Building upon it, we further present FakeInstruct, the largest multimodal instruction tuning dataset containing 2 million visual instructions tailored to enhance forensic awareness in LMMs. FakeScope achieves state-of-the-art performance in both closed-ended and open-ended forensic scenarios. It can distinguish synthetic images with high accuracy while offering coherent and insightful explanations, free-form discussions on fine-grained forgery attributes, and actionable enhancement strategies. Notably, despite being trained exclusively on qualitative hard labels, FakeScope demonstrates remarkable zero-shot quantitative capability on detection, enabled by our proposed token-based probability estimation strategy. Furthermore, FakeScope exhibits strong generalization and in-the-wild ability, ensuring its applicability in real-world scenarios.
The NeRF Signature: Codebook-Aided Watermarking for Neural Radiance Fields
Feb 26, 2025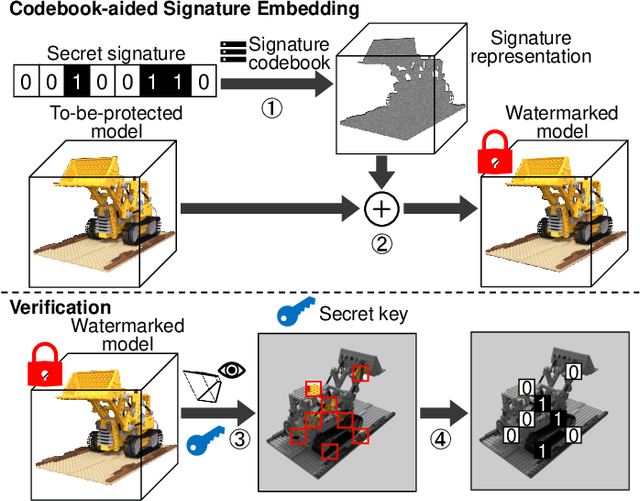
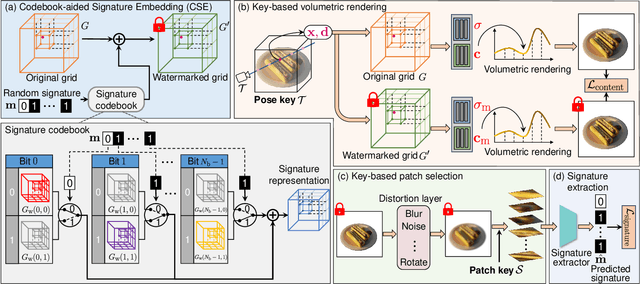
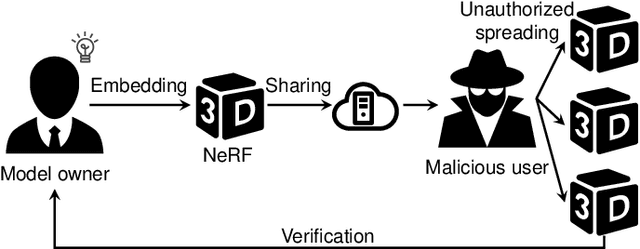
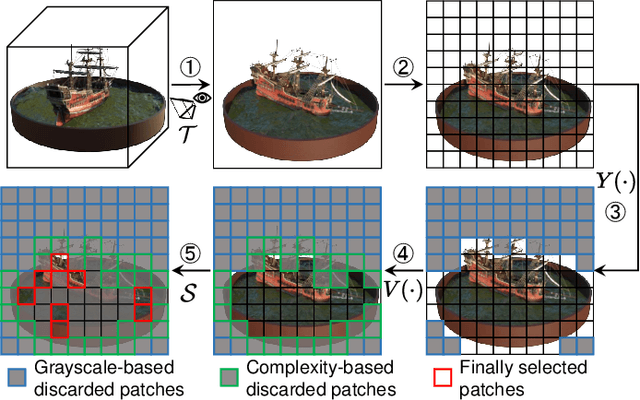
Neural Radiance Fields (NeRF) have been gaining attention as a significant form of 3D content representation. With the proliferation of NeRF-based creations, the need for copyright protection has emerged as a critical issue. Although some approaches have been proposed to embed digital watermarks into NeRF, they often neglect essential model-level considerations and incur substantial time overheads, resulting in reduced imperceptibility and robustness, along with user inconvenience. In this paper, we extend the previous criteria for image watermarking to the model level and propose NeRF Signature, a novel watermarking method for NeRF. We employ a Codebook-aided Signature Embedding (CSE) that does not alter the model structure, thereby maintaining imperceptibility and enhancing robustness at the model level. Furthermore, after optimization, any desired signatures can be embedded through the CSE, and no fine-tuning is required when NeRF owners want to use new binary signatures. Then, we introduce a joint pose-patch encryption watermarking strategy to hide signatures into patches rendered from a specific viewpoint for higher robustness. In addition, we explore a Complexity-Aware Key Selection (CAKS) scheme to embed signatures in high visual complexity patches to enhance imperceptibility. The experimental results demonstrate that our method outperforms other baseline methods in terms of imperceptibility and robustness. The source code is available at: https://github.com/luo-ziyuan/NeRF_Signature.
Self-Rationalization in the Wild: A Large Scale Out-of-Distribution Evaluation on NLI-related tasks
Feb 07, 2025Free-text explanations are expressive and easy to understand, but many datasets lack annotated explanation data, making it challenging to train models for explainable predictions. To address this, we investigate how to use existing explanation datasets for self-rationalization and evaluate models' out-of-distribution (OOD) performance. We fine-tune T5-Large and OLMo-7B models and assess the impact of fine-tuning data quality, the number of fine-tuning samples, and few-shot selection methods. The models are evaluated on 19 diverse OOD datasets across three tasks: natural language inference (NLI), fact-checking, and hallucination detection in abstractive summarization. For the generated explanation evaluation, we conduct a human study on 13 selected models and study its correlation with the Acceptability score (T5-11B) and three other LLM-based reference-free metrics. Human evaluation shows that the Acceptability score correlates most strongly with human judgments, demonstrating its effectiveness in evaluating free-text explanations. Our findings reveal: 1) few annotated examples effectively adapt models for OOD explanation generation; 2) compared to sample selection strategies, fine-tuning data source has a larger impact on OOD performance; and 3) models with higher label prediction accuracy tend to produce better explanations, as reflected by higher Acceptability scores.
Interactive Event Sifting using Bayesian Graph Neural Networks
Oct 07, 2024Forensic analysts often use social media imagery and texts to understand important events. A primary challenge is the initial sifting of irrelevant posts. This work introduces an interactive process for training an event-centric, learning-based multimodal classification model that automates sanitization. We propose a method based on Bayesian Graph Neural Networks (BGNNs) and evaluate active learning and pseudo-labeling formulations to reduce the number of posts the analyst must manually annotate. Our results indicate that BGNNs are useful for social-media data sifting for forensics investigations of events of interest, the value of active learning and pseudo-labeling varies based on the setting, and incorporating unlabelled data from other events improves performance.
Take It Easy: Label-Adaptive Self-Rationalization for Fact Verification and Explanation Generation
Oct 05, 2024



Computational methods to aid journalists in the task often require adapting a model to specific domains and generating explanations. However, most automated fact-checking methods rely on three-class datasets, which do not accurately reflect real-world misinformation. Moreover, fact-checking explanations are often generated based on text summarization of evidence, failing to address the relationship between the claim and the evidence. To address these issues, we extend the self-rationalization method--typically used in natural language inference (NLI) tasks--to fact verification. We propose a label-adaptive learning approach: first, we fine-tune a model to learn veracity prediction with annotated labels (step-1 model). Then, we fine-tune the step-1 model again to learn self-rationalization, using the same data and additional annotated explanations. Our results show that our label-adaptive approach improves veracity prediction by more than ten percentage points (Macro F1) on both the PubHealth and AVeriTec datasets, outperforming the GPT-4 model. Furthermore, to address the high cost of explanation annotation, we generated 64 synthetic explanations from three large language models: GPT-4-turbo, GPT-3.5-turbo, and Llama-3-8B and few-shot fine-tune our step-1 model. The few-shot synthetic explanation fine-tuned model performed comparably to the fully fine-tuned self-rationalization model, demonstrating the potential of low-budget learning with synthetic data. Our label-adaptive self-rationalization approach presents a promising direction for future research on real-world explainable fact-checking with different labeling schemes.
Explainable Artifacts for Synthetic Western Blot Source Attribution
Sep 27, 2024



Recent advancements in artificial intelligence have enabled generative models to produce synthetic scientific images that are indistinguishable from pristine ones, posing a challenge even for expert scientists habituated to working with such content. When exploited by organizations known as paper mills, which systematically generate fraudulent articles, these technologies can significantly contribute to the spread of misinformation about ungrounded science, potentially undermining trust in scientific research. While previous studies have explored black-box solutions, such as Convolutional Neural Networks, for identifying synthetic content, only some have addressed the challenge of generalizing across different models and providing insight into the artifacts in synthetic images that inform the detection process. This study aims to identify explainable artifacts generated by state-of-the-art generative models (e.g., Generative Adversarial Networks and Diffusion Models) and leverage them for open-set identification and source attribution (i.e., pointing to the model that created the image).
Image Provenance Analysis via Graph Encoding with Vision Transformer
Aug 26, 2024Recent advances in AI-powered image editing tools have significantly lowered the barrier to image modification, raising pressing security concerns those related to spreading misinformation and disinformation on social platforms. Image provenance analysis is crucial in this context, as it identifies relevant images within a database and constructs a relationship graph by mining hidden manipulation and transformation cues, thereby providing concrete evidence chains. This paper introduces a novel end-to-end deep learning framework designed to explore the structural information of provenance graphs. Our proposed method distinguishes from previous approaches in two main ways. First, unlike earlier methods that rely on prior knowledge and have limited generalizability, our framework relies upon a patch attention mechanism to capture image provenance clues for local manipulations and global transformations, thereby enhancing graph construction performance. Second, while previous methods primarily focus on identifying tampering traces only between image pairs, they often overlook the hidden information embedded in the topology of the provenance graph. Our approach aligns the model training objectives with the final graph construction task, incorporating the overall structural information of the graph into the training process. We integrate graph structure information with the attention mechanism, enabling precise determination of the direction of transformation. Experimental results show the superiority of the proposed method over previous approaches, underscoring its effectiveness in addressing the challenges of image provenance analysis.
Open-Set Deepfake Detection: A Parameter-Efficient Adaptation Method with Forgery Style Mixture
Aug 23, 2024



Open-set face forgery detection poses significant security threats and presents substantial challenges for existing detection models. These detectors primarily have two limitations: they cannot generalize across unknown forgery domains and inefficiently adapt to new data. To address these issues, we introduce an approach that is both general and parameter-efficient for face forgery detection. It builds on the assumption that different forgery source domains exhibit distinct style statistics. Previous methods typically require fully fine-tuning pre-trained networks, consuming substantial time and computational resources. In turn, we design a forgery-style mixture formulation that augments the diversity of forgery source domains, enhancing the model's generalizability across unseen domains. Drawing on recent advancements in vision transformers (ViT) for face forgery detection, we develop a parameter-efficient ViT-based detection model that includes lightweight forgery feature extraction modules and enables the model to extract global and local forgery clues simultaneously. We only optimize the inserted lightweight modules during training, maintaining the original ViT structure with its pre-trained ImageNet weights. This training strategy effectively preserves the informative pre-trained knowledge while flexibly adapting the model to the task of Deepfake detection. Extensive experimental results demonstrate that the designed model achieves state-of-the-art generalizability with significantly reduced trainable parameters, representing an important step toward open-set Deepfake detection in the wild.
Robust Domain Misinformation Detection via Multi-modal Feature Alignment
Nov 24, 2023



Social media misinformation harms individuals and societies and is potentialized by fast-growing multi-modal content (i.e., texts and images), which accounts for higher "credibility" than text-only news pieces. Although existing supervised misinformation detection methods have obtained acceptable performances in key setups, they may require large amounts of labeled data from various events, which can be time-consuming and tedious. In turn, directly training a model by leveraging a publicly available dataset may fail to generalize due to domain shifts between the training data (a.k.a. source domains) and the data from target domains. Most prior work on domain shift focuses on a single modality (e.g., text modality) and ignores the scenario where sufficient unlabeled target domain data may not be readily available in an early stage. The lack of data often happens due to the dynamic propagation trend (i.e., the number of posts related to fake news increases slowly before catching the public attention). We propose a novel robust domain and cross-modal approach (\textbf{RDCM}) for multi-modal misinformation detection. It reduces the domain shift by aligning the joint distribution of textual and visual modalities through an inter-domain alignment module and bridges the semantic gap between both modalities through a cross-modality alignment module. We also propose a framework that simultaneously considers application scenarios of domain generalization (in which the target domain data is unavailable) and domain adaptation (in which unlabeled target domain data is available). Evaluation results on two public multi-modal misinformation detection datasets (Pheme and Twitter Datasets) evince the superiority of the proposed model. The formal implementation of this paper can be found in this link: https://github.com/less-and-less-bugs/RDCM