 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling Electric Vehicles via Early Charging Voltage Patterns
Jun 09, 2025Electric Vehicles (EVs) are rapidly gaining adoption as a sustainable alternative to fuel-powered vehicles, making secure charging infrastructure essential. Despite traditional authentication protocols, recent results showed that attackers may steal energy through tailored relay attacks. One countermeasure is leveraging the EV's fingerprint on the current exchanged during charging. However, existing methods focus on the final charging stage, allowing malicious actors to consume substantial energy before being detected and repudiated. This underscores the need for earlier and more effective authentication methods to prevent unauthorized charging. Meanwhile, profiling raises privacy concerns, as uniquely identifying EVs through charging patterns could enable user tracking. In this paper, we propose a framework for uniquely identifying EVs using physical measurements from the early charging stages. We hypothesize that voltage behavior early in the process exhibits similar characteristics to current behavior in later stages. By extracting features from early voltage measurements, we demonstrate the feasibility of EV profiling. Our approach improves existing methods by enabling faster and more reliable vehicle identification. We test our solution on a dataset of 7408 usable charges from 49 EVs, achieving up to 0.86 accuracy. Feature importance analysis shows that near-optimal performance is possible with just 10 key features, improving efficiency alongside our lightweight models. This research lays the foundation for a novel authentication factor while exposing potential privacy risks from unauthorized access to charging data.
SimProcess: High Fidelity Simulation of Noisy ICS Physical Processes
May 28, 2025Industrial Control Systems (ICS) manage critical infrastructures like power grids and water treatment plants. Cyberattacks on ICSs can disrupt operations, causing severe economic, environmental, and safety issues. For example, undetected pollution in a water plant can put the lives of thousands at stake. ICS researchers have increasingly turned to honeypots -- decoy systems designed to attract attackers, study their behaviors, and eventually improve defensive mechanisms. However, existing ICS honeypots struggle to replicate the ICS physical process, making them susceptible to detection. Accurately simulating the noise in ICS physical processes is challenging because different factors produce it, including sensor imperfections and external interferences. In this paper, we propose SimProcess, a novel framework to rank the fidelity of ICS simulations by evaluating how closely they resemble real-world and noisy physical processes. It measures the simulation distance from a target system by estimating the noise distribution with machine learning models like Random Forest. Unlike existing solutions that require detailed mathematical models or are limited to simple systems, SimProcess operates with only a timeseries of measurements from the real system, making it applicable to a broader range of complex dynamic systems. We demonstrate the framework's effectiveness through a case study using real-world power grid data from the EPIC testbed. We compare the performance of various simulation methods, including static and generative noise techniques. Our model correctly classifies real samples with a recall of up to 1.0. It also identifies Gaussian and Gaussian Mixture as the best distribution to simulate our power systems, together with a generative solution provided by an autoencoder, thereby helping developers to improve honeypot fidelity. Additionally, we make our code publicly available.
WeiDetect: Weibull Distribution-Based Defense against Poisoning Attacks in Federated Learning for Network Intrusion Detection Systems
Apr 06, 2025In the era of data expansion, ensuring data privacy has become increasingly critical, posing significant challenges to traditional AI-based applications. In addition, the increasing adoption of IoT devices has introduced significant cybersecurity challenges, making traditional Network Intrusion Detection Systems (NIDS) less effective against evolving threats, and privacy concerns and regulatory restrictions limit their deployment. Federated Learning (FL) has emerged as a promising solution, allowing decentralized model training while maintaining data privacy to solve these issues. However, despite implementing privacy-preserving technologies, FL systems remain vulnerable to adversarial attacks. Furthermore, data distribution among clients is not heterogeneous in the FL scenario. We propose WeiDetect, a two-phase, server-side defense mechanism for FL-based NIDS that detects malicious participants to address these challenges. In the first phase, local models are evaluated using a validation dataset to generate validation scores. These scores are then analyzed using a Weibull distribution, identifying and removing malicious models. We conducted experiments to evaluate the effectiveness of our approach in diverse attack settings. Our evaluation included two popular datasets, CIC-Darknet2020 and CSE-CIC-IDS2018, tested under non-IID data distributions. Our findings highlight that WeiDetect outperforms state-of-the-art defense approaches, improving higher target class recall up to 70% and enhancing the global model's F1 score by 1% to 14%.
TeLL Me what you cant see
Mar 25, 2025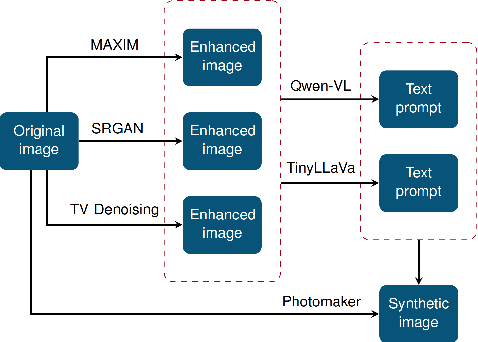

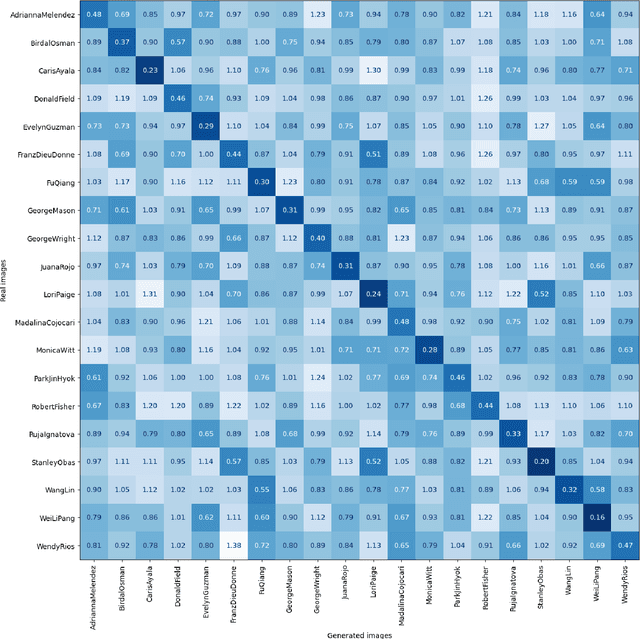
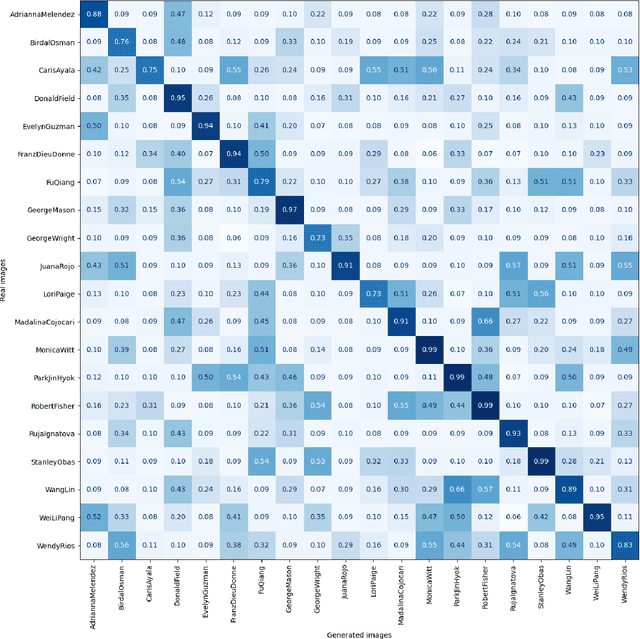
During criminal investigations, images of persons of interest directly influence the success of identification procedures. However, law enforcement agencies often face challenges related to the scarcity of high-quality images or their obsolescence, which can affect the accuracy and success of people searching processes. This paper introduces a novel forensic mugshot augmentation framework aimed at addressing these limitations. Our approach enhances the identification probability of individuals by generating additional, high-quality images through customizable data augmentation techniques, while maintaining the biometric integrity and consistency of the original data. Several experimental results show that our method significantly improves identification accuracy and robustness across various forensic scenarios, demonstrating its effectiveness as a trustworthy tool law enforcement applications. Index Terms: Digital Forensics, Person re-identification, Feature extraction, Data augmentation, Visual-Language models.
Towards Robust Stability Prediction in Smart Grids: GAN-based Approach under Data Constraints and Adversarial Challenges
Jan 27, 2025



Smart grids are critical for addressing the growing energy demand due to global population growth and urbanization. They enhance efficiency, reliability, and sustainability by integrating renewable energy. Ensuring their availability and safety requires advanced operational control and safety measures. Researchers employ AI and machine learning to assess grid stability, but challenges like the lack of datasets and cybersecurity threats, including adversarial attacks, persist. In particular, data scarcity is a key issue: obtaining grid instability instances is tough due to the need for significant expertise, resources, and time. However, they are essential to test novel research advancements and security mitigations. In this paper, we introduce a novel framework to detect instability in smart grids by employing only stable data. It relies on a Generative Adversarial Network (GAN) where the generator is trained to create instability data that are used along with stable data to train the discriminator. Moreover, we include a new adversarial training layer to improve robustness against adversarial attacks. Our solution, tested on a dataset composed of real-world stable and unstable samples, achieve accuracy up to 97.5\% in predicting grid stability and up to 98.9\% in detecting adversarial attacks. Moreover, we implemented our model in a single-board computer demonstrating efficient real-time decision-making with an average response time of less than 7ms. Our solution improves prediction accuracy and resilience while addressing data scarcity in smart grid management.
IntellBot: Retrieval Augmented LLM Chatbot for Cyber Threat Knowledge Delivery
Nov 08, 2024In the rapidly evolving landscape of cyber security, intelligent chatbots are gaining prominence. Artificial Intelligence, Machine Learning, and Natural Language Processing empower these chatbots to handle user inquiries and deliver threat intelligence. This helps cyber security knowledge readily available to both professionals and the public. Traditional rule-based chatbots often lack flexibility and struggle to adapt to user interactions. In contrast, Large Language Model-based chatbots offer contextually relevant information across multiple domains and adapt to evolving conversational contexts. In this work, we develop IntellBot, an advanced cyber security Chatbot built on top of cutting-edge technologies like Large Language Models and Langchain alongside a Retrieval-Augmented Generation model to deliver superior capabilities. This chatbot gathers information from diverse data sources to create a comprehensive knowledge base covering known vulnerabilities, recent cyber attacks, and emerging threats. It delivers tailored responses, serving as a primary hub for cyber security insights. By providing instant access to relevant information and resources, this IntellBot enhances threat intelligence, incident response, and overall security posture, saving time and empowering users with knowledge of cyber security best practices. Moreover, we analyzed the performance of our copilot using a two-stage evaluation strategy. We achieved BERT score above 0.8 by indirect approach and a cosine similarity score ranging from 0.8 to 1, which affirms the accuracy of our copilot. Additionally, we utilized RAGAS to evaluate the RAG model, and all evaluation metrics consistently produced scores above 0.77, highlighting the efficacy of our system.
Membership Privacy Evaluation in Deep Spiking Neural Networks
Sep 28, 2024



Artificial Neural Networks (ANNs), commonly mimicking neurons with non-linear functions to output floating-point numbers, consistently receive the same signals of a data point during its forward time. Unlike ANNs, Spiking Neural Networks (SNNs) get various input signals in the forward time of a data point and simulate neurons in a biologically plausible way, i.e., producing a spike (a binary value) if the accumulated membrane potential of a neuron is larger than a threshold. Even though ANNs have achieved remarkable success in multiple tasks, e.g., face recognition and object detection, SNNs have recently obtained attention due to their low power consumption, fast inference, and event-driven properties. While privacy threats against ANNs are widely explored, much less work has been done on SNNs. For instance, it is well-known that ANNs are vulnerable to the Membership Inference Attack (MIA), but whether the same applies to SNNs is not explored. In this paper, we evaluate the membership privacy of SNNs by considering eight MIAs, seven of which are inspired by MIAs against ANNs. Our evaluation results show that SNNs are more vulnerable (maximum 10% higher in terms of balanced attack accuracy) than ANNs when both are trained with neuromorphic datasets (with time dimension). On the other hand, when training ANNs or SNNs with static datasets (without time dimension), the vulnerability depends on the dataset used. If we convert ANNs trained with static datasets to SNNs, the accuracy of MIAs drops (maximum 11.5% with a reduction of 7.6% on the test accuracy of the target model). Next, we explore the impact factors of MIAs on SNNs by conducting a hyperparameter study. Finally, we show that the basic data augmentation method for static data and two recent data augmentation methods for neuromorphic data can considerably (maximum reduction of 25.7%) decrease MIAs' performance on SNNs.
Subject Data Auditing via Source Inference Attack in Cross-Silo Federated Learning
Sep 28, 2024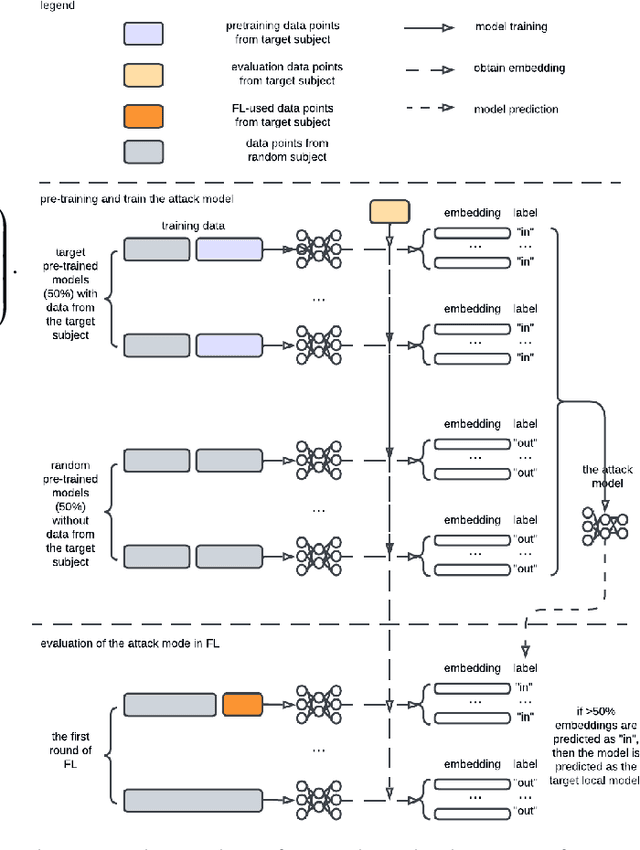

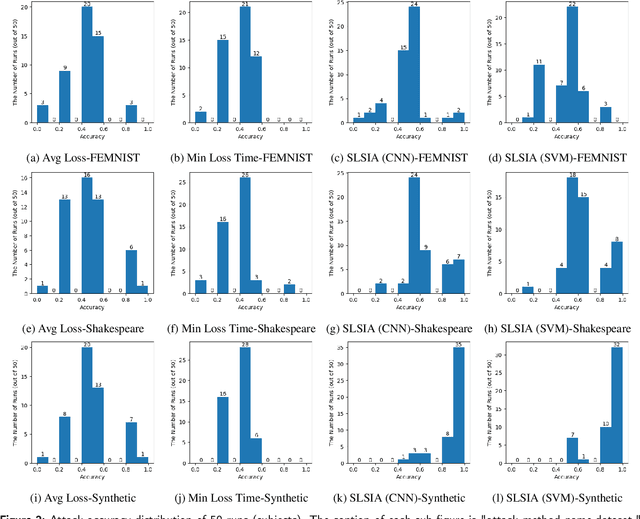

Source Inference Attack (SIA) in Federated Learning (FL) aims to identify which client used a target data point for local model training. It allows the central server to audit clients' data usage. In cross-silo FL, a client (silo) collects data from multiple subjects (e.g., individuals, writers, or devices), posing a risk of subject information leakage. Subject Membership Inference Attack (SMIA) targets this scenario and attempts to infer whether any client utilizes data points from a target subject in cross-silo FL. However, existing results on SMIA are limited and based on strong assumptions on the attack scenario. Therefore, we propose a Subject-Level Source Inference Attack (SLSIA) by removing critical constraints that only one client can use a target data point in SIA and imprecise detection of clients utilizing target subject data in SMIA. The attacker, positioned on the server side, controls a target data source and aims to detect all clients using data points from the target subject. Our strategy leverages a binary attack classifier to predict whether the embeddings returned by a local model on test data from the target subject include unique patterns that indicate a client trains the model with data from that subject. To achieve this, the attacker locally pre-trains models using data derived from the target subject and then leverages them to build a training set for the binary attack classifier. Our SLSIA significantly outperforms previous methods on three datasets. Specifically, SLSIA achieves a maximum average accuracy of 0.88 over 50 target subjects. Analyzing embedding distribution and input feature distance shows that datasets with sparse subjects are more susceptible to our attack. Finally, we propose to defend our SLSIA using item-level and subject-level differential privacy mechanisms.
Effectiveness of learning-based image codecs on fingerprint storage
Sep 27, 2024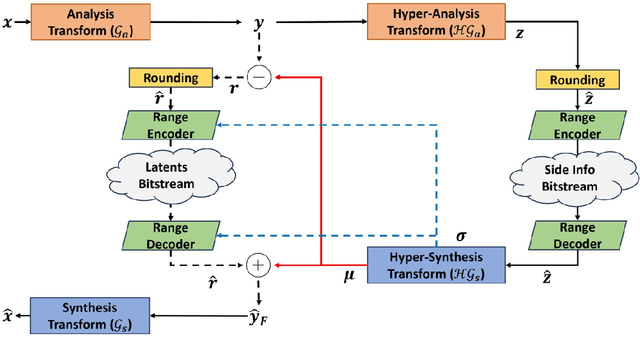

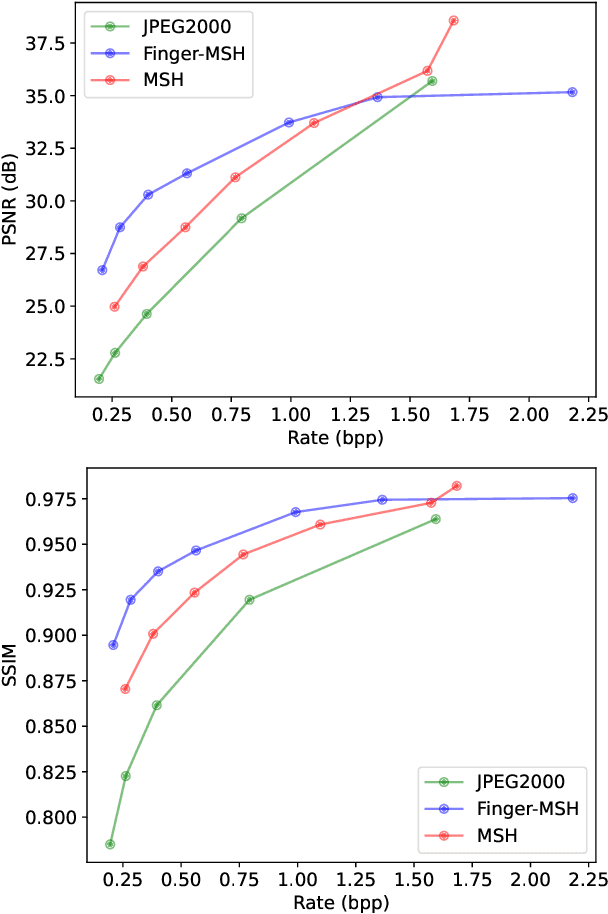
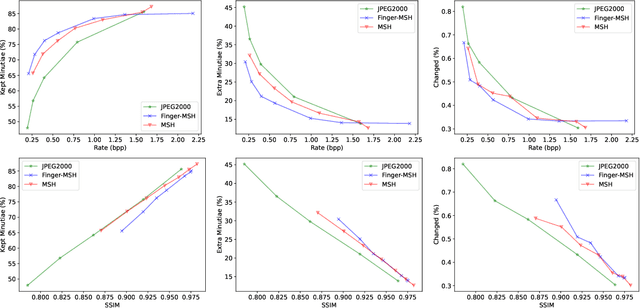
The success of learning-based coding techniques and the development of learning-based image coding standards, such as JPEG-AI, point towards the adoption of such solutions in different fields, including the storage of biometric data, like fingerprints. However, the peculiar nature of learning-based compression artifacts poses several issues concerning their impact and effectiveness on extracting biometric features and landmarks, e.g., minutiae. This problem is utterly stressed by the fact that most models are trained on natural color images, whose characteristics are very different from usual biometric images, e.g, fingerprint or iris pictures. As a matter of fact, these issues are deemed to be accurately questioned and investigated, being such analysis still largely unexplored. This study represents the first investigation about the adaptability of learning-based image codecs in the storage of fingerprint images by measuring its impact on the extraction and characterization of minutiae. Experimental results show that at a fixed rate point, learned solutions considerably outperform previous fingerprint coding standards, like JPEG2000, both in terms of distortion and minutiae preservation. Indeed, experimental results prove that the peculiarities of learned compression artifacts do not prevent automatic fingerprint identification (since minutiae types and locations are not significantly altered), nor do compromise image quality for human visual inspection (as they gain in terms of BD rate and PSNR of 47.8% and +3.97dB respectively).
MoRSE: Bridging the Gap in Cybersecurity Expertise with Retrieval Augmented Generation
Jul 22, 2024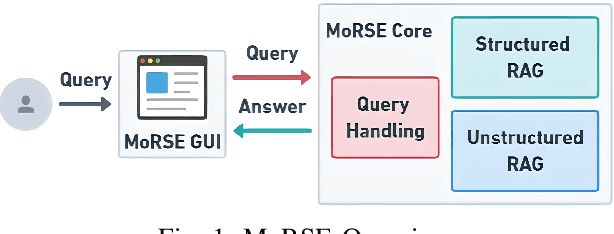
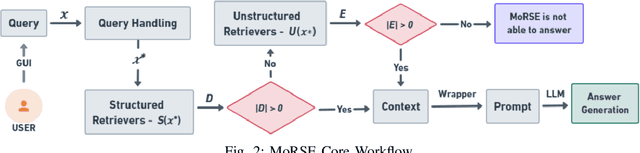
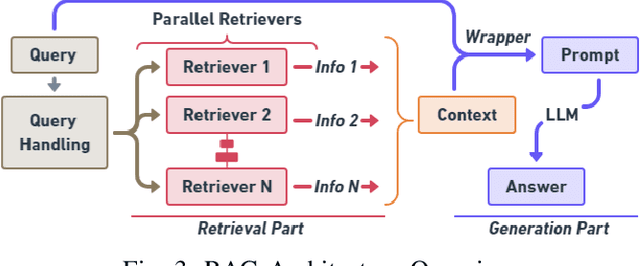
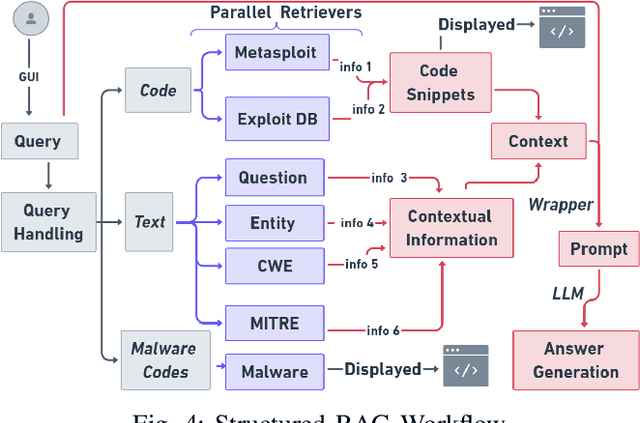
In this paper, we introduce MoRSE (Mixture of RAGs Security Experts), the first specialised AI chatbot for cybersecurity. MoRSE aims to provide comprehensive and complete knowledge about cybersecurity. MoRSE uses two RAG (Retrieval Augmented Generation) systems designed to retrieve and organize information from multidimensional cybersecurity contexts. MoRSE differs from traditional RAGs by using parallel retrievers that work together to retrieve semantically related information in different formats and structures. Unlike traditional Large Language Models (LLMs) that rely on Parametric Knowledge Bases, MoRSE retrieves relevant documents from Non-Parametric Knowledge Bases in response to user queries. Subsequently, MoRSE uses this information to generate accurate answers. In addition, MoRSE benefits from real-time updates to its knowledge bases, enabling continuous knowledge enrichment without retraining. We have evaluated the effectiveness of MoRSE against other state-of-the-art LLMs, evaluating the system on 600 cybersecurity specific questions. The experimental evaluation has shown that the improvement in terms of relevance and correctness of the answer is more than 10\% compared to known solutions such as GPT-4 and Mixtral 7x8.