 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling Electric Vehicles via Early Charging Voltage Patterns
Jun 09, 2025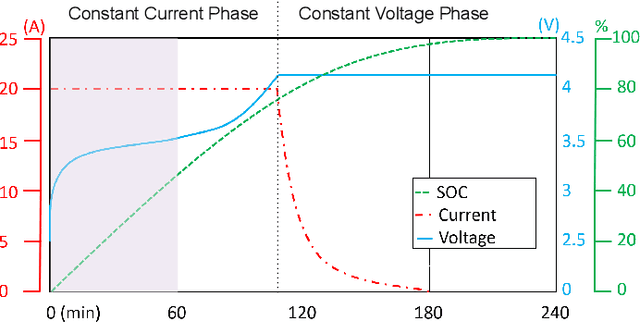


Electric Vehicles (EVs) are rapidly gaining adoption as a sustainable alternative to fuel-powered vehicles, making secure charging infrastructure essential. Despite traditional authentication protocols, recent results showed that attackers may steal energy through tailored relay attacks. One countermeasure is leveraging the EV's fingerprint on the current exchanged during charging. However, existing methods focus on the final charging stage, allowing malicious actors to consume substantial energy before being detected and repudiated. This underscores the need for earlier and more effective authentication methods to prevent unauthorized charging. Meanwhile, profiling raises privacy concerns, as uniquely identifying EVs through charging patterns could enable user tracking. In this paper, we propose a framework for uniquely identifying EVs using physical measurements from the early charging stages. We hypothesize that voltage behavior early in the process exhibits similar characteristics to current behavior in later stages. By extracting features from early voltage measurements, we demonstrate the feasibility of EV profiling. Our approach improves existing methods by enabling faster and more reliable vehicle identification. We test our solution on a dataset of 7408 usable charges from 49 EVs, achieving up to 0.86 accuracy. Feature importance analysis shows that near-optimal performance is possible with just 10 key features, improving efficiency alongside our lightweight models. This research lays the foundation for a novel authentication factor while exposing potential privacy risks from unauthorized access to charging data.
Moshi Moshi? A Model Selection Hijacking Adversarial Attack
Feb 20, 2025Model selection is a fundamental task in Machine Learning~(ML), focusing on selecting the most suitable model from a pool of candidates by evaluating their performance on specific metrics. This process ensures optimal performance, computational efficiency, and adaptability to diverse tasks and environments. Despite its critical role, its security from the perspective of adversarial ML remains unexplored. This risk is heightened in the Machine-Learning-as-a-Service model, where users delegate the training phase and the model selection process to third-party providers, supplying data and training strategies. Therefore, attacks on model selection could harm both the user and the provider, undermining model performance and driving up operational costs. In this work, we present MOSHI (MOdel Selection HIjacking adversarial attack), the first adversarial attack specifically targeting model selection. Our novel approach manipulates model selection data to favor the adversary, even without prior knowledge of the system. Utilizing a framework based on Variational Auto Encoders, we provide evidence that an attacker can induce inefficiencies in ML deployment. We test our attack on diverse computer vision and speech recognition benchmark tasks and different settings, obtaining an average attack success rate of 75.42%. In particular, our attack causes an average 88.30% decrease in generalization capabilities, an 83.33% increase in latency, and an increase of up to 105.85% in energy consumption. These results highlight the significant vulnerabilities in model selection processes and their potential impact on real-world applications.
Can LLMs Understand Computer Networks? Towards a Virtual System Administrator
Apr 19, 2024



Recent advancements in Artificial Intelligence, and particularly Large Language Models (LLMs), offer promising prospects for aiding system administrators in managing the complexity of modern networks. However, despite this potential, a significant gap exists in the literature regarding the extent to which LLMs can understand computer networks. Without empirical evidence, system administrators might rely on these models without assurance of their efficacy in performing network-related tasks accurately. In this paper, we are the first to conduct an exhaustive study on LLMs' comprehension of computer networks. We formulate several research questions to determine whether LLMs can provide correct answers when supplied with a network topology and questions on it. To assess them, we developed a thorough framework for evaluating LLMs' capabilities in various network-related tasks. We evaluate our framework on multiple computer networks employing private (e.g., GPT4) and open-source (e.g., Llama2) models. Our findings demonstrate promising results, with the best model achieving an average accuracy of 79.3%. Private LLMs achieve noteworthy results in small and medium networks, while challenges persist in comprehending complex network topologies, particularly for open-source models. Moreover, we provide insight into how prompt engineering can enhance the accuracy of some tasks.
FaultGuard: A Generative Approach to Resilient Fault Prediction in Smart Electrical Grids
Mar 26, 2024Predicting and classifying faults in electricity networks is crucial for uninterrupted provision and keeping maintenance costs at a minimum. Thanks to the advancements in the field provided by the smart grid, several data-driven approaches have been proposed in the literature to tackle fault prediction tasks. Implementing these systems brought several improvements, such as optimal energy consumption and quick restoration. Thus, they have become an essential component of the smart grid. However, the robustness and security of these systems against adversarial attacks have not yet been extensively investigated. These attacks can impair the whole grid and cause additional damage to the infrastructure, deceiving fault detection systems and disrupting restoration. In this paper, we present FaultGuard, the first framework for fault type and zone classification resilient to adversarial attacks. To ensure the security of our system, we employ an Anomaly Detection System (ADS) leveraging a novel Generative Adversarial Network training layer to identify attacks. Furthermore, we propose a low-complexity fault prediction model and an online adversarial training technique to enhance robustness. We comprehensively evaluate the framework's performance against various adversarial attacks using the IEEE13-AdvAttack dataset, which constitutes the state-of-the-art for resilient fault prediction benchmarking. Our model outclasses the state-of-the-art even without considering adversaries, with an accuracy of up to 0.958. Furthermore, our ADS shows attack detection capabilities with an accuracy of up to 1.000. Finally, we demonstrate how our novel training layers drastically increase performances across the whole framework, with a mean increase of 154% in ADS accuracy and 118% in model accuracy.
AGIR: Automating Cyber Threat Intelligence Reporting with Natural Language Generation
Oct 04, 2023Cyber Threat Intelligence (CTI) reporting is pivotal in contemporary risk management strategies. As the volume of CTI reports continues to surge, the demand for automated tools to streamline report generation becomes increasingly apparent. While Natural Language Processing techniques have shown potential in handling text data, they often struggle to address the complexity of diverse data sources and their intricate interrelationships. Moreover, established paradigms like STIX have emerged as de facto standards within the CTI community, emphasizing the formal categorization of entities and relations to facilitate consistent data sharing. In this paper, we introduce AGIR (Automatic Generation of Intelligence Reports), a transformative Natural Language Generation tool specifically designed to address the pressing challenges in the realm of CTI reporting. AGIR's primary objective is to empower security analysts by automating the labor-intensive task of generating comprehensive intelligence reports from formal representations of entity graphs. AGIR utilizes a two-stage pipeline by combining the advantages of template-based approaches and the capabilities of Large Language Models such as ChatGPT. We evaluate AGIR's report generation capabilities both quantitatively and qualitatively. The generated reports accurately convey information expressed through formal language, achieving a high recall value (0.99) without introducing hallucination. Furthermore, we compare the fluency and utility of the reports with state-of-the-art approaches, showing how AGIR achieves higher scores in terms of Syntactic Log-Odds Ratio (SLOR) and through questionnaires. By using our tool, we estimate that the report writing time is reduced by more than 40%, therefore streamlining the CTI production of any organization and contributing to the automation of several CTI tasks.
Your Battery Is a Blast! Safeguarding Against Counterfeit Batteries with Authentication
Sep 07, 2023

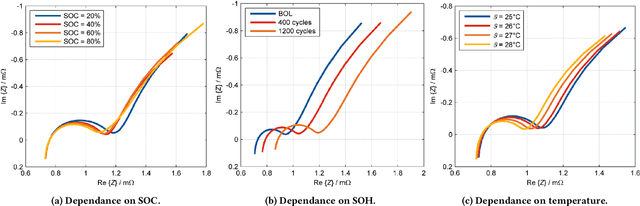
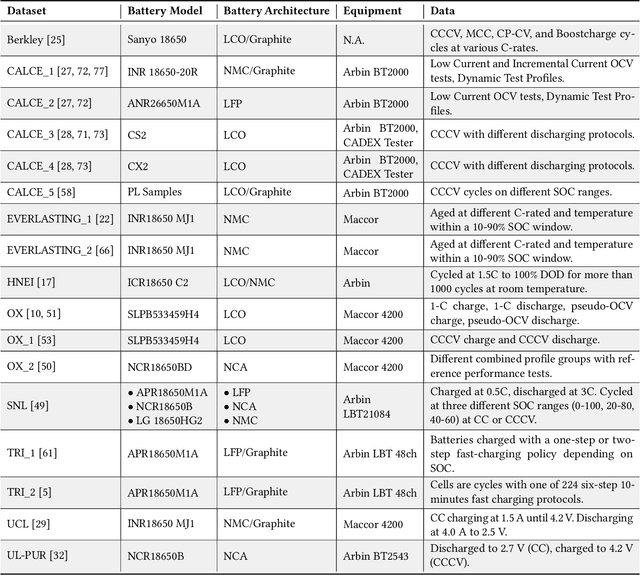
Lithium-ion (Li-ion) batteries are the primary power source in various applications due to their high energy and power density. Their market was estimated to be up to 48 billion U.S. dollars in 2022. However, the widespread adoption of Li-ion batteries has resulted in counterfeit cell production, which can pose safety hazards to users. Counterfeit cells can cause explosions or fires, and their prevalence in the market makes it difficult for users to detect fake cells. Indeed, current battery authentication methods can be susceptible to advanced counterfeiting techniques and are often not adaptable to various cells and systems. In this paper, we improve the state of the art on battery authentication by proposing two novel methodologies, DCAuth and EISthentication, which leverage the internal characteristics of each cell through Machine Learning models. Our methods automatically authenticate lithium-ion battery models and architectures using data from their regular usage without the need for any external device. They are also resilient to the most common and critical counterfeit practices and can scale to several batteries and devices. To evaluate the effectiveness of our proposed methodologies, we analyze time-series data from a total of 20 datasets that we have processed to extract meaningful features for our analysis. Our methods achieve high accuracy in battery authentication for both architectures (up to 0.99) and models (up to 0.96). Moreover, our methods offer comparable identification performances. By using our proposed methodologies, manufacturers can ensure that devices only use legitimate batteries, guaranteeing the operational state of any system and safety measures for the users.
Your Attack Is Too DUMB: Formalizing Attacker Scenarios for Adversarial Transferability
Jun 27, 2023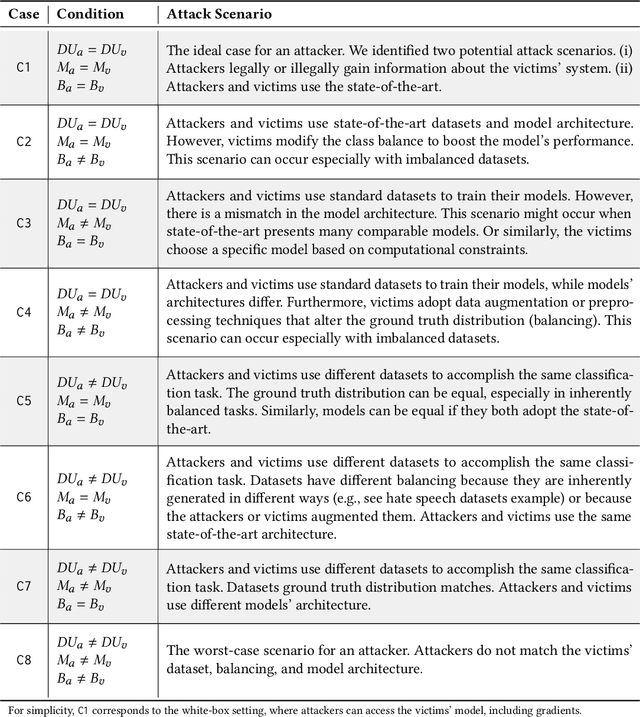
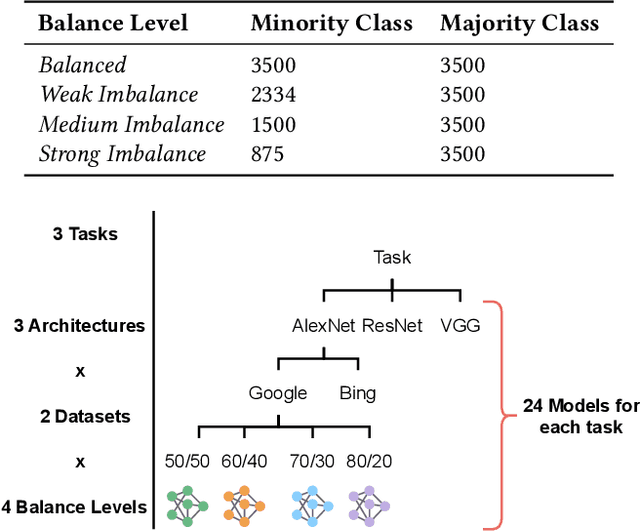
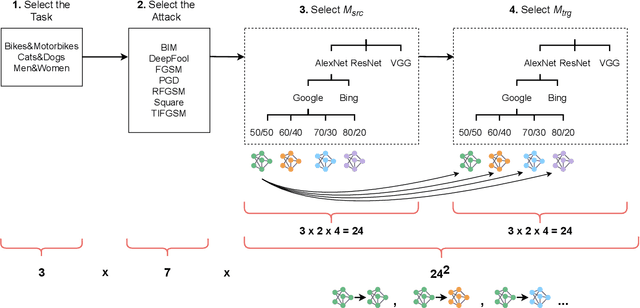
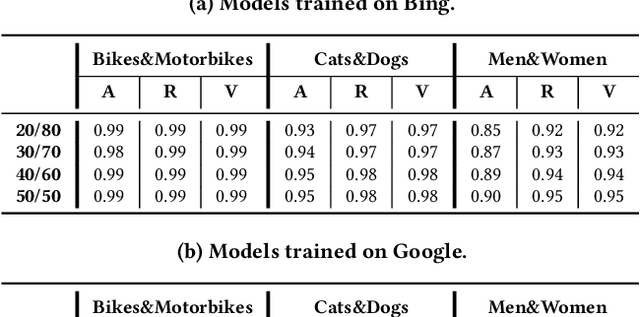
Evasion attacks are a threat to machine learning models, where adversaries attempt to affect classifiers by injecting malicious samples. An alarming side-effect of evasion attacks is their ability to transfer among different models: this property is called transferability. Therefore, an attacker can produce adversarial samples on a custom model (surrogate) to conduct the attack on a victim's organization later. Although literature widely discusses how adversaries can transfer their attacks, their experimental settings are limited and far from reality. For instance, many experiments consider both attacker and defender sharing the same dataset, balance level (i.e., how the ground truth is distributed), and model architecture. In this work, we propose the DUMB attacker model. This framework allows analyzing if evasion attacks fail to transfer when the training conditions of surrogate and victim models differ. DUMB considers the following conditions: Dataset soUrces, Model architecture, and the Balance of the ground truth. We then propose a novel testbed to evaluate many state-of-the-art evasion attacks with DUMB; the testbed consists of three computer vision tasks with two distinct datasets each, four types of balance levels, and three model architectures. Our analysis, which generated 13K tests over 14 distinct attacks, led to numerous novel findings in the scope of transferable attacks with surrogate models. In particular, mismatches between attackers and victims in terms of dataset source, balance levels, and model architecture lead to non-negligible loss of attack performance.
STIXnet: A Novel and Modular Solution for Extracting All STIX Objects in CTI Reports
Mar 17, 2023The automatic extraction of information from Cyber Threat Intelligence (CTI) reports is crucial in risk management. The increased frequency of the publications of these reports has led researchers to develop new systems for automatically recovering different types of entities and relations from textual data. Most state-of-the-art models leverage Natural Language Processing (NLP) techniques, which perform greatly in extracting a few types of entities at a time but cannot detect heterogeneous data or their relations. Furthermore, several paradigms, such as STIX, have become de facto standards in the CTI community and dictate a formal categorization of different entities and relations to enable organizations to share data consistently. This paper presents STIXnet, the first solution for the automated extraction of all STIX entities and relationships in CTI reports. Through the use of NLP techniques and an interactive Knowledge Base (KB) of entities, our approach obtains F1 scores comparable to state-of-the-art models for entity extraction (0.916) and relation extraction (0.724) while considering significantly more types of entities and relations. Moreover, STIXnet constitutes a modular and extensible framework that manages and coordinates different modules to merge their contributions uniquely and exhaustively. With our approach, researchers and organizations can extend their Information Extraction (IE) capabilities by integrating the efforts of several techniques without needing to develop new tools from scratch.