 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Beats to Breaches:How Offensive AI Infers Sensitive User Information from Playlists
May 06, 2026The pervasive integration of AI has enabled Offensive AI: the exploitation of AI for malicious ends across the cyber-kill chain. A critical manifestation is the user attribute inference attack, where AI infers sensitive Personally Identifiable Information (PII) from innocuous public data. We explore how music streaming ecosystems, where users routinely release public playlists, can be exploited for Offensive AI. To quantify this threat, we developed musicPIIrate. This novel tool leverages deep learning architectures that utilize both standalone data representations and the structural information embedded in a user's playlist collection. Our design explores set-based approaches (e.g., Deep Sets) and methodologies modeling relationships between playlists (e.g., Graph Neural Networks), which we also combine to leverage both perspectives. Our approach addresses feature extraction from unordered, variable-length set data, enabling accurate PII prediction. Empirical evaluation demonstrates that musicPIIrate achieves state-of-the-art inference accuracy. The tool successfully infers a wide array of attributes, including: Demographics (Age, Country, Gender), Habits (Alcohol, Smoke, Sport), and Personality Traits (OCEAN scores). musicPIIrate outperforms existing methods, beating baselines in 9 out of 15 attribute inference tasks. To counter this vulnerability, we propose JamShield, a lightweight defensive framework. JamShield strategically injects dummy playlists into an account to dilute the PII-carrying signal. Our analysis indicates that JamShield represents a promising defense, lowering inference F1-scores by an average of 10%. This work provides an initial Offensive-AI benchmark for playlist-based PII inference using architectures that leverage set- and graph-structured data and introduces a defense showing encouraging mitigation effects.
Moshi Moshi? A Model Selection Hijacking Adversarial Attack
Feb 20, 2025Model selection is a fundamental task in Machine Learning~(ML), focusing on selecting the most suitable model from a pool of candidates by evaluating their performance on specific metrics. This process ensures optimal performance, computational efficiency, and adaptability to diverse tasks and environments. Despite its critical role, its security from the perspective of adversarial ML remains unexplored. This risk is heightened in the Machine-Learning-as-a-Service model, where users delegate the training phase and the model selection process to third-party providers, supplying data and training strategies. Therefore, attacks on model selection could harm both the user and the provider, undermining model performance and driving up operational costs. In this work, we present MOSHI (MOdel Selection HIjacking adversarial attack), the first adversarial attack specifically targeting model selection. Our novel approach manipulates model selection data to favor the adversary, even without prior knowledge of the system. Utilizing a framework based on Variational Auto Encoders, we provide evidence that an attacker can induce inefficiencies in ML deployment. We test our attack on diverse computer vision and speech recognition benchmark tasks and different settings, obtaining an average attack success rate of 75.42%. In particular, our attack causes an average 88.30% decrease in generalization capabilities, an 83.33% increase in latency, and an increase of up to 105.85% in energy consumption. These results highlight the significant vulnerabilities in model selection processes and their potential impact on real-world applications.
Can LLMs Understand Computer Networks? Towards a Virtual System Administrator
Apr 19, 2024



Recent advancements in Artificial Intelligence, and particularly Large Language Models (LLMs), offer promising prospects for aiding system administrators in managing the complexity of modern networks. However, despite this potential, a significant gap exists in the literature regarding the extent to which LLMs can understand computer networks. Without empirical evidence, system administrators might rely on these models without assurance of their efficacy in performing network-related tasks accurately. In this paper, we are the first to conduct an exhaustive study on LLMs' comprehension of computer networks. We formulate several research questions to determine whether LLMs can provide correct answers when supplied with a network topology and questions on it. To assess them, we developed a thorough framework for evaluating LLMs' capabilities in various network-related tasks. We evaluate our framework on multiple computer networks employing private (e.g., GPT4) and open-source (e.g., Llama2) models. Our findings demonstrate promising results, with the best model achieving an average accuracy of 79.3%. Private LLMs achieve noteworthy results in small and medium networks, while challenges persist in comprehending complex network topologies, particularly for open-source models. Moreover, we provide insight into how prompt engineering can enhance the accuracy of some tasks.
"All of Me": Mining Users' Attributes from their Public Spotify Playlists
Jan 25, 2024In the age of digital music streaming, playlists on platforms like Spotify have become an integral part of individuals' musical experiences. People create and publicly share their own playlists to express their musical tastes, promote the discovery of their favorite artists, and foster social connections. These publicly accessible playlists transcend the boundaries of mere musical preferences: they serve as sources of rich insights into users' attributes and identities. For example, the musical preferences of elderly individuals may lean more towards Frank Sinatra, while Billie Eilish remains a favored choice among teenagers. These playlists thus become windows into the diverse and evolving facets of one's musical identity. In this work, we investigate the relationship between Spotify users' attributes and their public playlists. In particular, we focus on identifying recurring musical characteristics associated with users' individual attributes, such as demographics, habits, or personality traits. To this end, we conducted an online survey involving 739 Spotify users, yielding a dataset of 10,286 publicly shared playlists encompassing over 200,000 unique songs and 55,000 artists. Through extensive statistical analyses, we first assess a deep connection between a user's Spotify playlists and their real-life attributes. For instance, we found individuals high in openness often create playlists featuring a diverse array of artists, while female users prefer Pop and K-pop music genres. Building upon these observed associations, we create accurate predictive models for users' attributes, presenting a novel DeepSet application that outperforms baselines in most of these users' attributes.
Invisible Threats: Backdoor Attack in OCR Systems
Oct 12, 2023


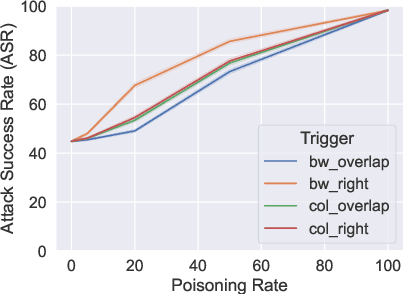
Optical Character Recognition (OCR) is a widely used tool to extract text from scanned documents. Today, the state-of-the-art is achieved by exploiting deep neural networks. However, the cost of this performance is paid at the price of system vulnerability. For instance, in backdoor attacks, attackers compromise the training phase by inserting a backdoor in the victim's model that will be activated at testing time by specific patterns while leaving the overall model performance intact. This work proposes a backdoor attack for OCR resulting in the injection of non-readable characters from malicious input images. This simple but effective attack exposes the state-of-the-art OCR weakness, making the extracted text correct to human eyes but simultaneously unusable for the NLP application that uses OCR as a preprocessing step. Experimental results show that the attacked models successfully output non-readable characters for around 90% of the poisoned instances without harming their performance for the remaining instances.
Your Attack Is Too DUMB: Formalizing Attacker Scenarios for Adversarial Transferability
Jun 27, 2023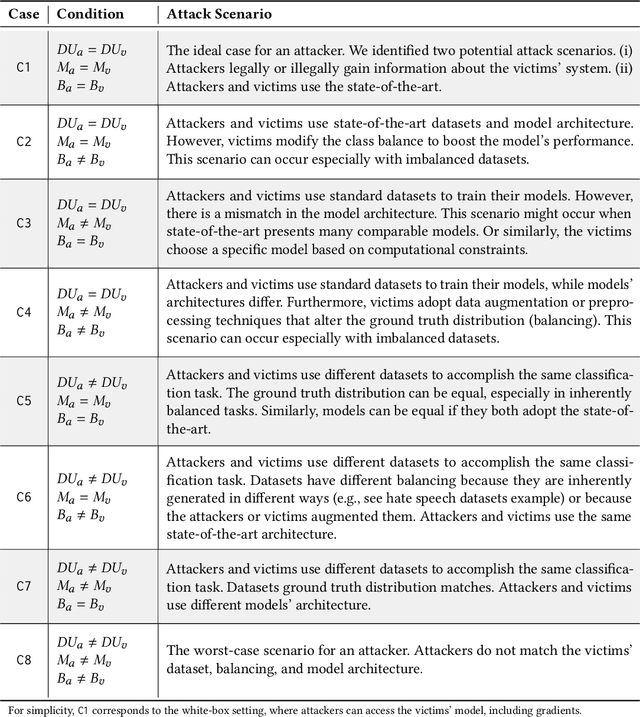
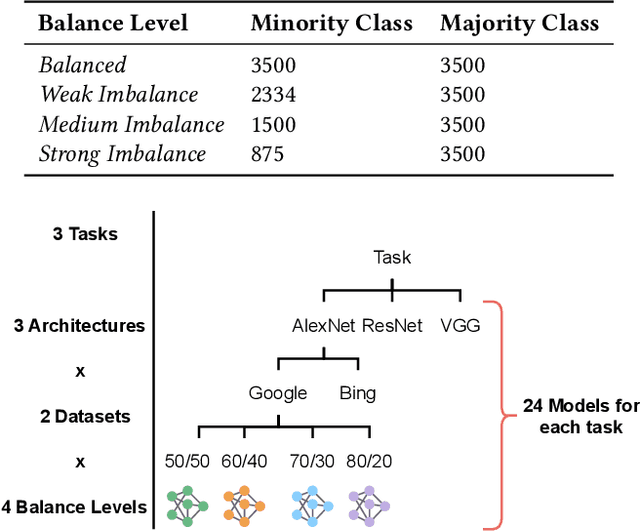
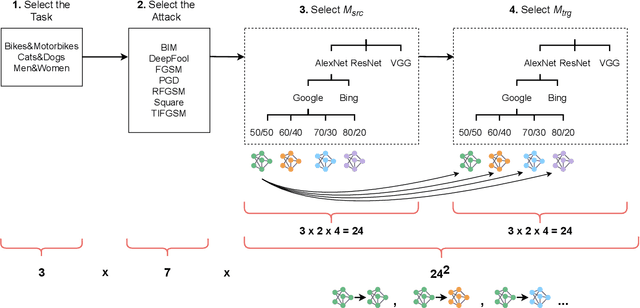
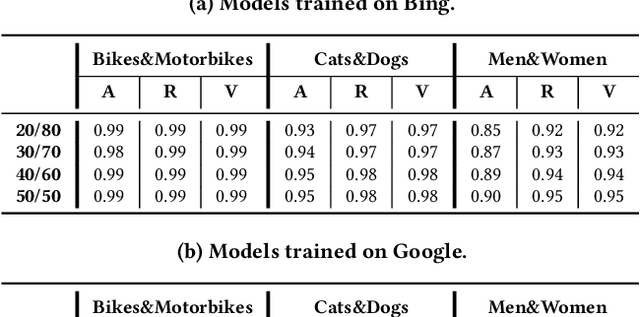
Evasion attacks are a threat to machine learning models, where adversaries attempt to affect classifiers by injecting malicious samples. An alarming side-effect of evasion attacks is their ability to transfer among different models: this property is called transferability. Therefore, an attacker can produce adversarial samples on a custom model (surrogate) to conduct the attack on a victim's organization later. Although literature widely discusses how adversaries can transfer their attacks, their experimental settings are limited and far from reality. For instance, many experiments consider both attacker and defender sharing the same dataset, balance level (i.e., how the ground truth is distributed), and model architecture. In this work, we propose the DUMB attacker model. This framework allows analyzing if evasion attacks fail to transfer when the training conditions of surrogate and victim models differ. DUMB considers the following conditions: Dataset soUrces, Model architecture, and the Balance of the ground truth. We then propose a novel testbed to evaluate many state-of-the-art evasion attacks with DUMB; the testbed consists of three computer vision tasks with two distinct datasets each, four types of balance levels, and three model architectures. Our analysis, which generated 13K tests over 14 distinct attacks, led to numerous novel findings in the scope of transferable attacks with surrogate models. In particular, mismatches between attackers and victims in terms of dataset source, balance levels, and model architecture lead to non-negligible loss of attack performance.
Boosting Big Brother: Attacking Search Engines with Encodings
Apr 27, 2023



Search engines are vulnerable to attacks against indexing and searching via text encoding manipulation. By imperceptibly perturbing text using uncommon encoded representations, adversaries can control results across search engines for specific search queries. We demonstrate that this attack is successful against two major commercial search engines - Google and Bing - and one open source search engine - Elasticsearch. We further demonstrate that this attack is successful against LLM chat search including Bing's GPT-4 chatbot and Google's Bard chatbot. We also present a variant of the attack targeting text summarization and plagiarism detection models, two ML tasks closely tied to search. We provide a set of defenses against these techniques and warn that adversaries can leverage these attacks to launch disinformation campaigns against unsuspecting users, motivating the need for search engine maintainers to patch deployed systems.
Social Honeypot for Humans: Luring People through Self-managed Instagram Pages
Mar 31, 2023



Social Honeypots are tools deployed in Online Social Networks (OSN) to attract malevolent activities performed by spammers and bots. To this end, their content is designed to be of maximum interest to malicious users. However, by choosing an appropriate content topic, this attractive mechanism could be extended to any OSN users, rather than only luring malicious actors. As a result, honeypots can be used to attract individuals interested in a wide range of topics, from sports and hobbies to more sensitive subjects like political views and conspiracies. With all these individuals gathered in one place, honeypot owners can conduct many analyses, from social to marketing studies. In this work, we introduce a novel concept of social honeypot for attracting OSN users interested in a generic target topic. We propose a framework based on fully-automated content generation strategies and engagement plans to mimic legit Instagram pages. To validate our framework, we created 21 self-managed social honeypots (i.e., pages) on Instagram, covering three topics, four content generation strategies, and three engaging plans. In nine weeks, our honeypots gathered a total of 753 followers, 5387 comments, and 15739 likes. These results demonstrate the validity of our approach, and through statistical analysis, we examine the characteristics of effective social honeypots.
Going In Style: Audio Backdoors Through Stylistic Transformations
Nov 11, 2022



A backdoor attack places triggers in victims' deep learning models to enable a targeted misclassification at testing time. In general, triggers are fixed artifacts attached to samples, making backdoor attacks easy to spot. Only recently, a new trigger generation harder to detect has been proposed: the stylistic triggers that apply stylistic transformations to the input samples (e.g., a specific writing style). Currently, stylistic backdoor literature lacks a proper formalization of the attack, which is established in this paper. Moreover, most studies of stylistic triggers focus on text and images, while there is no understanding of whether they can work in sound. This work fills this gap. We propose JingleBack, the first stylistic backdoor attack based on audio transformations such as chorus and gain. Using 444 models in a speech classification task, we confirm the feasibility of stylistic triggers in audio, achieving 96% attack success.
SoK: Explainable Machine Learning for Computer Security Applications
Aug 22, 2022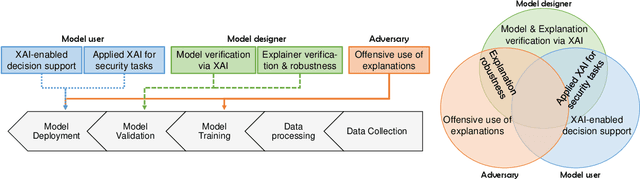

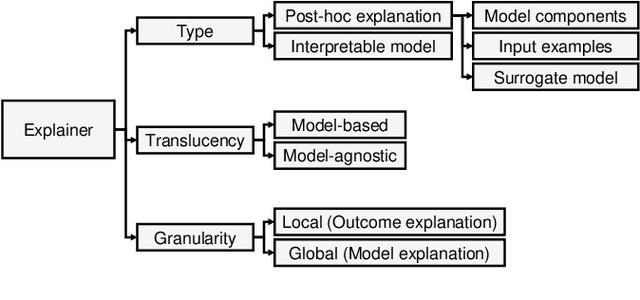
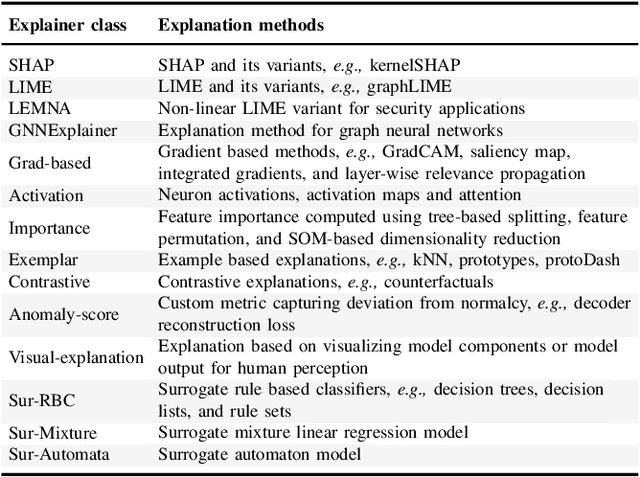
Explainable Artificial Intelligence (XAI) is a promising solution to improve the transparency of machine learning (ML) pipelines. We systematize the increasingly growing (but fragmented) microcosm of studies that develop and utilize XAI methods for defensive and offensive cybersecurity tasks. We identify 3 cybersecurity stakeholders, i.e., model users, designers, and adversaries, that utilize XAI for 5 different objectives within an ML pipeline, namely 1) XAI-enabled decision support, 2) applied XAI for security tasks, 3) model verification via XAI, 4) explanation verification & robustness, and 5) offensive use of explanations. We further classify the literature w.r.t. the targeted security domain. Our analysis of the literature indicates that many of the XAI applications are designed with little understanding of how they might be integrated into analyst workflows -- user studies for explanation evaluation are conducted in only 14% of the cases. The literature also rarely disentangles the role of the various stakeholders. Particularly, the role of the model designer is minimized within the security literature. To this end, we present an illustrative use case accentuating the role of model designers. We demonstrate cases where XAI can help in model verification and cases where it may lead to erroneous conclusions instead. The systematization and use case enable us to challenge several assumptions and present open problems that can help shape the future of XAI within cybersecurity