 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Interpretable Decision Tree Policies for Reinforcement Learning
Aug 21, 2024

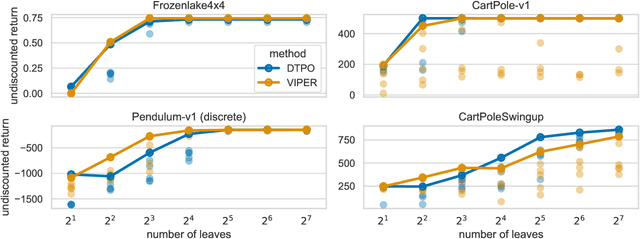

Reinforcement learning techniques leveraging deep learning have made tremendous progress in recent years. However, the complexity of neural networks prevents practitioners from understanding their behavior. Decision trees have gained increased attention in supervised learning for their inherent interpretability, enabling modelers to understand the exact prediction process after learning. This paper considers the problem of optimizing interpretable decision tree policies to replace neural networks in reinforcement learning settings. Previous works have relaxed the tree structure, restricted to optimizing only tree leaves, or applied imitation learning techniques to approximately copy the behavior of a neural network policy with a decision tree. We propose the Decision Tree Policy Optimization (DTPO) algorithm that directly optimizes the complete decision tree using policy gradients. Our technique uses established decision tree heuristics for regression to perform policy optimization. We empirically show that DTPO is a competitive algorithm compared to imitation learning algorithms for optimizing decision tree policies in reinforcement learning.
Differentially-Private Decision Trees with Probabilistic Robustness to Data Poisoning
May 24, 2023Decision trees are interpretable models that are well-suited to non-linear learning problems. Much work has been done on extending decision tree learning algorithms with differential privacy, a system that guarantees the privacy of samples within the training data. However, current state-of-the-art algorithms for this purpose sacrifice much utility for a small privacy benefit. These solutions create random decision nodes that reduce decision tree accuracy or spend an excessive share of the privacy budget on labeling leaves. Moreover, many works do not support or leak information about feature values when data is continuous. We propose a new method called PrivaTree based on private histograms that chooses good splits while consuming a small privacy budget. The resulting trees provide a significantly better privacy-utility trade-off and accept mixed numerical and categorical data without leaking additional information. Finally, while it is notoriously hard to give robustness guarantees against data poisoning attacks, we prove bounds for the expected success rates of backdoor attacks against differentially-private learners. Our experimental results show that PrivaTree consistently outperforms previous works on predictive accuracy and significantly improves robustness against backdoor attacks compared to regular decision trees.
Optimal Decision Tree Policies for Markov Decision Processes
Jan 30, 2023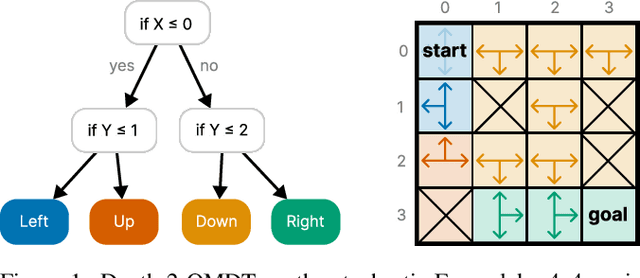

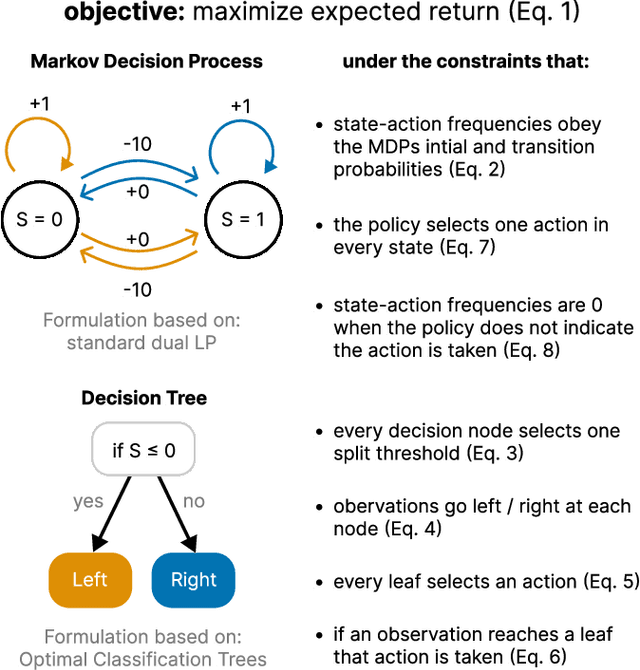
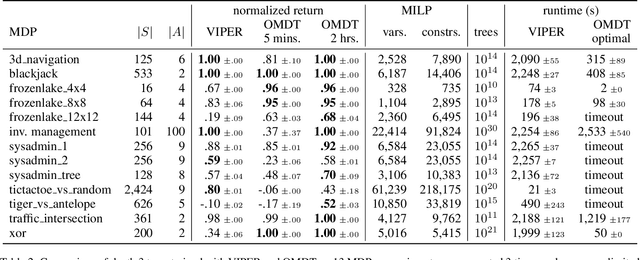
Interpretability of reinforcement learning policies is essential for many real-world tasks but learning such interpretable policies is a hard problem. Particularly rule-based policies such as decision trees and rules lists are difficult to optimize due to their non-differentiability. While existing techniques can learn verifiable decision tree policies there is no guarantee that the learners generate a decision that performs optimally. In this work, we study the optimization of size-limited decision trees for Markov Decision Processes (MPDs) and propose OMDTs: Optimal MDP Decision Trees. Given a user-defined size limit and MDP formulation OMDT directly maximizes the expected discounted return for the decision tree using Mixed-Integer Linear Programming. By training optimal decision tree policies for different MDPs we empirically study the optimality gap for existing imitation learning techniques and find that they perform sub-optimally. We show that this is due to an inherent shortcoming of imitation learning, namely that complex policies cannot be represented using size-limited trees. In such cases, it is better to directly optimize the tree for expected return. While there is generally a trade-off between the performance and interpretability of machine learning models, we find that OMDTs limited to a depth of 3 often perform close to the optimal limit.
SoK: Explainable Machine Learning for Computer Security Applications
Aug 22, 2022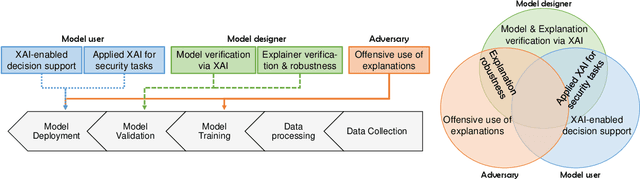

Explainable Artificial Intelligence (XAI) is a promising solution to improve the transparency of machine learning (ML) pipelines. We systematize the increasingly growing (but fragmented) microcosm of studies that develop and utilize XAI methods for defensive and offensive cybersecurity tasks. We identify 3 cybersecurity stakeholders, i.e., model users, designers, and adversaries, that utilize XAI for 5 different objectives within an ML pipeline, namely 1) XAI-enabled decision support, 2) applied XAI for security tasks, 3) model verification via XAI, 4) explanation verification & robustness, and 5) offensive use of explanations. We further classify the literature w.r.t. the targeted security domain. Our analysis of the literature indicates that many of the XAI applications are designed with little understanding of how they might be integrated into analyst workflows -- user studies for explanation evaluation are conducted in only 14% of the cases. The literature also rarely disentangles the role of the various stakeholders. Particularly, the role of the model designer is minimized within the security literature. To this end, we present an illustrative use case accentuating the role of model designers. We demonstrate cases where XAI can help in model verification and cases where it may lead to erroneous conclusions instead. The systematization and use case enable us to challenge several assumptions and present open problems that can help shape the future of XAI within cybersecurity
The First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022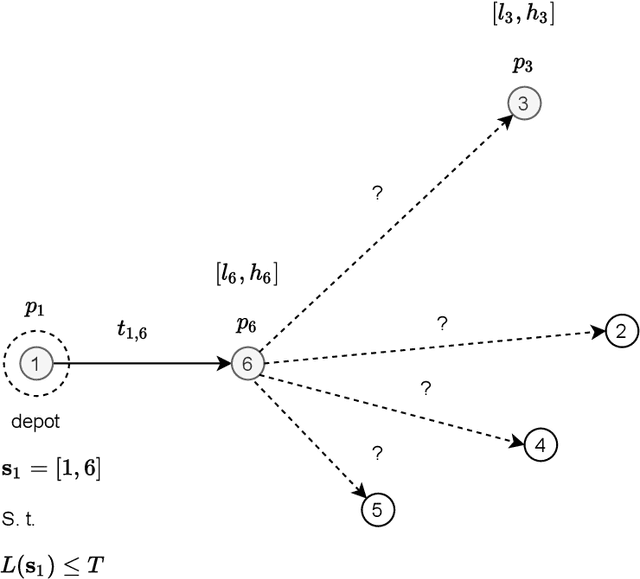
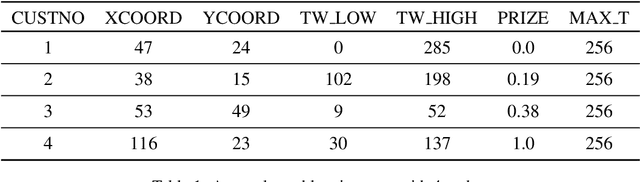

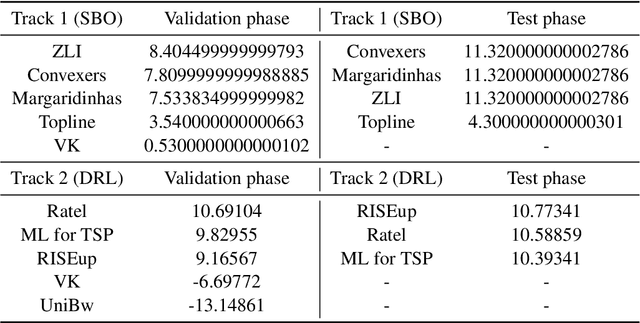
This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
Robust Optimal Classification Trees Against Adversarial Examples
Sep 08, 2021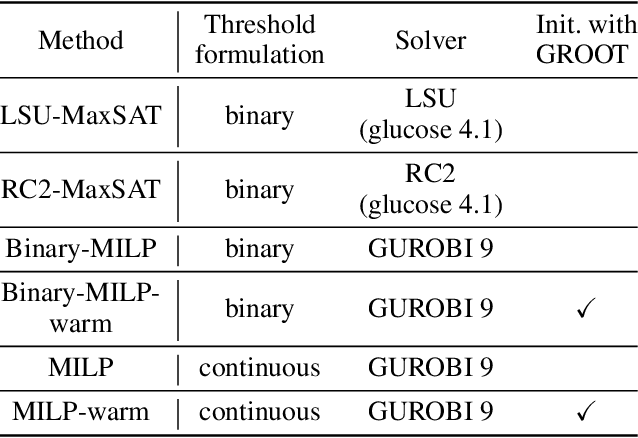
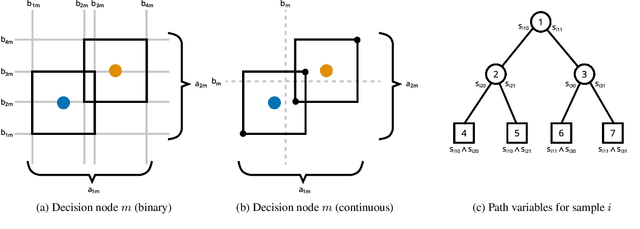

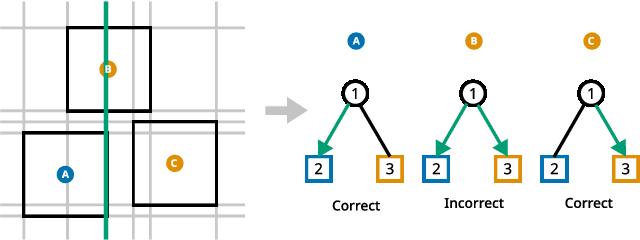
Decision trees are a popular choice of explainable model, but just like neural networks, they suffer from adversarial examples. Existing algorithms for fitting decision trees robust against adversarial examples are greedy heuristics and lack approximation guarantees. In this paper we propose ROCT, a collection of methods to train decision trees that are optimally robust against user-specified attack models. We show that the min-max optimization problem that arises in adversarial learning can be solved using a single minimization formulation for decision trees with 0-1 loss. We propose such formulations in Mixed-Integer Linear Programming and Maximum Satisfiability, which widely available solvers can optimize. We also present a method that determines the upper bound on adversarial accuracy for any model using bipartite matching. Our experimental results demonstrate that the existing heuristics achieve close to optimal scores while ROCT achieves state-of-the-art scores.
Efficient Training of Robust Decision Trees Against Adversarial Examples
Dec 18, 2020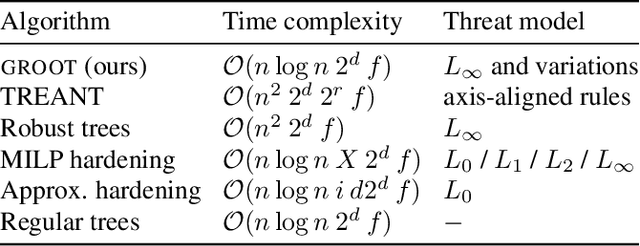
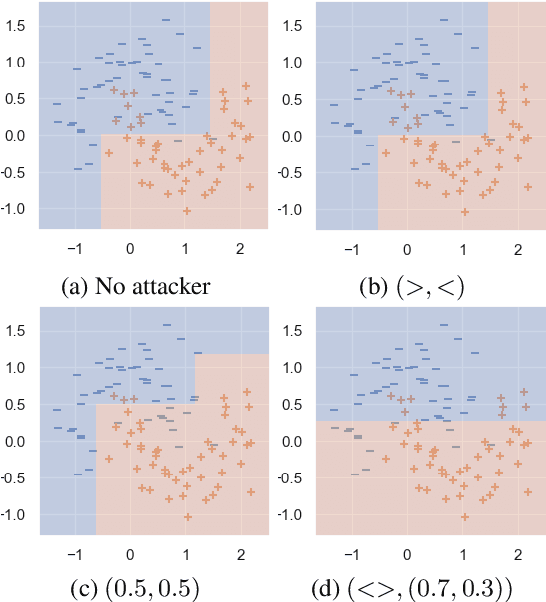
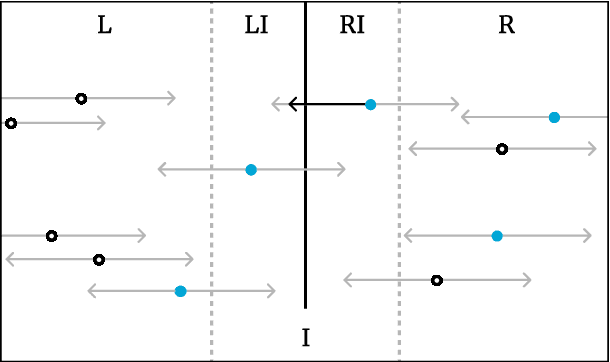
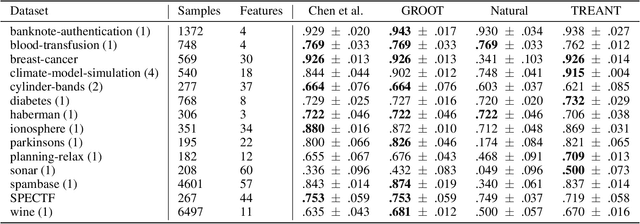
In the present day we use machine learning for sensitive tasks that require models to be both understandable and robust. Although traditional models such as decision trees are understandable, they suffer from adversarial attacks. When a decision tree is used to differentiate between a user's benign and malicious behavior, an adversarial attack allows the user to effectively evade the model by perturbing the inputs the model receives. We can use algorithms that take adversarial attacks into account to fit trees that are more robust. In this work we propose an algorithm, GROOT, that is two orders of magnitude faster than the state-of-the-art-work while scoring competitively on accuracy against adversaries. GROOT accepts an intuitive and permissible threat model. Where previous threat models were limited to distance norms, we allow each feature to be perturbed with a user-specified parameter: either a maximum distance or constraints on the direction of perturbation. Previous works assumed that both benign and malicious users attempt model evasion but we allow the user to select which classes perform adversarial attacks. Additionally, we introduce a hyperparameter rho that allows GROOT to trade off performance in the regular and adversarial settings.