 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning in a Combinatorial and Constrained World: Benchmarking LLMs on Natural-Language Combinatorial Optimization
Feb 02, 2026While large language models (LLMs) have shown strong performance in math and logic reasoning, their ability to handle combinatorial optimization (CO) -- searching high-dimensional solution spaces under hard constraints -- remains underexplored. To bridge the gap, we introduce NLCO, a \textbf{N}atural \textbf{L}anguage \textbf{C}ombinatorial \textbf{O}ptimization benchmark that evaluates LLMs on end-to-end CO reasoning: given a language-described decision-making scenario, the model must output a discrete solution without writing code or calling external solvers. NLCO covers 43 CO problems and is organized using a four-layer taxonomy of variable types, constraint families, global patterns, and objective classes, enabling fine-grained evaluation. We provide solver-annotated solutions and comprehensively evaluate LLMs by feasibility, solution optimality, and reasoning efficiency. Experiments across a wide range of modern LLMs show that high-performing models achieve strong feasibility and solution quality on small instances, but both degrade as instance size grows, even if more tokens are used for reasoning. We also observe systematic effects across the taxonomy: set-based tasks are relatively easy, whereas graph-structured problems and bottleneck objectives lead to more frequent failures.
Adversarial Instance Generation and Robust Training for Neural Combinatorial Optimization with Multiple Objectives
Jan 04, 2026Deep reinforcement learning (DRL) has shown great promise in addressing multi-objective combinatorial optimization problems (MOCOPs). Nevertheless, the robustness of these learning-based solvers has remained insufficiently explored, especially across diverse and complex problem distributions. In this paper, we propose a unified robustness-oriented framework for preference-conditioned DRL solvers for MOCOPs. Within this framework, we develop a preference-based adversarial attack to generate hard instances that expose solver weaknesses, and quantify the attack impact by the resulting degradation on Pareto-front quality. We further introduce a defense strategy that integrates hardness-aware preference selection into adversarial training to reduce overfitting to restricted preference regions and improve out-of-distribution performance. The experimental results on multi-objective traveling salesman problem (MOTSP), multi-objective capacitated vehicle routing problem (MOCVRP), and multi-objective knapsack problem (MOKP) verify that our attack method successfully learns hard instances for different solvers. Furthermore, our defense method significantly strengthens the robustness and generalizability of neural solvers, delivering superior performance on hard or out-of-distribution instances.
Graph-Supported Dynamic Algorithm Configuration for Multi-Objective Combinatorial Optimization
May 22, 2025Deep reinforcement learning (DRL) has been widely used for dynamic algorithm configuration, particularly in evolutionary computation, which benefits from the adaptive update of parameters during the algorithmic execution. However, applying DRL to algorithm configuration for multi-objective combinatorial optimization (MOCO) problems remains relatively unexplored. This paper presents a novel graph neural network (GNN) based DRL to configure multi-objective evolutionary algorithms. We model the dynamic algorithm configuration as a Markov decision process, representing the convergence of solutions in the objective space by a graph, with their embeddings learned by a GNN to enhance the state representation. Experiments on diverse MOCO challenges indicate that our method outperforms traditional and DRL-based algorithm configuration methods in terms of efficacy and adaptability. It also exhibits advantageous generalizability across objective types and problem sizes, and applicability to different evolutionary computation methods.
Graph Reduction with Unsupervised Learning in Column Generation: A Routing Application
Apr 11, 2025Column Generation (CG) is a popular method dedicated to enhancing computational efficiency in large scale Combinatorial Optimization (CO) problems. It reduces the number of decision variables in a problem by solving a pricing problem. For many CO problems, the pricing problem is an Elementary Shortest Path Problem with Resource Constraints (ESPPRC). Large ESPPRC instances are difficult to solve to near-optimality. Consequently, we use a Graph neural Network (GNN) to reduces the size of the ESPPRC such that it becomes computationally tractable with standard solving techniques. Our GNN is trained by Unsupervised Learning and outputs a distribution for the arcs to be retained in the reduced PP. The reduced PP is solved by a local search that finds columns with large reduced costs and speeds up convergence. We apply our method on a set of Capacitated Vehicle Routing Problems with Time Windows and show significant improvements in convergence compared to simple reduction techniques from the literature. For a fixed computational budget, we improve the objective values by over 9\% for larger instances. We also analyze the performance of our CG algorithm and test the generalization of our method to different classes of instances than the training data.
Neural Combinatorial Optimization for Stochastic Flexible Job Shop Scheduling Problems
Dec 18, 2024Neural combinatorial optimization (NCO) has gained significant attention due to the potential of deep learning to efficiently solve combinatorial optimization problems. NCO has been widely applied to job shop scheduling problems (JSPs) with the current focus predominantly on deterministic problems. In this paper, we propose a novel attention-based scenario processing module (SPM) to extend NCO methods for solving stochastic JSPs. Our approach explicitly incorporates stochastic information by an attention mechanism that captures the embedding of sampled scenarios (i.e., an approximation of stochasticity). Fed with the embedding, the base neural network is intervened by the attended scenarios, which accordingly learns an effective policy under stochasticity. We also propose a training paradigm that works harmoniously with either the expected makespan or Value-at-Risk objective. Results demonstrate that our approach outperforms existing learning and non-learning methods for the flexible JSP problem with stochastic processing times on a variety of instances. In addition, our approach holds significant generalizability to varied numbers of scenarios and disparate distributions.
Offline Reinforcement Learning for Learning to Dispatch for Job Shop Scheduling
Sep 16, 2024



The Job Shop Scheduling Problem (JSSP) is a complex combinatorial optimization problem. There has been growing interest in using online Reinforcement Learning (RL) for JSSP. While online RL can quickly find acceptable solutions, especially for larger problems, it produces lower-quality results than traditional methods like Constraint Programming (CP). A significant downside of online RL is that it cannot learn from existing data, such as solutions generated from CP, requiring them to train from scratch, leading to sample inefficiency and making them unable to learn from more optimal examples. We introduce Offline Reinforcement Learning for Learning to Dispatch (Offline-LD), a novel approach for JSSP that addresses these limitations. Offline-LD adapts two CQL-based Q-learning methods (mQRDQN and discrete mSAC) for maskable action spaces, introduces a new entropy bonus modification for discrete SAC, and exploits reward normalization through preprocessing. Our experiments show that Offline-LD outperforms online RL on both generated and benchmark instances. By introducing noise into the dataset, we achieve similar or better results than those obtained from the expert dataset, indicating that a more diverse training set is preferable because it contains counterfactual information.
UNCO: Towards Unifying Neural Combinatorial Optimization through Large Language Model
Aug 22, 2024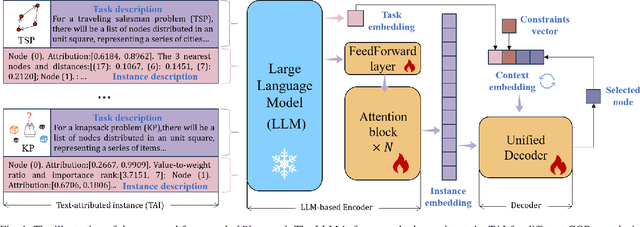
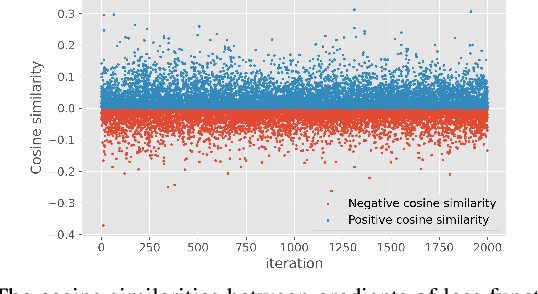
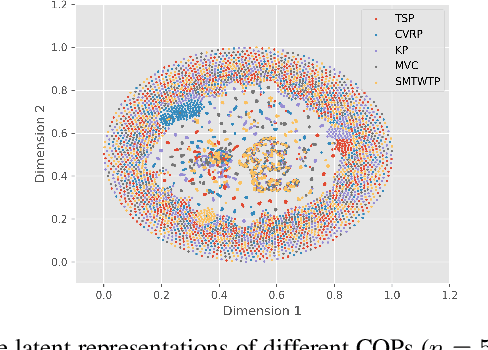
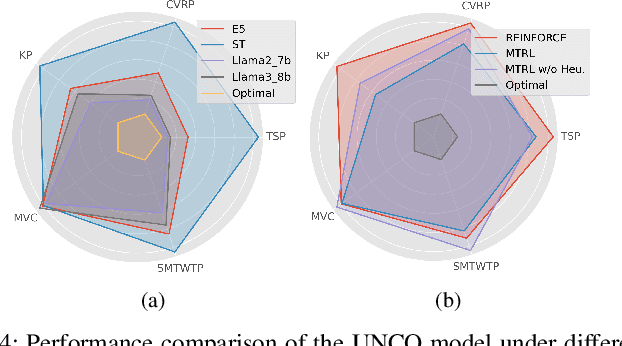
Recently, applying neural networks to address combinatorial optimization problems (COPs) has attracted considerable research attention. The prevailing methods always train deep models independently on specific problems, lacking a unified framework for concurrently tackling various COPs. To this end, we propose a unified neural combinatorial optimization (UNCO) framework to solve different types of COPs by a single model. Specifically, we use natural language to formulate text-attributed instances for different COPs and encode them in the same embedding space by the large language model (LLM). The obtained embeddings are further advanced by an encoder-decoder model without any problem-specific modules, thereby facilitating a unified process of solution construction. We further adopt the conflict gradients erasing reinforcement learning (CGERL) algorithm to train the UNCO model, delivering better performance across different COPs than vanilla multi-objective learning. Experiments show that the UNCO model can solve multiple COPs after a single-session training, and achieves satisfactory performance that is comparable to several traditional or learning-based baselines. Instead of pursuing the best performance for each COP, we explore the synergy between tasks and few-shot generalization based on LLM to inspire future work.
Graph Neural Networks for Job Shop Scheduling Problems: A Survey
Jun 20, 2024



Job shop scheduling problems (JSSPs) represent a critical and challenging class of combinatorial optimization problems. Recent years have witnessed a rapid increase in the application of graph neural networks (GNNs) to solve JSSPs, albeit lacking a systematic survey of the relevant literature. This paper aims to thoroughly review prevailing GNN methods for different types of JSSPs and the closely related flow-shop scheduling problems (FSPs), especially those leveraging deep reinforcement learning (DRL). We begin by presenting the graph representations of various JSSPs, followed by an introduction to the most commonly used GNN architectures. We then review current GNN-based methods for each problem type, highlighting key technical elements such as graph representations, GNN architectures, GNN tasks, and training algorithms. Finally, we summarize and analyze the advantages and limitations of GNNs in solving JSSPs and provide potential future research opportunities. We hope this survey can motivate and inspire innovative approaches for more powerful GNN-based approaches in tackling JSSPs and other scheduling problems.
Deep Multi-Objective Reinforcement Learning for Utility-Based Infrastructural Maintenance Optimization
Jun 10, 2024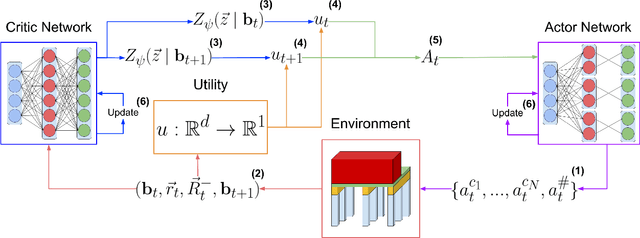
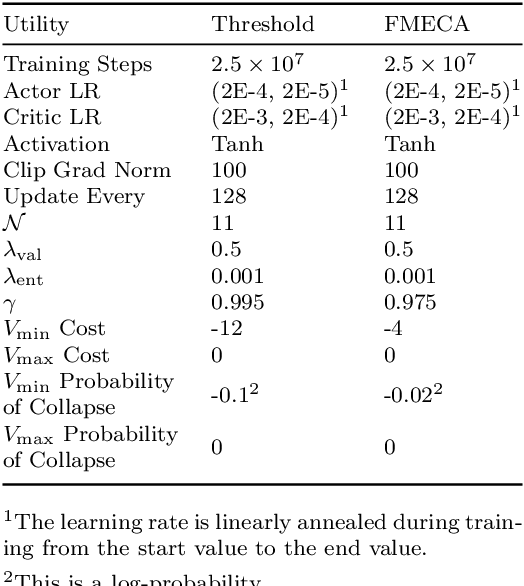
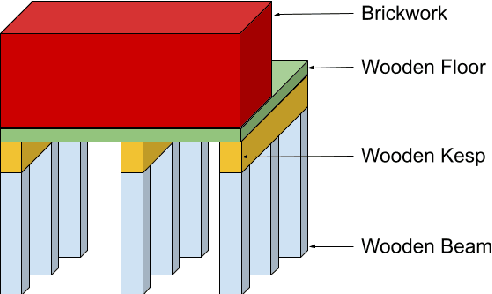

In this paper, we introduce Multi-Objective Deep Centralized Multi-Agent Actor-Critic (MO- DCMAC), a multi-objective reinforcement learning (MORL) method for infrastructural maintenance optimization, an area traditionally dominated by single-objective reinforcement learning (RL) approaches. Previous single-objective RL methods combine multiple objectives, such as probability of collapse and cost, into a singular reward signal through reward-shaping. In contrast, MO-DCMAC can optimize a policy for multiple objectives directly, even when the utility function is non-linear. We evaluated MO-DCMAC using two utility functions, which use probability of collapse and cost as input. The first utility function is the Threshold utility, in which MO-DCMAC should minimize cost so that the probability of collapse is never above the threshold. The second is based on the Failure Mode, Effects, and Criticality Analysis (FMECA) methodology used by asset managers to asses maintenance plans. We evaluated MO-DCMAC, with both utility functions, in multiple maintenance environments, including ones based on a case study of the historical quay walls of Amsterdam. The performance of MO-DCMAC was compared against multiple rule-based policies based on heuristics currently used for constructing maintenance plans. Our results demonstrate that MO-DCMAC outperforms traditional rule-based policies across various environments and utility functions.
Cross-Problem Learning for Solving Vehicle Routing Problems
Apr 17, 2024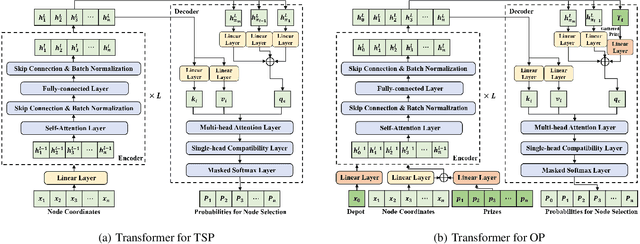

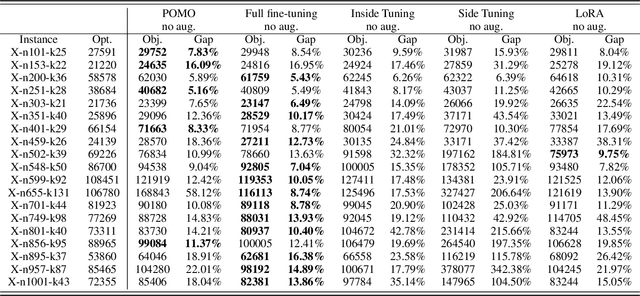

Existing neural heuristics often train a deep architecture from scratch for each specific vehicle routing problem (VRP), ignoring the transferable knowledge across different VRP variants. This paper proposes the cross-problem learning to assist heuristics training for different downstream VRP variants. Particularly, we modularize neural architectures for complex VRPs into 1) the backbone Transformer for tackling the travelling salesman problem (TSP), and 2) the additional lightweight modules for processing problem-specific features in complex VRPs. Accordingly, we propose to pre-train the backbone Transformer for TSP, and then apply it in the process of fine-tuning the Transformer models for each target VRP variant. On the one hand, we fully fine-tune the trained backbone Transformer and problem-specific modules simultaneously. On the other hand, we only fine-tune small adapter networks along with the modules, keeping the backbone Transformer still. Extensive experiments on typical VRPs substantiate that 1) the full fine-tuning achieves significantly better performance than the one trained from scratch, and 2) the adapter-based fine-tuning also delivers comparable performance while being notably parameter-efficient. Furthermore, we empirically demonstrate the favorable effect of our method in terms of cross-distribution application and versatility.