 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Expected Possession Value in Football: Introducing a Benchmark, U-Net Architecture, and Reward and Risk for Passes
Feb 04, 2025
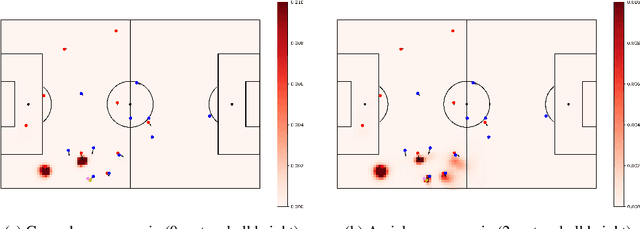


This paper introduces the first Expected Possession Value (EPV) benchmark and a new and improved EPV model for football. Through the introduction of the OJN-Pass-EPV benchmark, we present a novel method to quantitatively assess the quality of EPV models by using pairs of game states with given relative EPVs. Next, we attempt to replicate the results of Fern\'andez et al. (2021) using a dataset containing Dutch Eredivisie and World Cup matches. Following our failure to do so, we propose a new architecture based on U-net-type convolutional neural networks, achieving good results in model loss and Expected Calibration Error. Finally, we present an improved pass model that incorporates ball height and contains a new dual-component pass value model that analyzes reward and risk. The resulting EPV model correctly identifies the higher value state in 78% of the game state pairs in the OJN-Pass-EPV benchmark, demonstrating its ability to accurately assess goal-scoring potential. Our findings can help assess the quality of EPV models, improve EPV predictions, help assess potential reward and risk of passing decisions, and improve player and team performance.
Neural Combinatorial Optimization for Stochastic Flexible Job Shop Scheduling Problems
Dec 18, 2024Neural combinatorial optimization (NCO) has gained significant attention due to the potential of deep learning to efficiently solve combinatorial optimization problems. NCO has been widely applied to job shop scheduling problems (JSPs) with the current focus predominantly on deterministic problems. In this paper, we propose a novel attention-based scenario processing module (SPM) to extend NCO methods for solving stochastic JSPs. Our approach explicitly incorporates stochastic information by an attention mechanism that captures the embedding of sampled scenarios (i.e., an approximation of stochasticity). Fed with the embedding, the base neural network is intervened by the attended scenarios, which accordingly learns an effective policy under stochasticity. We also propose a training paradigm that works harmoniously with either the expected makespan or Value-at-Risk objective. Results demonstrate that our approach outperforms existing learning and non-learning methods for the flexible JSP problem with stochastic processing times on a variety of instances. In addition, our approach holds significant generalizability to varied numbers of scenarios and disparate distributions.