 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Supported Dynamic Algorithm Configuration for Multi-Objective Combinatorial Optimization
May 22, 2025Deep reinforcement learning (DRL) has been widely used for dynamic algorithm configuration, particularly in evolutionary computation, which benefits from the adaptive update of parameters during the algorithmic execution. However, applying DRL to algorithm configuration for multi-objective combinatorial optimization (MOCO) problems remains relatively unexplored. This paper presents a novel graph neural network (GNN) based DRL to configure multi-objective evolutionary algorithms. We model the dynamic algorithm configuration as a Markov decision process, representing the convergence of solutions in the objective space by a graph, with their embeddings learned by a GNN to enhance the state representation. Experiments on diverse MOCO challenges indicate that our method outperforms traditional and DRL-based algorithm configuration methods in terms of efficacy and adaptability. It also exhibits advantageous generalizability across objective types and problem sizes, and applicability to different evolutionary computation methods.
A Rollout-Based Algorithm and Reward Function for Efficient Resource Allocation in Business Processes
Apr 15, 2025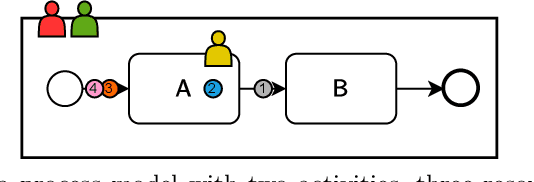
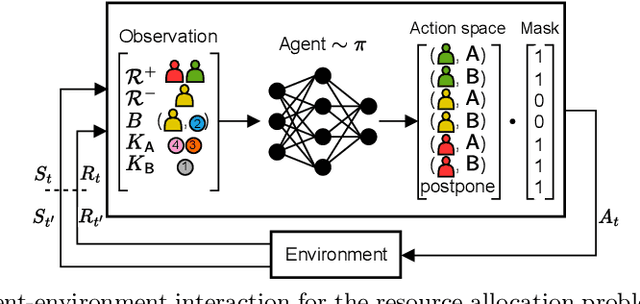

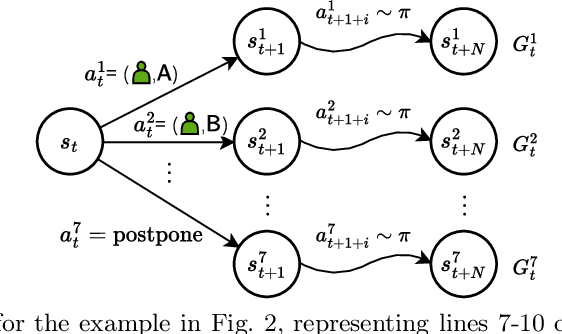
Resource allocation plays a critical role in minimizing cycle time and improving the efficiency of business processes. Recently, Deep Reinforcement Learning (DRL) has emerged as a powerful tool to optimize resource allocation policies in business processes. In the DRL framework, an agent learns a policy through interaction with the environment, guided solely by reward signals that indicate the quality of its decisions. However, existing algorithms are not suitable for dynamic environments such as business processes. Furthermore, existing DRL-based methods rely on engineered reward functions that approximate the desired objective, but a misalignment between reward and objective can lead to undesired decisions or suboptimal policies. To address these issues, we propose a rollout-based DRL algorithm and a reward function to optimize the objective directly. Our algorithm iteratively improves the policy by evaluating execution trajectories following different actions. Our reward function directly decomposes the objective function of minimizing the mean cycle time. Maximizing our reward function guarantees that the objective function is minimized without requiring extensive reward engineering. The results show that our method consistently learns the optimal policy in all six evaluated business processes, outperforming the state-of-the-art algorithm that can only learn the optimal policy in two of the evaluated processes.
Offline Reinforcement Learning for Learning to Dispatch for Job Shop Scheduling
Sep 16, 2024



The Job Shop Scheduling Problem (JSSP) is a complex combinatorial optimization problem. There has been growing interest in using online Reinforcement Learning (RL) for JSSP. While online RL can quickly find acceptable solutions, especially for larger problems, it produces lower-quality results than traditional methods like Constraint Programming (CP). A significant downside of online RL is that it cannot learn from existing data, such as solutions generated from CP, requiring them to train from scratch, leading to sample inefficiency and making them unable to learn from more optimal examples. We introduce Offline Reinforcement Learning for Learning to Dispatch (Offline-LD), a novel approach for JSSP that addresses these limitations. Offline-LD adapts two CQL-based Q-learning methods (mQRDQN and discrete mSAC) for maskable action spaces, introduces a new entropy bonus modification for discrete SAC, and exploits reward normalization through preprocessing. Our experiments show that Offline-LD outperforms online RL on both generated and benchmark instances. By introducing noise into the dataset, we achieve similar or better results than those obtained from the expert dataset, indicating that a more diverse training set is preferable because it contains counterfactual information.
Maintenance Strategies for Sewer Pipes with Multi-State Degradation and Deep Reinforcement Learning
Jul 17, 2024

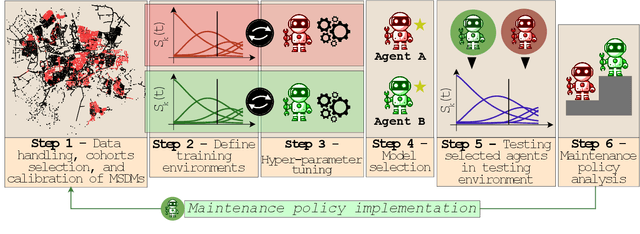

Large-scale infrastructure systems are crucial for societal welfare, and their effective management requires strategic forecasting and intervention methods that account for various complexities. Our study addresses two challenges within the Prognostics and Health Management (PHM) framework applied to sewer assets: modeling pipe degradation across severity levels and developing effective maintenance policies. We employ Multi-State Degradation Models (MSDM) to represent the stochastic degradation process in sewer pipes and use Deep Reinforcement Learning (DRL) to devise maintenance strategies. A case study of a Dutch sewer network exemplifies our methodology. Our findings demonstrate the model's effectiveness in generating intelligent, cost-saving maintenance strategies that surpass heuristics. It adapts its management strategy based on the pipe's age, opting for a passive approach for newer pipes and transitioning to active strategies for older ones to prevent failures and reduce costs. This research highlights DRL's potential in optimizing maintenance policies. Future research will aim improve the model by incorporating partial observability, exploring various reinforcement learning algorithms, and extending this methodology to comprehensive infrastructure management.
Graph Neural Networks for Job Shop Scheduling Problems: A Survey
Jun 20, 2024



Job shop scheduling problems (JSSPs) represent a critical and challenging class of combinatorial optimization problems. Recent years have witnessed a rapid increase in the application of graph neural networks (GNNs) to solve JSSPs, albeit lacking a systematic survey of the relevant literature. This paper aims to thoroughly review prevailing GNN methods for different types of JSSPs and the closely related flow-shop scheduling problems (FSPs), especially those leveraging deep reinforcement learning (DRL). We begin by presenting the graph representations of various JSSPs, followed by an introduction to the most commonly used GNN architectures. We then review current GNN-based methods for each problem type, highlighting key technical elements such as graph representations, GNN architectures, GNN tasks, and training algorithms. Finally, we summarize and analyze the advantages and limitations of GNNs in solving JSSPs and provide potential future research opportunities. We hope this survey can motivate and inspire innovative approaches for more powerful GNN-based approaches in tackling JSSPs and other scheduling problems.
Deep Multi-Objective Reinforcement Learning for Utility-Based Infrastructural Maintenance Optimization
Jun 10, 2024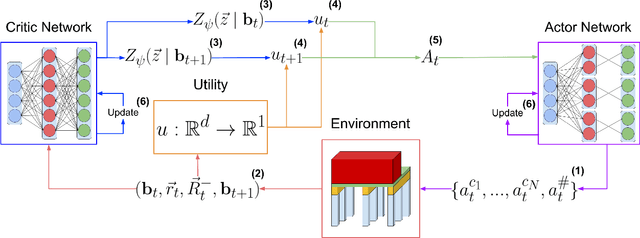
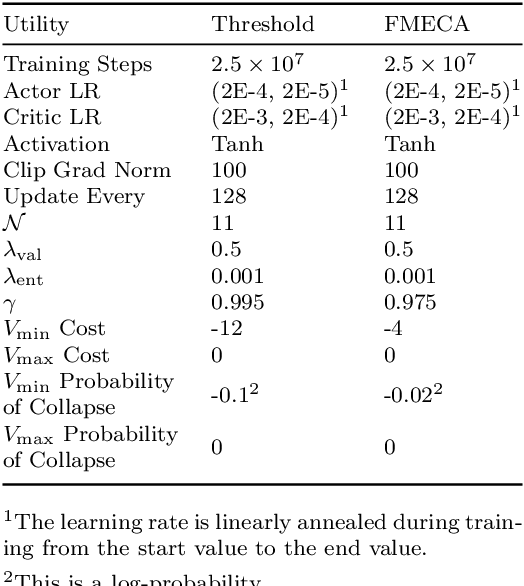
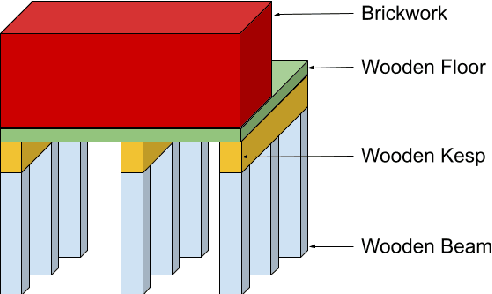

In this paper, we introduce Multi-Objective Deep Centralized Multi-Agent Actor-Critic (MO- DCMAC), a multi-objective reinforcement learning (MORL) method for infrastructural maintenance optimization, an area traditionally dominated by single-objective reinforcement learning (RL) approaches. Previous single-objective RL methods combine multiple objectives, such as probability of collapse and cost, into a singular reward signal through reward-shaping. In contrast, MO-DCMAC can optimize a policy for multiple objectives directly, even when the utility function is non-linear. We evaluated MO-DCMAC using two utility functions, which use probability of collapse and cost as input. The first utility function is the Threshold utility, in which MO-DCMAC should minimize cost so that the probability of collapse is never above the threshold. The second is based on the Failure Mode, Effects, and Criticality Analysis (FMECA) methodology used by asset managers to asses maintenance plans. We evaluated MO-DCMAC, with both utility functions, in multiple maintenance environments, including ones based on a case study of the historical quay walls of Amsterdam. The performance of MO-DCMAC was compared against multiple rule-based policies based on heuristics currently used for constructing maintenance plans. Our results demonstrate that MO-DCMAC outperforms traditional rule-based policies across various environments and utility functions.
Learning Efficient and Fair Policies for Uncertainty-Aware Collaborative Human-Robot Order Picking
Apr 09, 2024



In collaborative human-robot order picking systems, human pickers and Autonomous Mobile Robots (AMRs) travel independently through a warehouse and meet at pick locations where pickers load items onto the AMRs. In this paper, we consider an optimization problem in such systems where we allocate pickers to AMRs in a stochastic environment. We propose a novel multi-objective Deep Reinforcement Learning (DRL) approach to learn effective allocation policies to maximize pick efficiency while also aiming to improve workload fairness amongst human pickers. In our approach, we model the warehouse states using a graph, and define a neural network architecture that captures regional information and effectively extracts representations related to efficiency and workload. We develop a discrete-event simulation model, which we use to train and evaluate the proposed DRL approach. In the experiments, we demonstrate that our approach can find non-dominated policy sets that outline good trade-offs between fairness and efficiency objectives. The trained policies outperform the benchmarks in terms of both efficiency and fairness. Moreover, they show good transferability properties when tested on scenarios with different warehouse sizes. The implementation of the simulation model, proposed approach, and experiments are published.
Parcel loss prediction in last-mile delivery: deep and non-deep approaches with insights from Explainable AI
Oct 25, 2023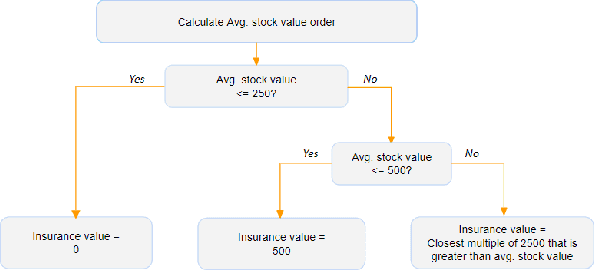

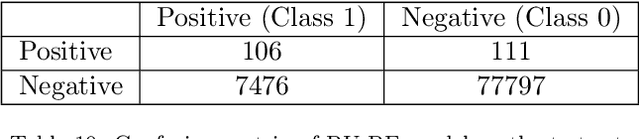
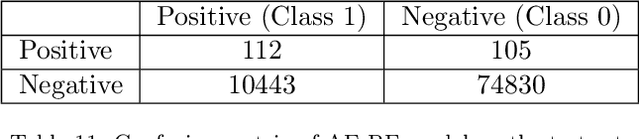
Within the domain of e-commerce retail, an important objective is the reduction of parcel loss during the last-mile delivery phase. The ever-increasing availability of data, including product, customer, and order information, has made it possible for the application of machine learning in parcel loss prediction. However, a significant challenge arises from the inherent imbalance in the data, i.e., only a very low percentage of parcels are lost. In this paper, we propose two machine learning approaches, namely, Data Balance with Supervised Learning (DBSL) and Deep Hybrid Ensemble Learning (DHEL), to accurately predict parcel loss. The practical implication of such predictions is their value in aiding e-commerce retailers in optimizing insurance-related decision-making policies. We conduct a comprehensive evaluation of the proposed machine learning models using one year data from Belgian shipments. The findings show that the DHEL model, which combines a feed-forward autoencoder with a random forest, achieves the highest classification performance. Furthermore, we use the techniques from Explainable AI (XAI) to illustrate how prediction models can be used in enhancing business processes and augmenting the overall value proposition for e-commerce retailers in the last mile delivery.
Job Shop Scheduling Benchmark: Environments and Instances for Learning and Non-learning Methods
Aug 24, 2023
We introduce an open-source GitHub repository containing comprehensive benchmarks for a wide range of machine scheduling problems, including Job Shop Scheduling (JSP), Flow Shop Scheduling (FSP), Flexible Job Shop Scheduling (FJSP), FJSP with Assembly constraints (FAJSP), FJSP with Sequence-Dependent Setup Times (FJSP-SDST), and the online FJSP (with online job arrivals). Our primary goal is to provide a centralized hub for researchers, practitioners, and enthusiasts interested in tackling machine scheduling challenges.
Unsupervised anomaly detection algorithms on real-world data: how many do we need?
May 01, 2023



In this study we evaluate 32 unsupervised anomaly detection algorithms on 52 real-world multivariate tabular datasets, performing the largest comparison of unsupervised anomaly detection algorithms to date. On this collection of datasets, the $k$-thNN (distance to the $k$-nearest neighbor) algorithm significantly outperforms the most other algorithms. Visualizing and then clustering the relative performance of the considered algorithms on all datasets, we identify two clear clusters: one with ``local'' datasets, and another with ``global'' datasets. ``Local'' anomalies occupy a region with low density when compared to nearby samples, while ``global'' occupy an overall low density region in the feature space. On the local datasets the $k$NN ($k$-nearest neighbor) algorithm comes out on top. On the global datasets, the EIF (extended isolation forest) algorithm performs the best. Also taking into consideration the algorithms' computational complexity, a toolbox with these three unsupervised anomaly detection algorithms suffices for finding anomalies in this representative collection of multivariate datasets. By providing access to code and datasets, our study can be easily reproduced and extended with more algorithms and/or datasets.