 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-Based Beliefs for POMDPs with Visual Observations
Feb 05, 2026Partially observable Markov decision processes (POMDPs) are a principled planning model for sequential decision-making under uncertainty. Yet, real-world problems with high-dimensional observations, such as camera images, remain intractable for traditional belief- and filtering-based solvers. To tackle this problem, we introduce the Perception-based Beliefs for POMDPs framework (PBP), which complements such solvers with a perception model. This model takes the form of an image classifier which maps visual observations to probability distributions over states. PBP incorporates these distributions directly into belief updates, so the underlying solver does not need to reason explicitly over high-dimensional observation spaces. We show that the belief update of PBP coincides with the standard belief update if the image classifier is exact. Moreover, to handle classifier imprecision, we incorporate uncertainty quantification and introduce two methods to adjust the belief update accordingly. We implement PBP using two traditional POMDP solvers and empirically show that (1) it outperforms existing end-to-end deep RL methods and (2) uncertainty quantification improves robustness of PBP against visual corruption.
\textsc{rfPG}: Robust Finite-Memory Policy Gradients for Hidden-Model POMDPs
May 14, 2025Partially observable Markov decision processes (POMDPs) model specific environments in sequential decision-making under uncertainty. Critically, optimal policies for POMDPs may not be robust against perturbations in the environment. Hidden-model POMDPs (HM-POMDPs) capture sets of different environment models, that is, POMDPs with a shared action and observation space. The intuition is that the true model is hidden among a set of potential models, and it is unknown which model will be the environment at execution time. A policy is robust for a given HM-POMDP if it achieves sufficient performance for each of its POMDPs. We compute such robust policies by combining two orthogonal techniques: (1) a deductive formal verification technique that supports tractable robust policy evaluation by computing a worst-case POMDP within the HM-POMDP and (2) subgradient ascent to optimize the candidate policy for a worst-case POMDP. The empirical evaluation shows that, compared to various baselines, our approach (1) produces policies that are more robust and generalize better to unseen POMDPs and (2) scales to HM-POMDPs that consist of over a hundred thousand environments.
Does Knowledge About Perceptual Uncertainty Help an Agent in Automated Driving?
Feb 17, 2025Agents in real-world scenarios like automated driving deal with uncertainty in their environment, in particular due to perceptual uncertainty. Although, reinforcement learning is dedicated to autonomous decision-making under uncertainty these algorithms are typically not informed about the uncertainty currently contained in their environment. On the other hand, uncertainty estimation for perception itself is typically directly evaluated in the perception domain, e.g., in terms of false positive detection rates or calibration errors based on camera images. Its use for deciding on goal-oriented actions remains largely unstudied. In this paper, we investigate how an agent's behavior is influenced by an uncertain perception and how this behavior changes if information about this uncertainty is available. Therefore, we consider a proxy task, where the agent is rewarded for driving a route as fast as possible without colliding with other road users. For controlled experiments, we introduce uncertainty in the observation space by perturbing the perception of the given agent while informing the latter. Our experiments show that an unreliable observation space modeled by a perturbed perception leads to a defensive driving behavior of the agent. Furthermore, when adding the information about the current uncertainty directly to the observation space, the agent adapts to the specific situation and in general accomplishes its task faster while, at the same time, accounting for risks.
Tighter Value-Function Approximations for POMDPs
Feb 10, 2025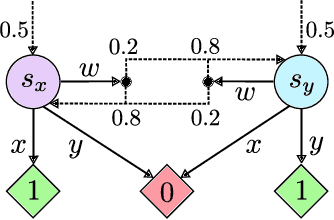

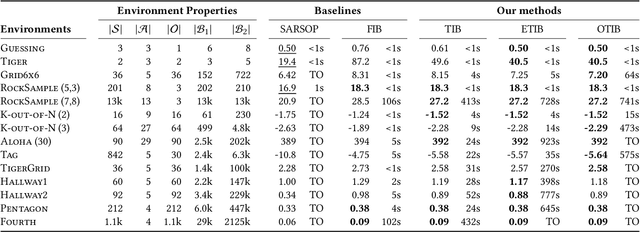
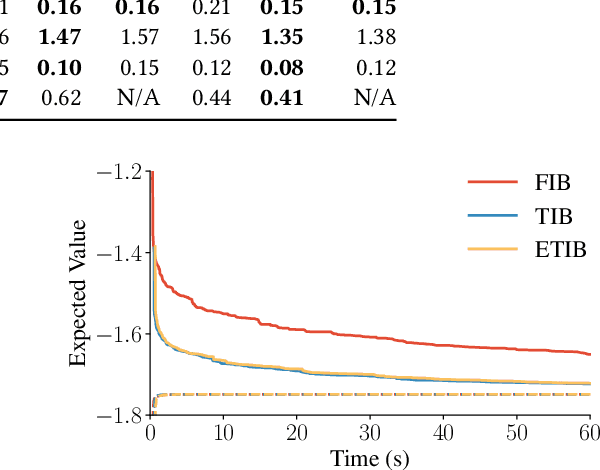
Solving partially observable Markov decision processes (POMDPs) typically requires reasoning about the values of exponentially many state beliefs. Towards practical performance, state-of-the-art solvers use value bounds to guide this reasoning. However, sound upper value bounds are often computationally expensive to compute, and there is a tradeoff between the tightness of such bounds and their computational cost. This paper introduces new and provably tighter upper value bounds than the commonly used fast informed bound. Our empirical evaluation shows that, despite their additional computational overhead, the new upper bounds accelerate state-of-the-art POMDP solvers on a wide range of benchmarks.
Robust Markov Decision Processes: A Place Where AI and Formal Methods Meet
Nov 18, 2024Markov decision processes (MDPs) are a standard model for sequential decision-making problems and are widely used across many scientific areas, including formal methods and artificial intelligence (AI). MDPs do, however, come with the restrictive assumption that the transition probabilities need to be precisely known. Robust MDPs (RMDPs) overcome this assumption by instead defining the transition probabilities to belong to some uncertainty set. We present a gentle survey on RMDPs, providing a tutorial covering their fundamentals. In particular, we discuss RMDP semantics and how to solve them by extending standard MDP methods such as value iteration and policy iteration. We also discuss how RMDPs relate to other models and how they are used in several contexts, including reinforcement learning and abstraction techniques. We conclude with some challenges for future work on RMDPs.
Pessimistic Iterative Planning for Robust POMDPs
Aug 16, 2024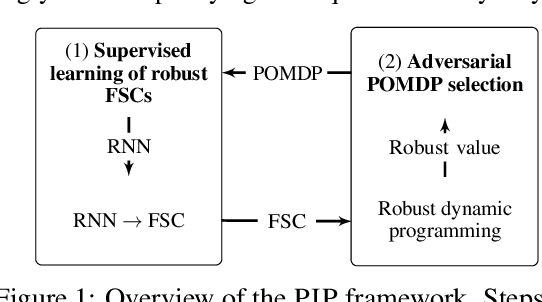
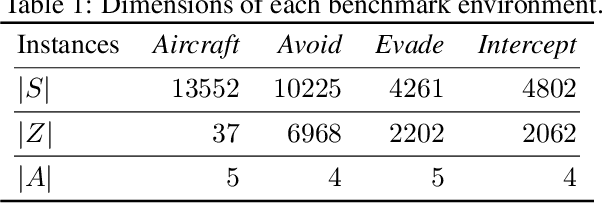
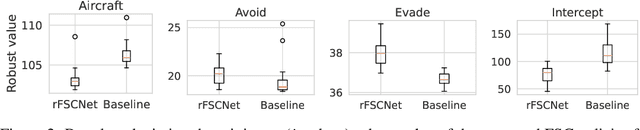
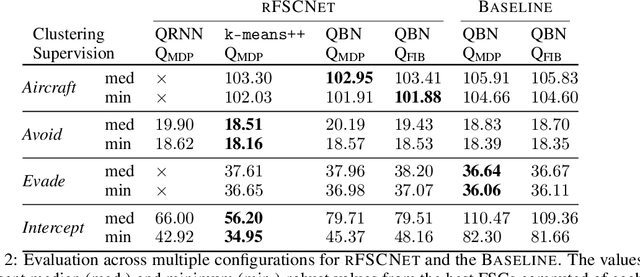
Robust partially observable Markov decision processes (robust POMDPs) extend classical POMDPs to handle additional uncertainty on the transition and observation probabilities via so-called uncertainty sets. Policies for robust POMDPs must not only be memory-based to account for partial observability but also robust against model uncertainty to account for the worst-case instances from the uncertainty sets. We propose the pessimistic iterative planning (PIP) framework, which finds robust memory-based policies for robust POMDPs. PIP alternates between two main steps: (1) selecting an adversarial (non-robust) POMDP via worst-case probability instances from the uncertainty sets; and (2) computing a finite-state controller (FSC) for this adversarial POMDP. We evaluate the performance of this FSC on the original robust POMDP and use this evaluation in step (1) to select the next adversarial POMDP. Within PIP, we propose the rFSCNet algorithm. In each iteration, rFSCNet finds an FSC through a recurrent neural network trained using supervision policies optimized for the adversarial POMDP. The empirical evaluation in four benchmark environments showcases improved robustness against a baseline method in an ablation study and competitive performance compared to a state-of-the-art robust POMDP solver.
Maintenance Strategies for Sewer Pipes with Multi-State Degradation and Deep Reinforcement Learning
Jul 17, 2024

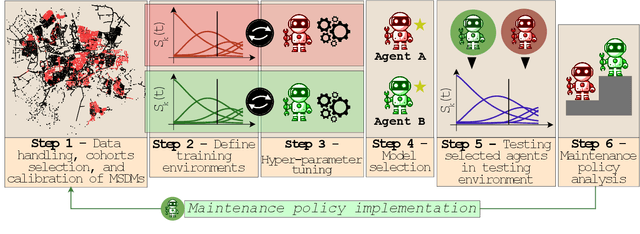

Large-scale infrastructure systems are crucial for societal welfare, and their effective management requires strategic forecasting and intervention methods that account for various complexities. Our study addresses two challenges within the Prognostics and Health Management (PHM) framework applied to sewer assets: modeling pipe degradation across severity levels and developing effective maintenance policies. We employ Multi-State Degradation Models (MSDM) to represent the stochastic degradation process in sewer pipes and use Deep Reinforcement Learning (DRL) to devise maintenance strategies. A case study of a Dutch sewer network exemplifies our methodology. Our findings demonstrate the model's effectiveness in generating intelligent, cost-saving maintenance strategies that surpass heuristics. It adapts its management strategy based on the pipe's age, opting for a passive approach for newer pipes and transitioning to active strategies for older ones to prevent failures and reduce costs. This research highlights DRL's potential in optimizing maintenance policies. Future research will aim improve the model by incorporating partial observability, exploring various reinforcement learning algorithms, and extending this methodology to comprehensive infrastructure management.
Learning-Based Verification of Stochastic Dynamical Systems with Neural Network Policies
Jun 02, 2024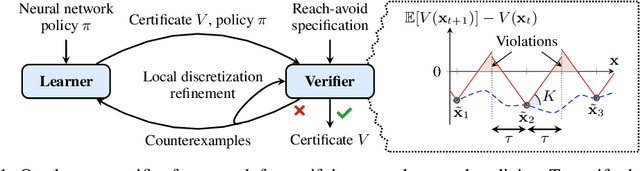

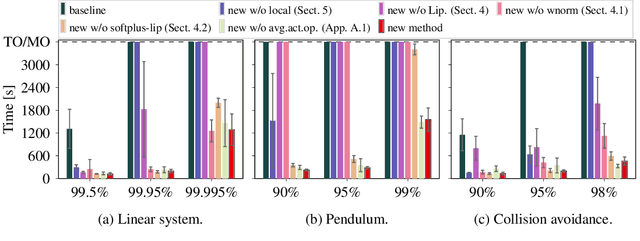

We consider the verification of neural network policies for reach-avoid control tasks in stochastic dynamical systems. We use a verification procedure that trains another neural network, which acts as a certificate proving that the policy satisfies the task. For reach-avoid tasks, it suffices to show that this certificate network is a reach-avoid supermartingale (RASM). As our main contribution, we significantly accelerate algorithmic approaches for verifying that a neural network is indeed a RASM. The main bottleneck of these approaches is the discretization of the state space of the dynamical system. The following two key contributions allow us to use a coarser discretization than existing approaches. First, we present a novel and fast method to compute tight upper bounds on Lipschitz constants of neural networks based on weighted norms. We further improve these bounds on Lipschitz constants based on the characteristics of the certificate network. Second, we integrate an efficient local refinement scheme that dynamically refines the state space discretization where necessary. Our empirical evaluation shows the effectiveness of our approach for verifying neural network policies in several benchmarks and trained with different reinforcement learning algorithms.
Approximate Dec-POMDP Solving Using Multi-Agent A*
May 09, 2024We present an A*-based algorithm to compute policies for finite-horizon Dec-POMDPs. Our goal is to sacrifice optimality in favor of scalability for larger horizons. The main ingredients of our approach are (1) using clustered sliding window memory, (2) pruning the A* search tree, and (3) using novel A* heuristics. Our experiments show competitive performance to the state-of-the-art. Moreover, for multiple benchmarks, we achieve superior performance. In addition, we provide an A* algorithm that finds upper bounds for the optimum, tailored towards problems with long horizons. The main ingredient is a new heuristic that periodically reveals the state, thereby limiting the number of reachable beliefs. Our experiments demonstrate the efficacy and scalability of the approach.
Imprecise Probabilities Meet Partial Observability: Game Semantics for Robust POMDPs
May 08, 2024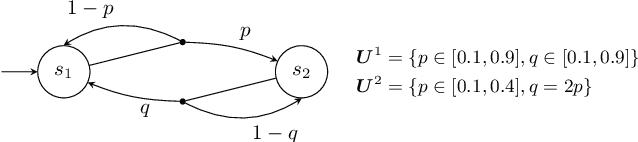
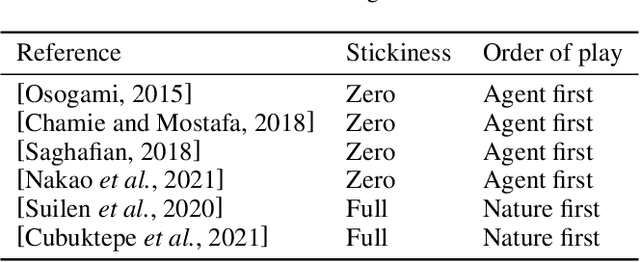
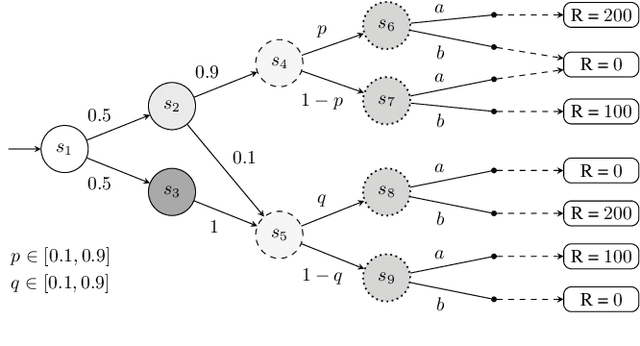
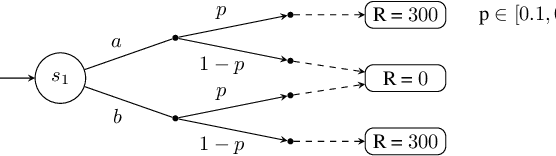
Partially observable Markov decision processes (POMDPs) rely on the key assumption that probability distributions are precisely known. Robust POMDPs (RPOMDPs) alleviate this concern by defining imprecise probabilities, referred to as uncertainty sets. While robust MDPs have been studied extensively, work on RPOMDPs is limited and primarily focuses on algorithmic solution methods. We expand the theoretical understanding of RPOMDPs by showing that 1) different assumptions on the uncertainty sets affect optimal policies and values; 2) RPOMDPs have a partially observable stochastic game (POSG) semantic; and 3) the same RPOMDP with different assumptions leads to semantically different POSGs and, thus, different policies and values. These novel semantics for RPOMDPS give access to results for the widely studied POSG model; concretely, we show the existence of a Nash equilibrium. Finally, we classify the existing RPOMDP literature using our semantics, clarifying under which uncertainty assumptions these existing works operate.