 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry-electronic fingerprints reveal competing magnetic phases in two-dimensional materials
Jun 11, 2026Two-dimensional magnets offer compelling platforms for spintronics and quantum technologies, yet predicting their magnetic ground states, moments, and anisotropy remains challenging. This limitation primarily arises because existing machine-learning representations encode chemical environments without capturing the symmetry or exchange physics that govern magnetism. In this work, we introduce the symmetry-electronic fingerprint (SEF), a physically interpretable representation that encodes crystallographic symmetry operations, Wyckoff-site geometry, together with site-resolved electronic structure. Combined with ensemble learning with random forests, the SEF accurately classifies magnetic ordering while regressing moments alongside anisotropy energies while simultaneously resolving the distinct regimes of itinerant Stoner ferromagnetism from localized superexchange. What sets the SEF-trained models apart is that regions of elevated model uncertainty are not a failure but a diagnostic, identifying materials where these mechanisms compete. First-principles calculations on Co- and Ni-based halides and oxides confirm that these regions correspond to genuine near-degenerate FM and AFM phases with magnetic frustration, suppressed anisotropy, and emergent non-collinear ordering. By encoding symmetry together with exchange physics directly into the representation unlike conventional descriptors, the SEF transforms model uncertainty into a compass pointing toward two-dimensional materials where small perturbations drive transitions between collinear, frustrated, or non-collinear magnetic phases.
Probabilistic Performance Guarantees for Multi-Task Reinforcement Learning
Feb 02, 2026Multi-task reinforcement learning trains generalist policies that can execute multiple tasks. While recent years have seen significant progress, existing approaches rarely provide formal performance guarantees, which are indispensable when deploying policies in safety-critical settings. We present an approach for computing high-confidence guarantees on the performance of a multi-task policy on tasks not seen during training. Concretely, we introduce a new generalisation bound that composes (i) per-task lower confidence bounds from finitely many rollouts with (ii) task-level generalisation from finitely many sampled tasks, yielding a high-confidence guarantee for new tasks drawn from the same arbitrary and unknown distribution. Across state-of-the-art multi-task RL methods, we show that the guarantees are theoretically sound and informative at realistic sample sizes.
Robust Verification of Concurrent Stochastic Games
Jan 21, 2026Autonomous systems often operate in multi-agent settings and need to make concurrent, strategic decisions, typically in uncertain environments. Verification and control problems for these systems can be tackled with concurrent stochastic games (CSGs), but this model requires transition probabilities to be precisely specified - an unrealistic requirement in many real-world settings. We introduce *robust CSGs* and their subclass *interval CSGs* (ICSGs), which capture epistemic uncertainty about transition probabilities in CSGs. We propose a novel framework for *robust* verification of these models under worst-case assumptions about transition uncertainty. Specifically, we develop the underlying theoretical foundations and efficient algorithms, for finite- and infinite-horizon objectives in both zero-sum and nonzero-sum settings, the latter based on (social-welfare optimal) Nash equilibria. We build an implementation in the PRISM-games model checker and demonstrate the feasibility of robust verification of ICSGs across a selection of large benchmarks.
Multi-Property Synthesis
Jan 15, 2026We study LTLf synthesis with multiple properties, where satisfying all properties may be impossible. Instead of enumerating subsets of properties, we compute in one fixed-point computation the relation between product-game states and the goal sets that are realizable from them, and we synthesize strategies achieving maximal realizable sets. We develop a fully symbolic algorithm that introduces Boolean goal variables and exploits monotonicity to represent exponentially many goal combinations compactly. Our approach substantially outperforms enumeration-based baselines, with speedups of up to two orders of magnitude.
About Time: Model-free Reinforcement Learning with Timed Reward Machines
Dec 19, 2025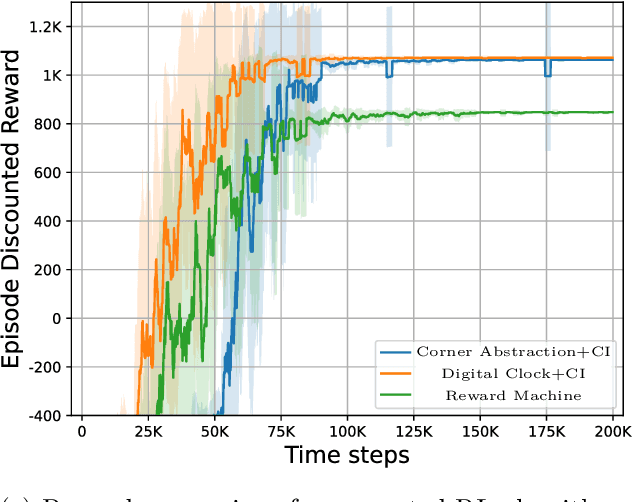
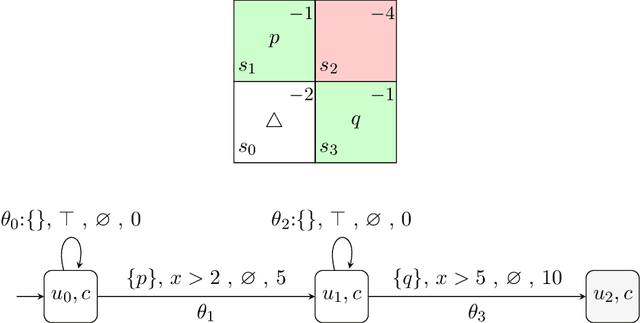

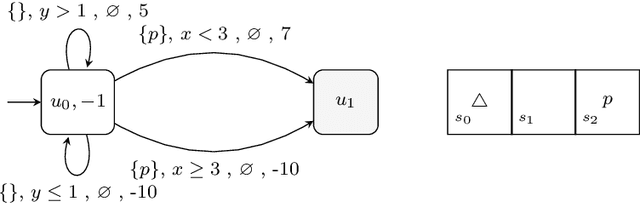
Reward specification plays a central role in reinforcement learning (RL), guiding the agent's behavior. To express non-Markovian rewards, formalisms such as reward machines have been introduced to capture dependencies on histories. However, traditional reward machines lack the ability to model precise timing constraints, limiting their use in time-sensitive applications. In this paper, we propose timed reward machines (TRMs), which are an extension of reward machines that incorporate timing constraints into the reward structure. TRMs enable more expressive specifications with tunable reward logic, for example, imposing costs for delays and granting rewards for timely actions. We study model-free RL frameworks (i.e., tabular Q-learning) for learning optimal policies with TRMs under digital and real-time semantics. Our algorithms integrate the TRM into learning via abstractions of timed automata, and employ counterfactual-imagining heuristics that exploit the structure of the TRM to improve the search. Experimentally, we demonstrate that our algorithm learns policies that achieve high rewards while satisfying the timing constraints specified by the TRM on popular RL benchmarks. Moreover, we conduct comparative studies of performance under different TRM semantics, along with ablations that highlight the benefits of counterfactual-imagining.
Efficient Solution and Learning of Robust Factored MDPs
Aug 01, 2025Robust Markov decision processes (r-MDPs) extend MDPs by explicitly modelling epistemic uncertainty about transition dynamics. Learning r-MDPs from interactions with an unknown environment enables the synthesis of robust policies with provable (PAC) guarantees on performance, but this can require a large number of sample interactions. We propose novel methods for solving and learning r-MDPs based on factored state-space representations that leverage the independence between model uncertainty across system components. Although policy synthesis for factored r-MDPs leads to hard, non-convex optimisation problems, we show how to reformulate these into tractable linear programs. Building on these, we also propose methods to learn factored model representations directly. Our experimental results show that exploiting factored structure can yield dimensional gains in sample efficiency, producing more effective robust policies with tighter performance guarantees than state-of-the-art methods.
Learning Probabilistic Temporal Logic Specifications for Stochastic Systems
May 17, 2025There has been substantial progress in the inference of formal behavioural specifications from sample trajectories, for example, using Linear Temporal Logic (LTL). However, these techniques cannot handle specifications that correctly characterise systems with stochastic behaviour, which occur commonly in reinforcement learning and formal verification. We consider the passive learning problem of inferring a Boolean combination of probabilistic LTL (PLTL) formulas from a set of Markov chains, classified as either positive or negative. We propose a novel learning algorithm that infers concise PLTL specifications, leveraging grammar-based enumeration, search heuristics, probabilistic model checking and Boolean set-cover procedures. We demonstrate the effectiveness of our algorithm in two use cases: learning from policies induced by RL algorithms and learning from variants of a probabilistic model. In both cases, our method automatically and efficiently extracts PLTL specifications that succinctly characterise the temporal differences between the policies or model variants.
Planning with Linear Temporal Logic Specifications: Handling Quantifiable and Unquantifiable Uncertainty
Feb 26, 2025This work studies the planning problem for robotic systems under both quantifiable and unquantifiable uncertainty. The objective is to enable the robotic systems to optimally fulfill high-level tasks specified by Linear Temporal Logic (LTL) formulas. To capture both types of uncertainty in a unified modelling framework, we utilise Markov Decision Processes with Set-valued Transitions (MDPSTs). We introduce a novel solution technique for the optimal robust strategy synthesis of MDPSTs with LTL specifications. To improve efficiency, our work leverages limit-deterministic B\"uchi automata (LDBAs) as the automaton representation for LTL to take advantage of their efficient constructions. To tackle the inherent nondeterminism in MDPSTs, which presents a significant challenge for reducing the LTL planning problem to a reachability problem, we introduce the concept of a Winning Region (WR) for MDPSTs. Additionally, we propose an algorithm for computing the WR over the product of the MDPST and the LDBA. Finally, a robust value iteration algorithm is invoked to solve the reachability problem. We validate the effectiveness of our approach through a case study involving a mobile robot operating in the hexagonal world, demonstrating promising efficiency gains.
Robust Markov Decision Processes: A Place Where AI and Formal Methods Meet
Nov 18, 2024Markov decision processes (MDPs) are a standard model for sequential decision-making problems and are widely used across many scientific areas, including formal methods and artificial intelligence (AI). MDPs do, however, come with the restrictive assumption that the transition probabilities need to be precisely known. Robust MDPs (RMDPs) overcome this assumption by instead defining the transition probabilities to belong to some uncertainty set. We present a gentle survey on RMDPs, providing a tutorial covering their fundamentals. In particular, we discuss RMDP semantics and how to solve them by extending standard MDP methods such as value iteration and policy iteration. We also discuss how RMDPs relate to other models and how they are used in several contexts, including reinforcement learning and abstraction techniques. We conclude with some challenges for future work on RMDPs.
Expectation vs. Reality: Towards Verification of Psychological Games
Nov 08, 2024Game theory provides an effective way to model strategic interactions among rational agents. In the context of formal verification, these ideas can be used to produce guarantees on the correctness of multi-agent systems, with a diverse range of applications from computer security to autonomous driving. Psychological games (PGs) were developed as a way to model and analyse agents with belief-dependent motivations, opening up the possibility to model how human emotions can influence behaviour. In PGs, players' utilities depend not only on what actually happens (which strategies players choose to adopt), but also on what the players had expected to happen (their belief as to the strategies that would be played). Despite receiving much attention in fields such as economics and psychology, very little consideration has been given to their applicability to problems in computer science, nor to practical algorithms and tool support. In this paper, we start to bridge that gap, proposing methods to solve PGs and implementing them within PRISM-games, a formal verification tool for stochastic games. We discuss how to model these games, highlight specific challenges for their analysis and illustrate the usefulness of our approach on several case studies, including human behaviour in traffic scenarios.