 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemML: Enhancing Automata-Theoretic LTL Synthesis with Machine Learning
Jan 29, 2025



Synthesizing a reactive system from specifications given in linear temporal logic (LTL) is a classical problem, finding its applications in safety-critical systems design. We present our tool SemML, which won this year's LTL realizability tracks of SYNTCOMP, after years of domination by Strix. While both tools are based on the automata-theoretic approach, ours relies heavily on (i) Semantic labelling, additional information of logical nature, coming from recent LTL-to-automata translations and decorating the resulting parity game, and (ii) Machine Learning approaches turning this information into a guidance oracle for on-the-fly exploration of the parity game (whence the name SemML). Our tool fills the missing gaps of previous suggestions to use such an oracle and provides an efficeint implementation with additional algorithmic improvements. We evaluate SemML both on the entire set of SYNTCOMP as well as a synthetic data set, compare it to Strix, and analyze the advantages and limitations. As SemML solves more instances on SYNTCOMP and does so significantly faster on larger instances, this demonstrates for the first time that machine-learning-aided approaches can out-perform state-of-the-art tools in real LTL synthesis.
Solving Robust Markov Decision Processes: Generic, Reliable, Efficient
Dec 13, 2024Markov decision processes (MDP) are a well-established model for sequential decision-making in the presence of probabilities. In robust MDP (RMDP), every action is associated with an uncertainty set of probability distributions, modelling that transition probabilities are not known precisely. Based on the known theoretical connection to stochastic games, we provide a framework for solving RMDPs that is generic, reliable, and efficient. It is *generic* both with respect to the model, allowing for a wide range of uncertainty sets, including but not limited to intervals, $L^1$- or $L^2$-balls, and polytopes; and with respect to the objective, including long-run average reward, undiscounted total reward, and stochastic shortest path. It is *reliable*, as our approach not only converges in the limit, but provides precision guarantees at any time during the computation. It is *efficient* because -- in contrast to state-of-the-art approaches -- it avoids explicitly constructing the underlying stochastic game. Consequently, our prototype implementation outperforms existing tools by several orders of magnitude and can solve RMDPs with a million states in under a minute.
Certified Policy Verification and Synthesis for MDPs under Distributional Reach-avoidance Properties
May 07, 2024



Markov Decision Processes (MDPs) are a classical model for decision making in the presence of uncertainty. Often they are viewed as state transformers with planning objectives defined with respect to paths over MDP states. An increasingly popular alternative is to view them as distribution transformers, giving rise to a sequence of probability distributions over MDP states. For instance, reachability and safety properties in modeling robot swarms or chemical reaction networks are naturally defined in terms of probability distributions over states. Verifying such distributional properties is known to be hard and often beyond the reach of classical state-based verification techniques. In this work, we consider the problems of certified policy (i.e. controller) verification and synthesis in MDPs under distributional reach-avoidance specifications. By certified we mean that, along with a policy, we also aim to synthesize a (checkable) certificate ensuring that the MDP indeed satisfies the property. Thus, given the target set of distributions and an unsafe set of distributions over MDP states, our goal is to either synthesize a certificate for a given policy or synthesize a policy along with a certificate, proving that the target distribution can be reached while avoiding unsafe distributions. To solve this problem, we introduce the novel notion of distributional reach-avoid certificates and present automated procedures for (1) synthesizing a certificate for a given policy, and (2) synthesizing a policy together with the certificate, both providing formal guarantees on certificate correctness. Our experimental evaluation demonstrates the ability of our method to solve several non-trivial examples, including a multi-agent robot-swarm model, to synthesize certified policies and to certify existing policies.
Playing Games with your PET: Extending the Partial Exploration Tool to Stochastic Games
May 06, 2024



We present version 2.0 of the Partial Exploration Tool (PET), a tool for verification of probabilistic systems. We extend the previous version by adding support for stochastic games, based on a recent unified framework for sound value iteration algorithms. Thereby, PET2 is the first tool implementing a sound and efficient approach for solving stochastic games with objectives of the type reachability/safety and mean payoff. We complement this approach by developing and implementing a partial-exploration based variant for all three objectives. Our experimental evaluation shows that PET2 offers the most efficient partial-exploration based algorithm and is the most viable tool on SGs, even outperforming unsound tools.
What Are the Odds? Improving the foundations of Statistical Model Checking
Apr 08, 2024



Markov decision processes (MDPs) are a fundamental model for decision making under uncertainty. They exhibit non-deterministic choice as well as probabilistic uncertainty. Traditionally, verification algorithms assume exact knowledge of the probabilities that govern the behaviour of an MDP. As this assumption is often unrealistic in practice, statistical model checking (SMC) was developed in the past two decades. It allows to analyse MDPs with unknown transition probabilities and provide probably approximately correct (PAC) guarantees on the result. Model-based SMC algorithms sample the MDP and build a model of it by estimating all transition probabilities, essentially for every transition answering the question: ``What are the odds?'' However, so far the statistical methods employed by the state of the art SMC algorithms are quite naive. Our contribution are several fundamental improvements to those methods: On the one hand, we survey statistics literature for better concentration inequalities; on the other hand, we propose specialised approaches that exploit our knowledge of the MDP. Our improvements are generally applicable to many kinds of problem statements because they are largely independent of the setting. Moreover, our experimental evaluation shows that they lead to significant gains, reducing the number of samples that the SMC algorithm has to collect by up to two orders of magnitude.
Learning Algorithms for Verification of Markov Decision Processes
Mar 20, 2024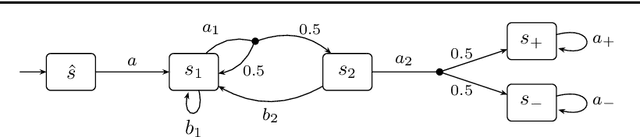
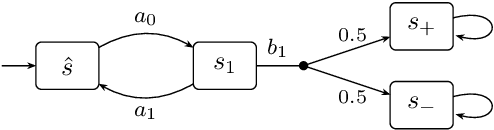
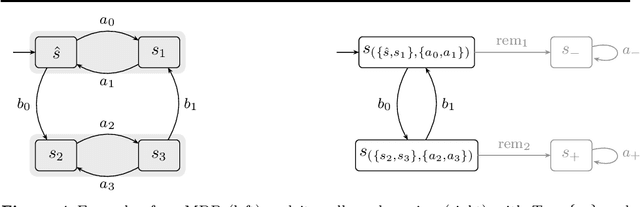

We present a general framework for applying learning algorithms and heuristical guidance to the verification of Markov decision processes (MDPs). The primary goal of our techniques is to improve performance by avoiding an exhaustive exploration of the state space, instead focussing on particularly relevant areas of the system, guided by heuristics. Our work builds on the previous results of Br{\'{a}}zdil et al., significantly extending it as well as refining several details and fixing errors. The presented framework focuses on probabilistic reachability, which is a core problem in verification, and is instantiated in two distinct scenarios. The first assumes that full knowledge of the MDP is available, in particular precise transition probabilities. It performs a heuristic-driven partial exploration of the model, yielding precise lower and upper bounds on the required probability. The second tackles the case where we may only sample the MDP without knowing the exact transition dynamics. Here, we obtain probabilistic guarantees, again in terms of both the lower and upper bounds, which provides efficient stopping criteria for the approximation. In particular, the latter is an extension of statistical model-checking (SMC) for unbounded properties in MDPs. In contrast to other related approaches, we do not restrict our attention to time-bounded (finite-horizon) or discounted properties, nor assume any particular structural properties of the MDP.
Reachability Poorman Discrete-Bidding Games
Jul 27, 2023
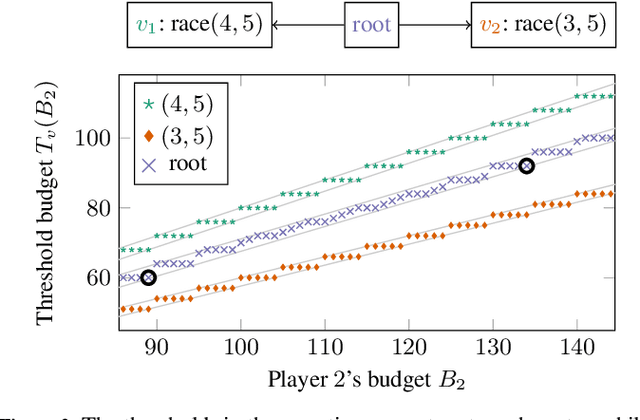
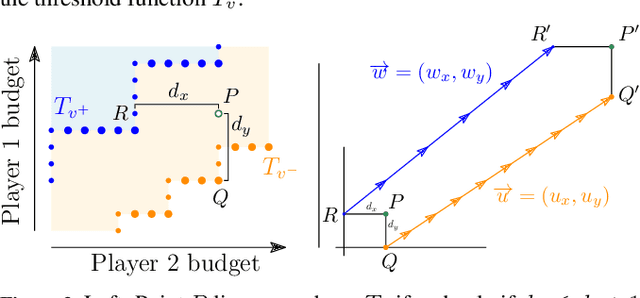
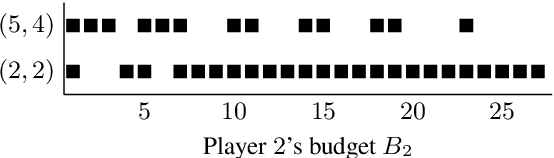
We consider {\em bidding games}, a class of two-player zero-sum {\em graph games}. The game proceeds as follows. Both players have bounded budgets. A token is placed on a vertex of a graph, in each turn the players simultaneously submit bids, and the higher bidder moves the token, where we break bidding ties in favor of Player 1. Player 1 wins the game iff the token visits a designated target vertex. We consider, for the first time, {\em poorman discrete-bidding} in which the granularity of the bids is restricted and the higher bid is paid to the bank. Previous work either did not impose granularity restrictions or considered {\em Richman} bidding (bids are paid to the opponent). While the latter mechanisms are technically more accessible, the former is more appealing from a practical standpoint. Our study focuses on {\em threshold budgets}, which is the necessary and sufficient initial budget required for Player 1 to ensure winning against a given Player 2 budget. We first show existence of thresholds. In DAGs, we show that threshold budgets can be approximated with error bounds by thresholds under continuous-bidding and that they exhibit a periodic behavior. We identify closed-form solutions in special cases. We implement and experiment with an algorithm to find threshold budgets.
Guessing Winning Policies in LTL Synthesis by Semantic Learning
May 24, 2023We provide a learning-based technique for guessing a winning strategy in a parity game originating from an LTL synthesis problem. A cheaply obtained guess can be useful in several applications. Not only can the guessed strategy be applied as best-effort in cases where the game's huge size prohibits rigorous approaches, but it can also increase the scalability of rigorous LTL synthesis in several ways. Firstly, checking whether a guessed strategy is winning is easier than constructing one. Secondly, even if the guess is wrong in some places, it can be fixed by strategy iteration faster than constructing one from scratch. Thirdly, the guess can be used in on-the-fly approaches to prioritize exploration in the most fruitful directions. In contrast to previous works, we (i)~reflect the highly structured logical information in game's states, the so-called semantic labelling, coming from the recent LTL-to-automata translations, and (ii)~learn to reflect it properly by learning from previously solved games, bringing the solving process closer to human-like reasoning.
Stopping Criteria for Value Iteration on Stochastic Games with Quantitative Objectives
Apr 19, 2023



A classic solution technique for Markov decision processes (MDP) and stochastic games (SG) is value iteration (VI). Due to its good practical performance, this approximative approach is typically preferred over exact techniques, even though no practical bounds on the imprecision of the result could be given until recently. As a consequence, even the most used model checkers could return arbitrarily wrong results. Over the past decade, different works derived stopping criteria, indicating when the precision reaches the desired level, for various settings, in particular MDP with reachability, total reward, and mean payoff, and SG with reachability. In this paper, we provide the first stopping criteria for VI on SG with total reward and mean payoff, yielding the first anytime algorithms in these settings. To this end, we provide the solution in two flavours: First through a reduction to the MDP case and second directly on SG. The former is simpler and automatically utilizes any advances on MDP. The latter allows for more local computations, heading towards better practical efficiency. Our solution unifies the previously mentioned approaches for MDP and SG and their underlying ideas. To achieve this, we isolate objective-specific subroutines as well as identify objective-independent concepts. These structural concepts, while surprisingly simple, form the very essence of the unified solution.
Risk-aware Stochastic Shortest Path
Mar 03, 2022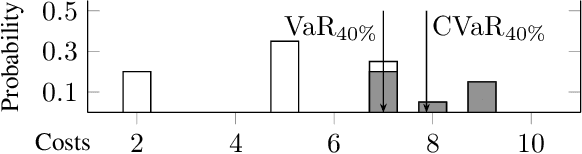
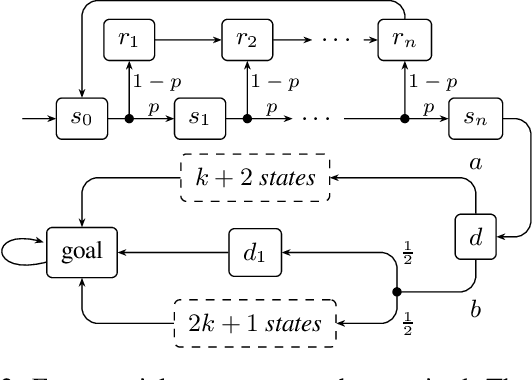
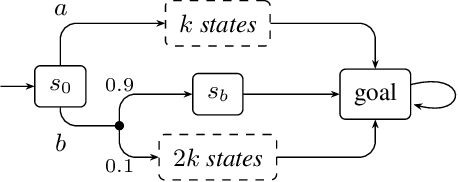
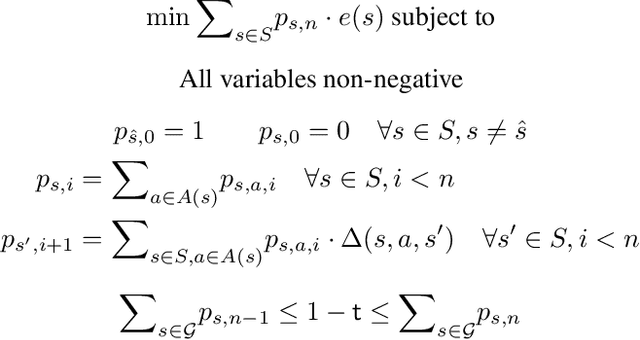
We treat the problem of risk-aware control for stochastic shortest path (SSP) on Markov decision processes (MDP). Typically, expectation is considered for SSP, which however is oblivious to the incurred risk. We present an alternative view, instead optimizing conditional value-at-risk (CVaR), an established risk measure. We treat both Markov chains as well as MDP and introduce, through novel insights, two algorithms, based on linear programming and value iteration, respectively. Both algorithms offer precise and provably correct solutions. Evaluation of our prototype implementation shows that risk-aware control is feasible on several moderately sized models.