 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Strategies for Stochastic Systems: How Much Does It Take to Break a Winning Strategy?
Feb 27, 2026We study the problem of resilient strategies in the presence of uncertainty. Resilient strategies enable an agent to make decisions that are robust against disturbances. In particular, we are interested in those disturbances that are able to flip a decision made by the agent. Such a disturbance may, for instance, occur when the intended action of the agent cannot be executed due to a malfunction of an actuator in the environment. In this work, we introduce the concept of resilience in the stochastic setting and present a comprehensive set of fundamental problems. Specifically, we discuss such problems for Markov decision processes with reachability and safety objectives, which also smoothly extend to stochastic games. To account for the stochastic setting, we provide various ways of aggregating the amounts of disturbances that may have occurred, for instance, in expectation or in the worst case. Moreover, to reason about infinite disturbances, we use quantitative measures, like their frequency of occurrence.
Provably Explaining Neural Additive Models
Feb 19, 2026Despite significant progress in post-hoc explanation methods for neural networks, many remain heuristic and lack provable guarantees. A key approach for obtaining explanations with provable guarantees is by identifying a cardinally-minimal subset of input features which by itself is provably sufficient to determine the prediction. However, for standard neural networks, this task is often computationally infeasible, as it demands a worst-case exponential number of verification queries in the number of input features, each of which is NP-hard. In this work, we show that for Neural Additive Models (NAMs), a recent and more interpretable neural network family, we can efficiently generate explanations with such guarantees. We present a new model-specific algorithm for NAMs that generates provably cardinally-minimal explanations using only a logarithmic number of verification queries in the number of input features, after a parallelized preprocessing step with logarithmic runtime in the required precision is applied to each small univariate NAM component. Our algorithm not only makes the task of obtaining cardinally-minimal explanations feasible, but even outperforms existing algorithms designed to find the relaxed variant of subset-minimal explanations - which may be larger and less informative but easier to compute - despite our algorithm solving a much more difficult task. Our experiments demonstrate that, compared to previous algorithms, our approach provides provably smaller explanations than existing works and substantially reduces the computation time. Moreover, we show that our generated provable explanations offer benefits that are unattainable by standard sampling-based techniques typically used to interpret NAMs.
Explaining Control Policies through Predicate Decision Diagrams
Mar 09, 2025



Safety-critical controllers of complex systems are hard to construct manually. Automated approaches such as controller synthesis or learning provide a tempting alternative but usually lack explainability. To this end, learning decision trees (DTs) have been prevalently used towards an interpretable model of the generated controllers. However, DTs do not exploit shared decision-making, a key concept exploited in binary decision diagrams (BDDs) to reduce their size and thus improve explainability. In this work, we introduce predicate decision diagrams (PDDs) that extend BDDs with predicates and thus unite the advantages of DTs and BDDs for controller representation. We establish a synthesis pipeline for efficient construction of PDDs from DTs representing controllers, exploiting reduction techniques for BDDs also for PDDs.
SemML: Enhancing Automata-Theoretic LTL Synthesis with Machine Learning
Jan 29, 2025



Synthesizing a reactive system from specifications given in linear temporal logic (LTL) is a classical problem, finding its applications in safety-critical systems design. We present our tool SemML, which won this year's LTL realizability tracks of SYNTCOMP, after years of domination by Strix. While both tools are based on the automata-theoretic approach, ours relies heavily on (i) Semantic labelling, additional information of logical nature, coming from recent LTL-to-automata translations and decorating the resulting parity game, and (ii) Machine Learning approaches turning this information into a guidance oracle for on-the-fly exploration of the parity game (whence the name SemML). Our tool fills the missing gaps of previous suggestions to use such an oracle and provides an efficeint implementation with additional algorithmic improvements. We evaluate SemML both on the entire set of SYNTCOMP as well as a synthetic data set, compare it to Strix, and analyze the advantages and limitations. As SemML solves more instances on SYNTCOMP and does so significantly faster on larger instances, this demonstrates for the first time that machine-learning-aided approaches can out-perform state-of-the-art tools in real LTL synthesis.
Explainable Finite-Memory Policies for Partially Observable Markov Decision Processes
Nov 20, 2024



Partially Observable Markov Decision Processes (POMDPs) are a fundamental framework for decision-making under uncertainty and partial observability. Since in general optimal policies may require infinite memory, they are hard to implement and often render most problems undecidable. Consequently, finite-memory policies are mostly considered instead. However, the algorithms for computing them are typically very complex, and so are the resulting policies. Facing the need for their explainability, we provide a representation of such policies, both (i) in an interpretable formalism and (ii) typically of smaller size, together yielding higher explainability. To that end, we combine models of Mealy machines and decision trees; the latter describing simple, stationary parts of the policies and the former describing how to switch among them. We design a translation for policies of the finite-state-controller (FSC) form from standard literature and show how our method smoothly generalizes to other variants of finite-memory policies. Further, we identify specific properties of recently used "attractor-based" policies, which allow us to construct yet simpler and smaller representations. Finally, we illustrate the higher explainability in a few case studies.
1-2-3-Go! Policy Synthesis for Parameterized Markov Decision Processes via Decision-Tree Learning and Generalization
Oct 23, 2024Despite the advances in probabilistic model checking, the scalability of the verification methods remains limited. In particular, the state space often becomes extremely large when instantiating parameterized Markov decision processes (MDPs) even with moderate values. Synthesizing policies for such \emph{huge} MDPs is beyond the reach of available tools. We propose a learning-based approach to obtain a reasonable policy for such huge MDPs. The idea is to generalize optimal policies obtained by model-checking small instances to larger ones using decision-tree learning. Consequently, our method bypasses the need for explicit state-space exploration of large models, providing a practical solution to the state-space explosion problem. We demonstrate the efficacy of our approach by performing extensive experimentation on the relevant models from the quantitative verification benchmark set. The experimental results indicate that our policies perform well, even when the size of the model is orders of magnitude beyond the reach of state-of-the-art analysis tools.
Monitizer: Automating Design and Evaluation of Neural Network Monitors
May 16, 2024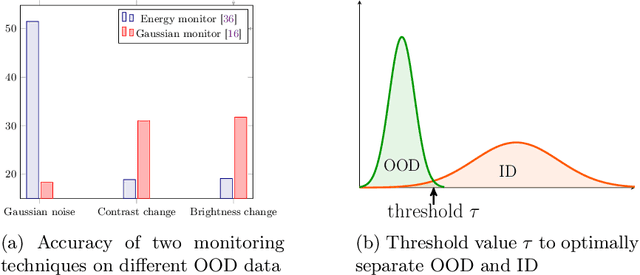

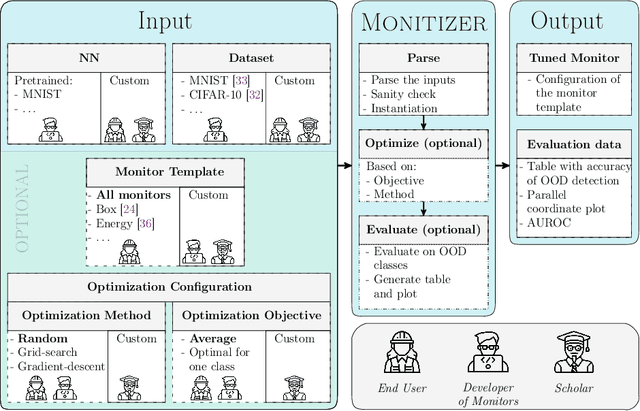
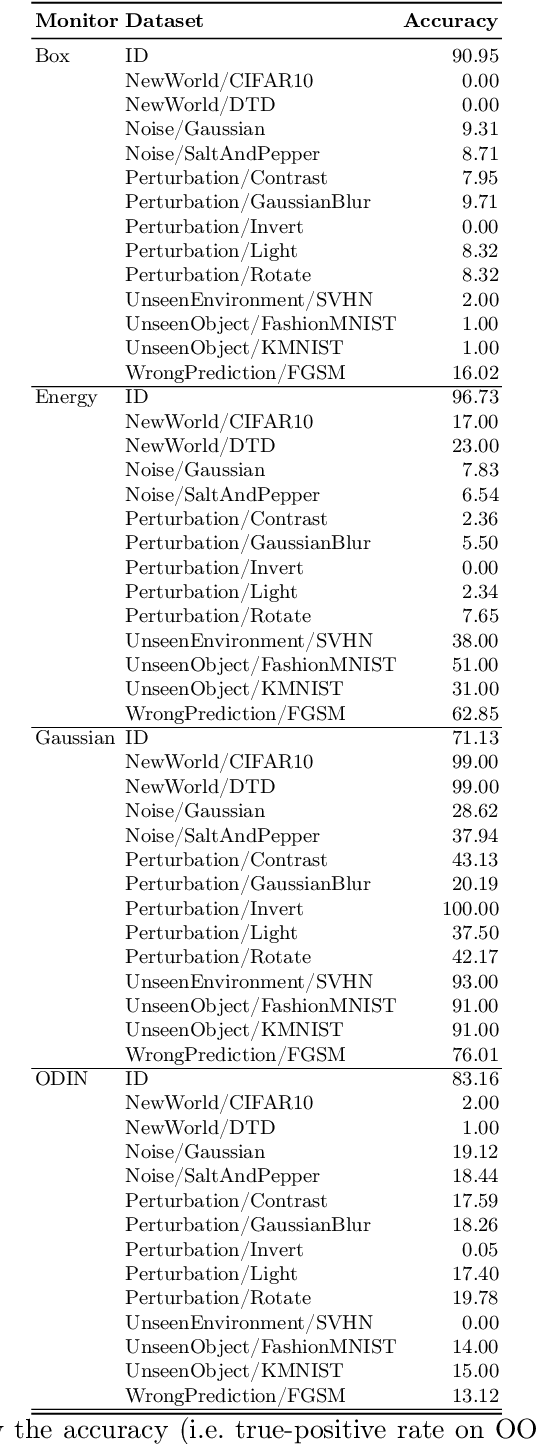
The behavior of neural networks (NNs) on previously unseen types of data (out-of-distribution or OOD) is typically unpredictable. This can be dangerous if the network's output is used for decision-making in a safety-critical system. Hence, detecting that an input is OOD is crucial for the safe application of the NN. Verification approaches do not scale to practical NNs, making runtime monitoring more appealing for practical use. While various monitors have been suggested recently, their optimization for a given problem, as well as comparison with each other and reproduction of results, remain challenging. We present a tool for users and developers of NN monitors. It allows for (i) application of various types of monitors from the literature to a given input NN, (ii) optimization of the monitor's hyperparameters, and (iii) experimental evaluation and comparison to other approaches. Besides, it facilitates the development of new monitoring approaches. We demonstrate the tool's usability on several use cases of different types of users as well as on a case study comparing different approaches from recent literature.
Learning Explainable and Better Performing Representations of POMDP Strategies
Jan 20, 2024



Strategies for partially observable Markov decision processes (POMDP) typically require memory. One way to represent this memory is via automata. We present a method to learn an automaton representation of a strategy using a modification of the L*-algorithm. Compared to the tabular representation of a strategy, the resulting automaton is dramatically smaller and thus also more explainable. Moreover, in the learning process, our heuristics may even improve the strategy's performance. In contrast to approaches that synthesize an automaton directly from the POMDP thereby solving it, our approach is incomparably more scalable.
MULTIGAIN 2.0: MDP controller synthesis for multiple mean-payoff, LTL and steady-state constraints
May 26, 2023


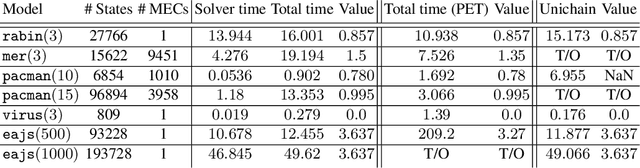
We present MULTIGAIN 2.0, a major extension to the controller synthesis tool MultiGain, built on top of the probabilistic model checker PRISM. This new version extends MultiGain's multi-objective capabilities, by allowing for the formal verification and synthesis of controllers for probabilistic systems with multi-dimensional long-run average reward structures, steady-state constraints, and linear temporal logic properties. Additionally, MULTIGAIN 2.0 provides an approach for finding finite memory solutions and the capability for two- and three-dimensional visualization of Pareto curves to facilitate trade-off analysis in multi-objective scenarios
Guessing Winning Policies in LTL Synthesis by Semantic Learning
May 24, 2023We provide a learning-based technique for guessing a winning strategy in a parity game originating from an LTL synthesis problem. A cheaply obtained guess can be useful in several applications. Not only can the guessed strategy be applied as best-effort in cases where the game's huge size prohibits rigorous approaches, but it can also increase the scalability of rigorous LTL synthesis in several ways. Firstly, checking whether a guessed strategy is winning is easier than constructing one. Secondly, even if the guess is wrong in some places, it can be fixed by strategy iteration faster than constructing one from scratch. Thirdly, the guess can be used in on-the-fly approaches to prioritize exploration in the most fruitful directions. In contrast to previous works, we (i)~reflect the highly structured logical information in game's states, the so-called semantic labelling, coming from the recent LTL-to-automata translations, and (ii)~learn to reflect it properly by learning from previously solved games, bringing the solving process closer to human-like reasoning.