 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic of Fuzzy Paths
Apr 27, 2026We introduce a new family of temporal logics intended for specifications in motion planning (MP). It builds upon the signal temporal logic (STL), which is a linear-time logic over real-valued signals that possess quantitative semantics and thus became popular in the areas of cyber-physical systems, robotics, and specifically robot MP. However, in contrast to STL, the proposed logic works with paths as first-class citizens, separating the concerns of geometry and of logic. This in turn leads to simpler and more understandable formulae, and a more refined notion of satisfaction being able to reflect also preferences over behaviours. Technically, the logic is built on fuzzy, time-varying signal constraints. As a consequence of this expressivity, it is (i) more usable for human-given specifications in MP and (ii) more amenable to learning specifications from demonstrations than other logics. The former is important for the traditional style of verification in robot MP; the latter is becoming recognized as crucial for mining data-given tasks and controller synthesis in human-aware MP. We expose the advantages of our proposed logic on examples and show the versatility and flexibility of the framework on a number of scenarios. Finally, we give a learning algorithm with a prototype implementation and discuss the possibilities of model checking and monitoring.
Resilient Strategies for Stochastic Systems: How Much Does It Take to Break a Winning Strategy?
Feb 27, 2026We study the problem of resilient strategies in the presence of uncertainty. Resilient strategies enable an agent to make decisions that are robust against disturbances. In particular, we are interested in those disturbances that are able to flip a decision made by the agent. Such a disturbance may, for instance, occur when the intended action of the agent cannot be executed due to a malfunction of an actuator in the environment. In this work, we introduce the concept of resilience in the stochastic setting and present a comprehensive set of fundamental problems. Specifically, we discuss such problems for Markov decision processes with reachability and safety objectives, which also smoothly extend to stochastic games. To account for the stochastic setting, we provide various ways of aggregating the amounts of disturbances that may have occurred, for instance, in expectation or in the worst case. Moreover, to reason about infinite disturbances, we use quantitative measures, like their frequency of occurrence.
Learning Explainable and Better Performing Representations of POMDP Strategies
Jan 20, 2024



Strategies for partially observable Markov decision processes (POMDP) typically require memory. One way to represent this memory is via automata. We present a method to learn an automaton representation of a strategy using a modification of the L*-algorithm. Compared to the tabular representation of a strategy, the resulting automaton is dramatically smaller and thus also more explainable. Moreover, in the learning process, our heuristics may even improve the strategy's performance. In contrast to approaches that synthesize an automaton directly from the POMDP thereby solving it, our approach is incomparably more scalable.
MULTIGAIN 2.0: MDP controller synthesis for multiple mean-payoff, LTL and steady-state constraints
May 26, 2023


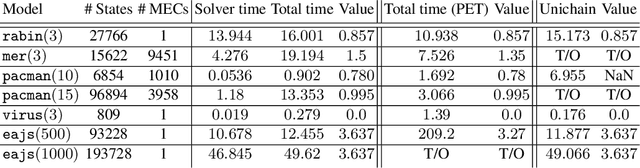
We present MULTIGAIN 2.0, a major extension to the controller synthesis tool MultiGain, built on top of the probabilistic model checker PRISM. This new version extends MultiGain's multi-objective capabilities, by allowing for the formal verification and synthesis of controllers for probabilistic systems with multi-dimensional long-run average reward structures, steady-state constraints, and linear temporal logic properties. Additionally, MULTIGAIN 2.0 provides an approach for finding finite memory solutions and the capability for two- and three-dimensional visualization of Pareto curves to facilitate trade-off analysis in multi-objective scenarios