 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Property Synthesis
Jan 15, 2026We study LTLf synthesis with multiple properties, where satisfying all properties may be impossible. Instead of enumerating subsets of properties, we compute in one fixed-point computation the relation between product-game states and the goal sets that are realizable from them, and we synthesize strategies achieving maximal realizable sets. We develop a fully symbolic algorithm that introduces Boolean goal variables and exploits monotonicity to represent exponentially many goal combinations compactly. Our approach substantially outperforms enumeration-based baselines, with speedups of up to two orders of magnitude.
Good-for-MDP State Reduction for Stochastic LTL Planning
Nov 15, 2025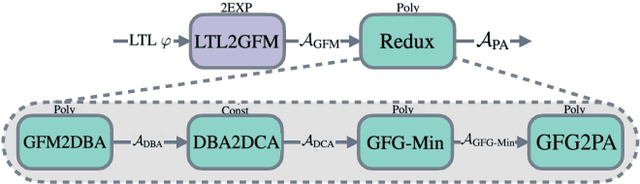
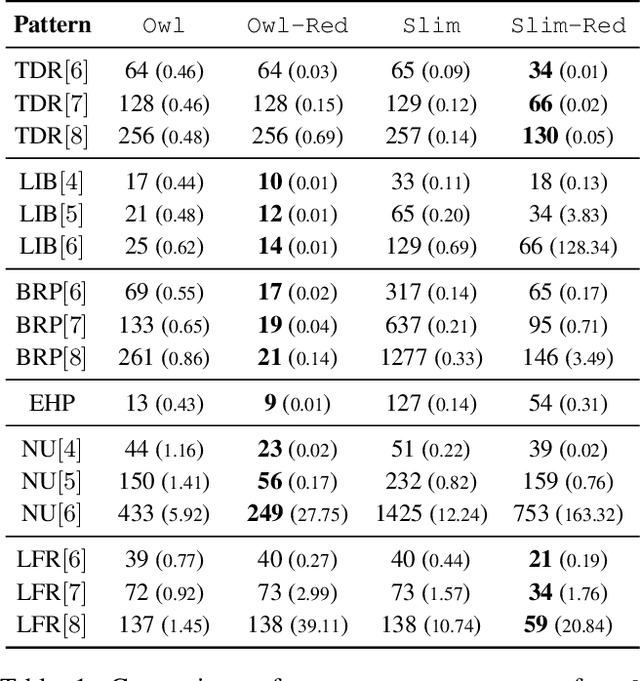
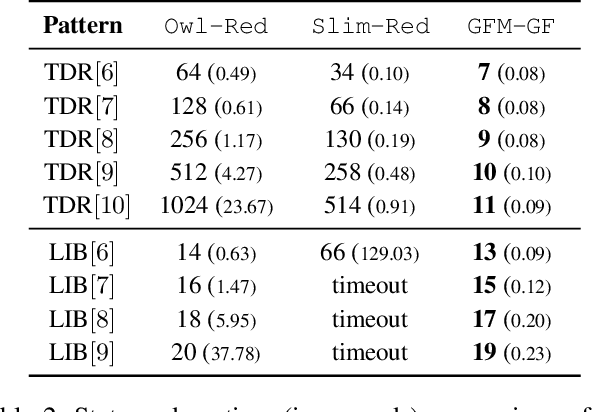
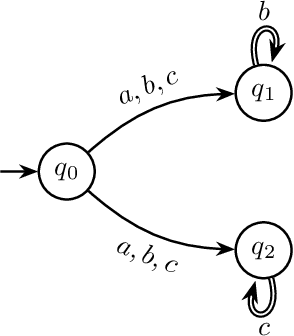
We study stochastic planning problems in Markov Decision Processes (MDPs) with goals specified in Linear Temporal Logic (LTL). The state-of-the-art approach transforms LTL formulas into good-for-MDP (GFM) automata, which feature a restricted form of nondeterminism. These automata are then composed with the MDP, allowing the agent to resolve the nondeterminism during policy synthesis. A major factor affecting the scalability of this approach is the size of the generated automata. In this paper, we propose a novel GFM state-space reduction technique that significantly reduces the number of automata states. Our method employs a sophisticated chain of transformations, leveraging recent advances in good-for-games minimisation developed for adversarial settings. In addition to our theoretical contributions, we present empirical results demonstrating the practical effectiveness of our state-reduction technique. Furthermore, we introduce a direct construction method for formulas of the form $\mathsf{G}\mathsf{F}\varphi$, where $\varphi$ is a co-safety formula. This construction is provably single-exponential in the worst case, in contrast to the general doubly-exponential complexity. Our experiments confirm the scalability advantages of this specialised construction.
Emerson-Lei and Manna-Pnueli Games for LTLf+ and PPLTL+ Synthesis
Aug 20, 2025Recently, the Manna-Pnueli Hierarchy has been used to define the temporal logics LTLfp and PPLTLp, which allow to use finite-trace LTLf/PPLTL techniques in infinite-trace settings while achieving the expressiveness of full LTL. In this paper, we present the first actual solvers for reactive synthesis in these logics. These are based on games on graphs that leverage DFA-based techniques from LTLf/PPLTL to construct the game arena. We start with a symbolic solver based on Emerson-Lei games, which reduces lower-class properties (guarantee, safety) to higher ones (recurrence, persistence) before solving the game. We then introduce Manna-Pnueli games, which natively embed Manna-Pnueli objectives into the arena. These games are solved by composing solutions to a DAG of simpler Emerson-Lei games, resulting in a provably more efficient approach. We implemented the solvers and practically evaluated their performance on a range of representative formulas. The results show that Manna-Pnueli games often offer significant advantages, though not universally, indicating that combining both approaches could further enhance practical performance.
Explaining Control Policies through Predicate Decision Diagrams
Mar 09, 2025



Safety-critical controllers of complex systems are hard to construct manually. Automated approaches such as controller synthesis or learning provide a tempting alternative but usually lack explainability. To this end, learning decision trees (DTs) have been prevalently used towards an interpretable model of the generated controllers. However, DTs do not exploit shared decision-making, a key concept exploited in binary decision diagrams (BDDs) to reduce their size and thus improve explainability. In this work, we introduce predicate decision diagrams (PDDs) that extend BDDs with predicates and thus unite the advantages of DTs and BDDs for controller representation. We establish a synthesis pipeline for efficient construction of PDDs from DTs representing controllers, exploiting reduction techniques for BDDs also for PDDs.
Code Simulation as a Proxy for High-order Tasks in Large Language Models
Feb 05, 2025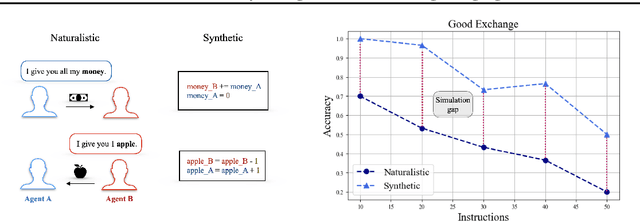


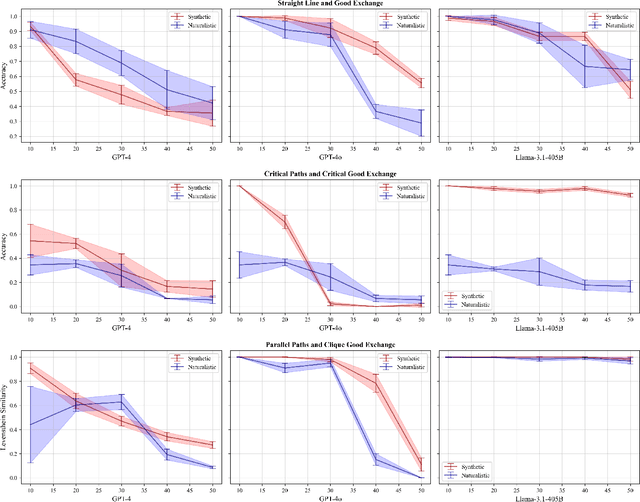
Many reasoning, planning, and problem-solving tasks share an intrinsic algorithmic nature: correctly simulating each step is a sufficient condition to solve them correctly. We collect pairs of naturalistic and synthetic reasoning tasks to assess the capabilities of Large Language Models (LLM). While naturalistic tasks often require careful human handcrafting, we show that synthetic data is, in many cases, a good proxy that is much easier to collect at scale. We leverage common constructs in programming as the counterpart of the building blocks of naturalistic reasoning tasks, such as straight-line programs, code that contains critical paths, and approximate and redundant instructions. We further assess the capabilities of LLMs on sorting problems and repeated operations via sorting algorithms and nested loops. Our synthetic datasets further reveal that while the most powerful LLMs exhibit relatively strong execution capabilities, the process is fragile: it is negatively affected by memorisation and seems to rely heavily on pattern recognition. Our contribution builds upon synthetically testing the reasoning capabilities of LLMs as a scalable complement to handcrafted human-annotated problems.
Code Simulation Challenges for Large Language Models
Jan 21, 2024



We investigate the extent to which Large Language Models (LLMs) can simulate the execution of computer code and algorithms. We begin by looking at straight line programs, and show that current LLMs demonstrate poor performance even with such simple programs -- performance rapidly degrades with the length of code. We then investigate the ability of LLMs to simulate programs that contain critical paths and redundant instructions. We also go beyond straight line program simulation with sorting algorithms and nested loops, and we show the computational complexity of a routine directly affects the ability of an LLM to simulate its execution. We observe that LLMs execute instructions sequentially and with a low error margin only for short programs or standard procedures. LLMs' code simulation is in tension with their pattern recognition and memorisation capabilities: on tasks where memorisation is detrimental, we propose a novel prompting method to simulate code execution line by line. Empirically, our new Chain of Simulation (CoSm) method improves on the standard Chain of Thought prompting approach by avoiding the pitfalls of memorisation.
The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges
Sep 28, 2023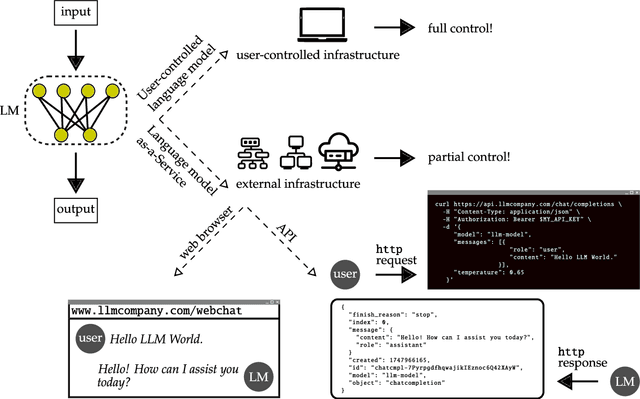

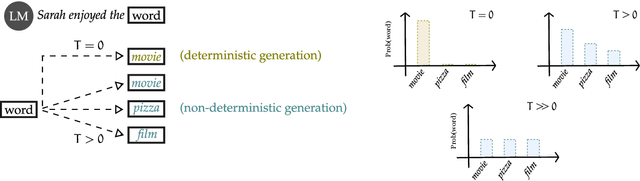
Some of the most powerful language models currently are proprietary systems, accessible only via (typically restrictive) web or software programming interfaces. This is the Language-Models-as-a-Service (LMaaS) paradigm. Contrasting with scenarios where full model access is available, as in the case of open-source models, such closed-off language models create specific challenges for evaluating, benchmarking, and testing them. This paper has two goals: on the one hand, we delineate how the aforementioned challenges act as impediments to the accessibility, replicability, reliability, and trustworthiness (ARRT) of LMaaS. We systematically examine the issues that arise from a lack of information about language models for each of these four aspects. We shed light on current solutions, provide some recommendations, and highlight the directions for future advancements. On the other hand, it serves as a one-stop-shop for the extant knowledge about current, major LMaaS, offering a synthesized overview of the licences and capabilities their interfaces offer.
dtControl 2.0: Explainable Strategy Representation via Decision Tree Learning Steered by Experts
Jan 15, 2021
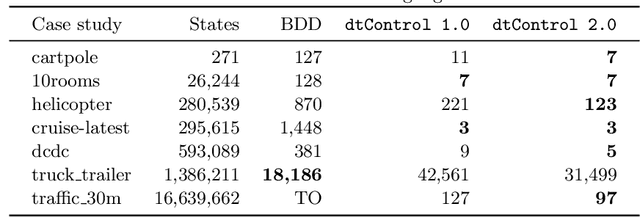
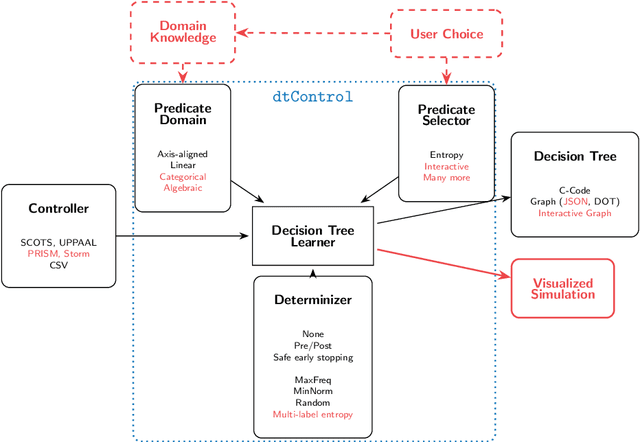
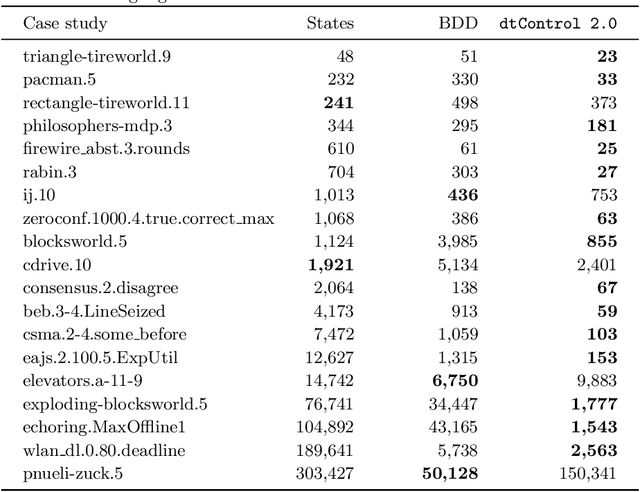
Recent advances have shown how decision trees are apt data structures for concisely representing strategies (or controllers) satisfying various objectives. Moreover, they also make the strategy more explainable. The recent tool dtControl had provided pipelines with tools supporting strategy synthesis for hybrid systems, such as SCOTS and Uppaal Stratego. We present dtControl 2.0, a new version with several fundamentally novel features. Most importantly, the user can now provide domain knowledge to be exploited in the decision tree learning process and can also interactively steer the process based on the dynamically provided information. To this end, we also provide a graphical user interface. It allows for inspection and re-computation of parts of the result, suggesting as well as receiving advice on predicates, and visual simulation of the decision-making process. Besides, we interface model checkers of probabilistic systems, namely Storm and PRISM and provide dedicated support for categorical enumeration-type state variables. Consequently, the controllers are more explainable and smaller.