 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Simulation as a Proxy for High-order Tasks in Large Language Models
Paper and Code
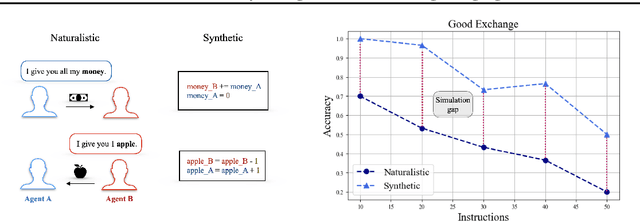


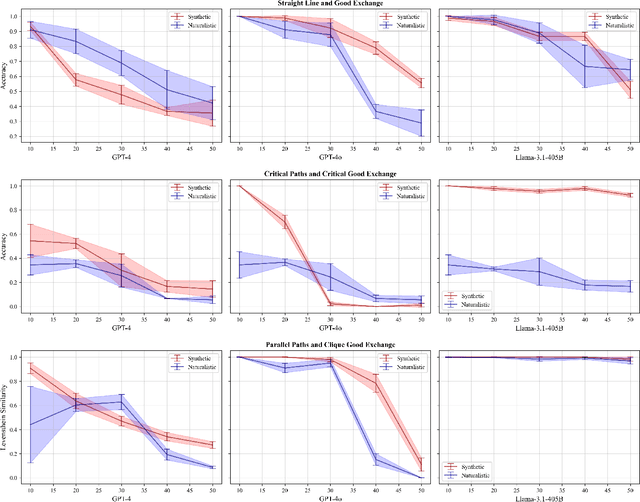
Many reasoning, planning, and problem-solving tasks share an intrinsic algorithmic nature: correctly simulating each step is a sufficient condition to solve them correctly. We collect pairs of naturalistic and synthetic reasoning tasks to assess the capabilities of Large Language Models (LLM). While naturalistic tasks often require careful human handcrafting, we show that synthetic data is, in many cases, a good proxy that is much easier to collect at scale. We leverage common constructs in programming as the counterpart of the building blocks of naturalistic reasoning tasks, such as straight-line programs, code that contains critical paths, and approximate and redundant instructions. We further assess the capabilities of LLMs on sorting problems and repeated operations via sorting algorithms and nested loops. Our synthetic datasets further reveal that while the most powerful LLMs exhibit relatively strong execution capabilities, the process is fragile: it is negatively affected by memorisation and seems to rely heavily on pattern recognition. Our contribution builds upon synthetically testing the reasoning capabilities of LLMs as a scalable complement to handcrafted human-annotated problems.