 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network-Based Parameter Estimation of a Labour Market Agent-Based Model
Feb 17, 2026Agent-based modelling (ABM) is a widespread approach to simulate complex systems. Advancements in computational processing and storage have facilitated the adoption of ABMs across many fields; however, ABMs face challenges that limit their use as decision-support tools. A significant issue is parameter estimation in large-scale ABMs, particularly due to computational constraints on exploring the parameter space. This study evaluates a state-of-the-art simulation-based inference (SBI) framework that uses neural networks (NN) for parameter estimation. This framework is applied to an established labour market ABM based on job transition networks. The ABM is initiated with synthetic datasets and the real U.S. labour market. Next, we compare the effectiveness of summary statistics derived from a list of statistical measures with that learned by an embedded NN. The results demonstrate that the NN-based approach recovers the original parameters when evaluating posterior distributions across various dataset scales and improves efficiency compared to traditional Bayesian methods.
Benchmarking at the Edge of Comprehension
Feb 15, 2026As frontier Large Language Models (LLMs) increasingly saturate new benchmarks shortly after they are published, benchmarking itself is at a juncture: if frontier models keep improving, it will become increasingly hard for humans to generate discriminative tasks, provide accurate ground-truth answers, or evaluate complex solutions. If benchmarking becomes infeasible, our ability to measure any progress in AI is at stake. We refer to this scenario as the post-comprehension regime. In this work, we propose Critique-Resilient Benchmarking, an adversarial framework designed to compare models even when full human understanding is infeasible. Our technique relies on the notion of critique-resilient correctness: an answer is deemed correct if no adversary has convincingly proved otherwise. Unlike standard benchmarking, humans serve as bounded verifiers and focus on localized claims, which preserves evaluation integrity beyond full comprehension of the task. Using an itemized bipartite Bradley-Terry model, we jointly rank LLMs by their ability to solve challenging tasks and to generate difficult yet solvable questions. We showcase the effectiveness of our method in the mathematical domain across eight frontier LLMs, showing that the resulting scores are stable and correlate with external capability measures. Our framework reformulates benchmarking as an adversarial generation-evaluation game in which humans serve as final adjudicators.
Tacit Coordination of Large Language Models
Jan 28, 2026In tacit coordination games with multiple outcomes, purely rational solution concepts, such as Nash equilibria, provide no guidance for which equilibrium to choose. Shelling's theory explains how, in these settings, humans coordinate by relying on focal points: solutions or outcomes that naturally arise because they stand out in some way as salient or prominent to all players. This work studies Large Language Models (LLMs) as players in tacit coordination games, and addresses how, when, and why focal points emerge. We compare and quantify the coordination capabilities of LLMs in cooperative and competitive games for which human experiments are available. We also introduce several learning-free strategies to improve the coordination of LLMs, with themselves and with humans. On a selection of heterogeneous open-source models, including Llama, Qwen, and GPT-oss, we discover that LLMs have a remarkable capability to coordinate and often outperform humans, yet fail on common-sense coordination that involves numbers or nuanced cultural archetypes. This paper constitutes the first large-scale assessment of LLMs' tacit coordination within the theoretical and psychological framework of focal points.
An End-to-end Planning Framework with Agentic LLMs and PDDL
Dec 10, 2025We present an end-to-end framework for planning supported by verifiers. An orchestrator receives a human specification written in natural language and converts it into a PDDL (Planning Domain Definition Language) model, where the domain and problem are iteratively refined by sub-modules (agents) to address common planning requirements, such as time constraints and optimality, as well as ambiguities and contradictions that may exist in the human specification. The validated domain and problem are then passed to an external planning engine to generate a plan. The orchestrator and agents are powered by Large Language Models (LLMs) and require no human intervention at any stage of the process. Finally, a module translates the final plan back into natural language to improve human readability while maintaining the correctness of each step. We demonstrate the flexibility and effectiveness of our framework across various domains and tasks, including the Google NaturalPlan benchmark and PlanBench, as well as planning problems like Blocksworld and the Tower of Hanoi (where LLMs are known to struggle even with small instances). Our framework can be integrated with any PDDL planning engine and validator (such as Fast Downward, LPG, POPF, VAL, and uVAL, which we have tested) and represents a significant step toward end-to-end planning aided by LLMs.
Using causal abstractions to accelerate decision-making in complex bandit problems
Sep 04, 2025
Although real-world decision-making problems can often be encoded as causal multi-armed bandits (CMABs) at different levels of abstraction, a general methodology exploiting the information and computational advantages of each abstraction level is missing. In this paper, we propose AT-UCB, an algorithm which efficiently exploits shared information between CMAB problem instances defined at different levels of abstraction. More specifically, AT-UCB leverages causal abstraction (CA) theory to explore within a cheap-to-simulate and coarse-grained CMAB instance, before employing the traditional upper confidence bound (UCB) algorithm on a restricted set of potentially optimal actions in the CMAB of interest, leading to significant reductions in cumulative regret when compared to the classical UCB algorithm. We illustrate the advantages of AT-UCB theoretically, through a novel upper bound on the cumulative regret, and empirically, by applying AT-UCB to epidemiological simulators with varying resolution and computational cost.
Automatic Differentiation of Agent-Based Models
Sep 03, 2025Agent-based models (ABMs) simulate complex systems by capturing the bottom-up interactions of individual agents comprising the system. Many complex systems of interest, such as epidemics or financial markets, involve thousands or even millions of agents. Consequently, ABMs often become computationally demanding and rely on the calibration of numerous free parameters, which has significantly hindered their widespread adoption. In this paper, we demonstrate that automatic differentiation (AD) techniques can effectively alleviate these computational burdens. By applying AD to ABMs, the gradients of the simulator become readily available, greatly facilitating essential tasks such as calibration and sensitivity analysis. Specifically, we show how AD enables variational inference (VI) techniques for efficient parameter calibration. Our experiments demonstrate substantial performance improvements and computational savings using VI on three prominent ABMs: Axtell's model of firms; Sugarscape; and the SIR epidemiological model. Our approach thus significantly enhances the practicality and scalability of ABMs for studying complex systems.
Emergent Risk Awareness in Rational Agents under Resource Constraints
May 29, 2025
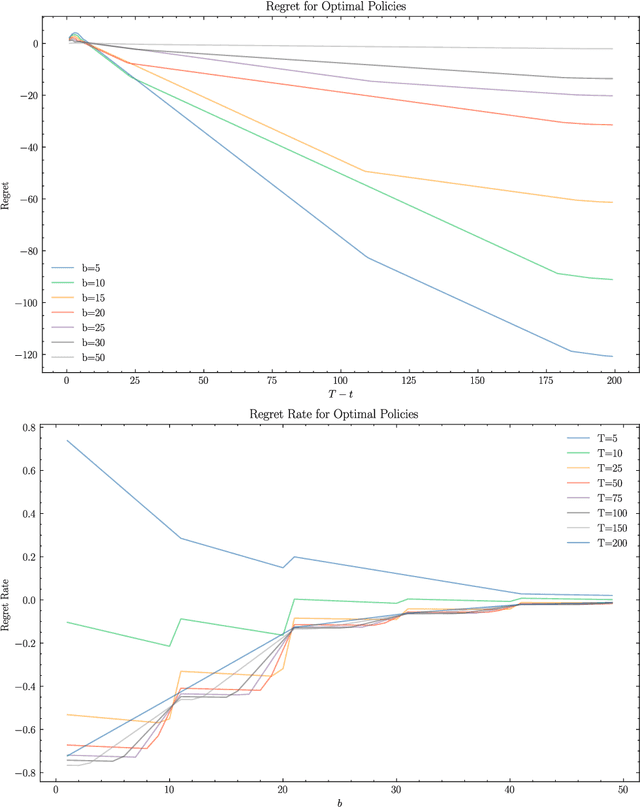

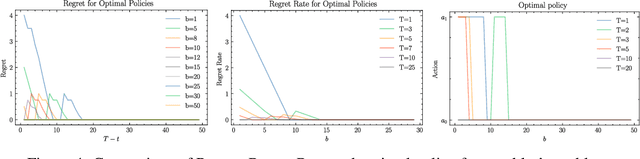
Advanced reasoning models with agentic capabilities (AI agents) are deployed to interact with humans and to solve sequential decision-making problems under (approximate) utility functions and internal models. When such problems have resource or failure constraints where action sequences may be forcibly terminated once resources are exhausted, agents face implicit trade-offs that reshape their utility-driven (rational) behaviour. Additionally, since these agents are typically commissioned by a human principal to act on their behalf, asymmetries in constraint exposure can give rise to previously unanticipated misalignment between human objectives and agent incentives. We formalise this setting through a survival bandit framework, provide theoretical and empirical results that quantify the impact of survival-driven preference shifts, identify conditions under which misalignment emerges and propose mechanisms to mitigate the emergence of risk-seeking or risk-averse behaviours. As a result, this work aims to increase understanding and interpretability of emergent behaviours of AI agents operating under such survival pressure, and offer guidelines for safely deploying such AI systems in critical resource-limited environments.
Large Language Models Miss the Multi-Agent Mark
May 27, 2025
Recent interest in Multi-Agent Systems of Large Language Models (MAS LLMs) has led to an increase in frameworks leveraging multiple LLMs to tackle complex tasks. However, much of this literature appropriates the terminology of MAS without engaging with its foundational principles. In this position paper, we highlight critical discrepancies between MAS theory and current MAS LLMs implementations, focusing on four key areas: the social aspect of agency, environment design, coordination and communication protocols, and measuring emergent behaviours. Our position is that many MAS LLMs lack multi-agent characteristics such as autonomy, social interaction, and structured environments, and often rely on oversimplified, LLM-centric architectures. The field may slow down and lose traction by revisiting problems the MAS literature has already addressed. Therefore, we systematically analyse this issue and outline associated research opportunities; we advocate for better integrating established MAS concepts and more precise terminology to avoid mischaracterisation and missed opportunities.
Fixed Point Explainability
May 18, 2025



This paper introduces a formal notion of fixed point explanations, inspired by the "why regress" principle, to assess, through recursive applications, the stability of the interplay between a model and its explainer. Fixed point explanations satisfy properties like minimality, stability, and faithfulness, revealing hidden model behaviours and explanatory weaknesses. We define convergence conditions for several classes of explainers, from feature-based to mechanistic tools like Sparse AutoEncoders, and we report quantitative and qualitative results.
Language Models Are Implicitly Continuous
Apr 04, 2025Language is typically modelled with discrete sequences. However, the most successful approaches to language modelling, namely neural networks, are continuous and smooth function approximators. In this work, we show that Transformer-based language models implicitly learn to represent sentences as continuous-time functions defined over a continuous input space. This phenomenon occurs in most state-of-the-art Large Language Models (LLMs), including Llama2, Llama3, Phi3, Gemma, Gemma2, and Mistral, and suggests that LLMs reason about language in ways that fundamentally differ from humans. Our work formally extends Transformers to capture the nuances of time and space continuity in both input and output space. Our results challenge the traditional interpretation of how LLMs understand language, with several linguistic and engineering implications.