 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing causal abstractions to accelerate decision-making in complex bandit problems
Sep 04, 2025
Although real-world decision-making problems can often be encoded as causal multi-armed bandits (CMABs) at different levels of abstraction, a general methodology exploiting the information and computational advantages of each abstraction level is missing. In this paper, we propose AT-UCB, an algorithm which efficiently exploits shared information between CMAB problem instances defined at different levels of abstraction. More specifically, AT-UCB leverages causal abstraction (CA) theory to explore within a cheap-to-simulate and coarse-grained CMAB instance, before employing the traditional upper confidence bound (UCB) algorithm on a restricted set of potentially optimal actions in the CMAB of interest, leading to significant reductions in cumulative regret when compared to the classical UCB algorithm. We illustrate the advantages of AT-UCB theoretically, through a novel upper bound on the cumulative regret, and empirically, by applying AT-UCB to epidemiological simulators with varying resolution and computational cost.
Automatic Differentiation of Agent-Based Models
Sep 03, 2025Agent-based models (ABMs) simulate complex systems by capturing the bottom-up interactions of individual agents comprising the system. Many complex systems of interest, such as epidemics or financial markets, involve thousands or even millions of agents. Consequently, ABMs often become computationally demanding and rely on the calibration of numerous free parameters, which has significantly hindered their widespread adoption. In this paper, we demonstrate that automatic differentiation (AD) techniques can effectively alleviate these computational burdens. By applying AD to ABMs, the gradients of the simulator become readily available, greatly facilitating essential tasks such as calibration and sensitivity analysis. Specifically, we show how AD enables variational inference (VI) techniques for efficient parameter calibration. Our experiments demonstrate substantial performance improvements and computational savings using VI on three prominent ABMs: Axtell's model of firms; Sugarscape; and the SIR epidemiological model. Our approach thus significantly enhances the practicality and scalability of ABMs for studying complex systems.
Emergent Risk Awareness in Rational Agents under Resource Constraints
May 29, 2025
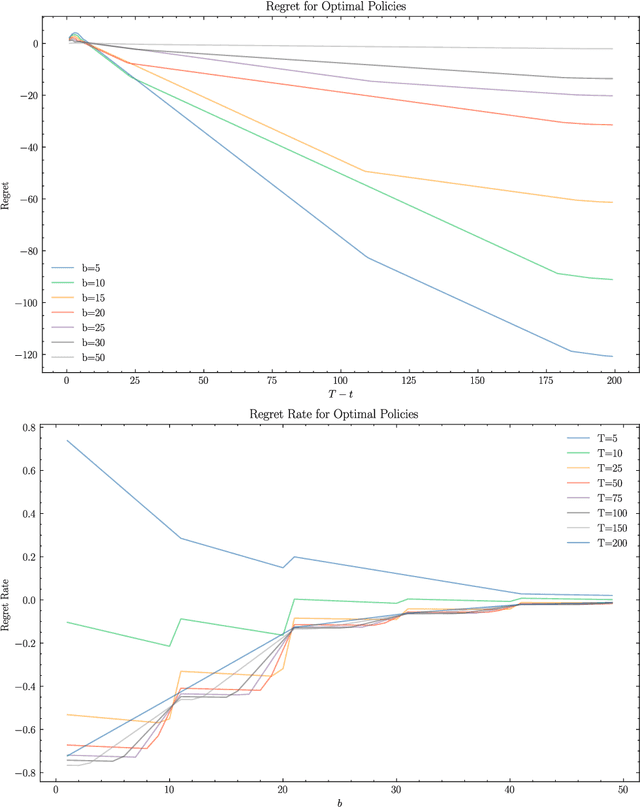

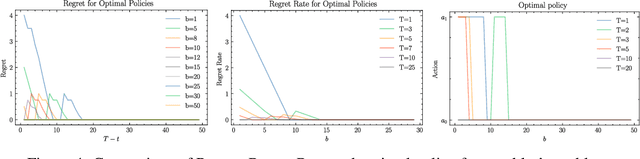
Advanced reasoning models with agentic capabilities (AI agents) are deployed to interact with humans and to solve sequential decision-making problems under (approximate) utility functions and internal models. When such problems have resource or failure constraints where action sequences may be forcibly terminated once resources are exhausted, agents face implicit trade-offs that reshape their utility-driven (rational) behaviour. Additionally, since these agents are typically commissioned by a human principal to act on their behalf, asymmetries in constraint exposure can give rise to previously unanticipated misalignment between human objectives and agent incentives. We formalise this setting through a survival bandit framework, provide theoretical and empirical results that quantify the impact of survival-driven preference shifts, identify conditions under which misalignment emerges and propose mechanisms to mitigate the emergence of risk-seeking or risk-averse behaviours. As a result, this work aims to increase understanding and interpretability of emergent behaviours of AI agents operating under such survival pressure, and offer guidelines for safely deploying such AI systems in critical resource-limited environments.
A multi-objective combinatorial optimisation framework for large scale hierarchical population synthesis
Jul 03, 2024



In agent-based simulations, synthetic populations of agents are commonly used to represent the structure, behaviour, and interactions of individuals. However, generating a synthetic population that accurately reflects real population statistics is a challenging task, particularly when performed at scale. In this paper, we propose a multi objective combinatorial optimisation technique for large scale population synthesis. We demonstrate the effectiveness of our approach by generating a synthetic population for selected regions and validating it on contingency tables from real population data. Our approach supports complex hierarchical structures between individuals and households, is scalable to large populations and achieves minimal contigency table reconstruction error. Hence, it provides a useful tool for policymakers and researchers for simulating the dynamics of complex populations.
Causally Abstracted Multi-armed Bandits
Apr 26, 2024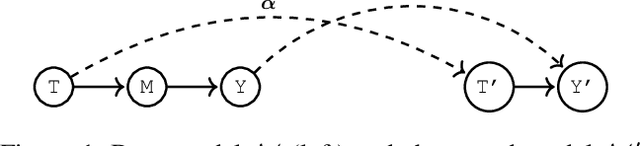


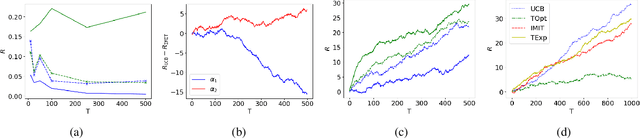
Multi-armed bandits (MAB) and causal MABs (CMAB) are established frameworks for decision-making problems. The majority of prior work typically studies and solves individual MAB and CMAB in isolation for a given problem and associated data. However, decision-makers are often faced with multiple related problems and multi-scale observations where joint formulations are needed in order to efficiently exploit the problem structures and data dependencies. Transfer learning for CMABs addresses the situation where models are defined on identical variables, although causal connections may differ. In this work, we extend transfer learning to setups involving CMABs defined on potentially different variables, with varying degrees of granularity, and related via an abstraction map. Formally, we introduce the problem of causally abstracted MABs (CAMABs) by relying on the theory of causal abstraction in order to express a rigorous abstraction map. We propose algorithms to learn in a CAMAB, and study their regret. We illustrate the limitations and the strengths of our algorithms on a real-world scenario related to online advertising.
Interventionally Consistent Surrogates for Agent-based Simulators
Dec 18, 2023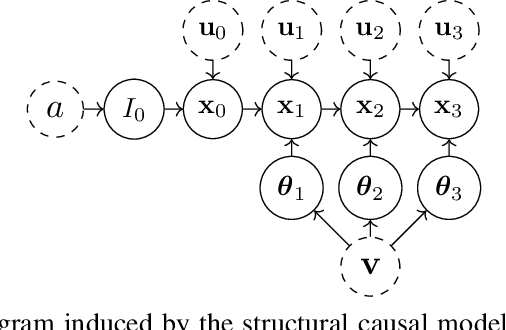
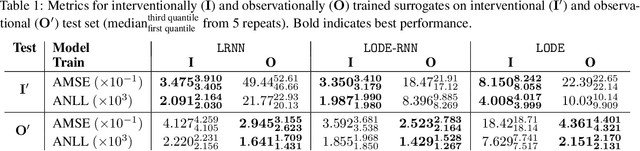
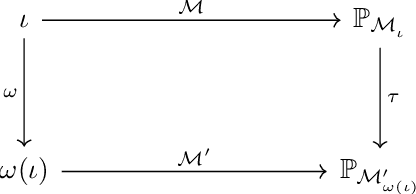
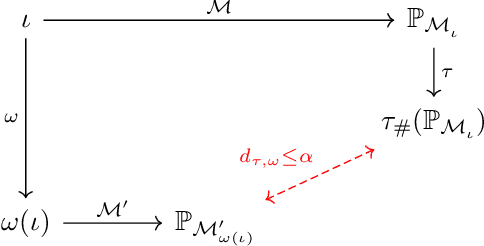
Agent-based simulators provide granular representations of complex intelligent systems by directly modelling the interactions of the system's constituent agents. Their high-fidelity nature enables hyper-local policy evaluation and testing of what-if scenarios, but is associated with large computational costs that inhibits their widespread use. Surrogate models can address these computational limitations, but they must behave consistently with the agent-based model under policy interventions of interest. In this paper, we capitalise on recent developments on causal abstractions to develop a framework for learning interventionally consistent surrogate models for agent-based simulators. Our proposed approach facilitates rapid experimentation with policy interventions in complex systems, while inducing surrogates to behave consistently with high probability with respect to the agent-based simulator across interventions of interest. We demonstrate with empirical studies that observationally trained surrogates can misjudge the effect of interventions and misguide policymakers towards suboptimal policies, while surrogates trained for interventional consistency with our proposed method closely mimic the behaviour of an agent-based model under interventions of interest.
Explicit Explore, Exploit, or Escape ($E^4$): near-optimal safety-constrained reinforcement learning in polynomial time
Nov 14, 2021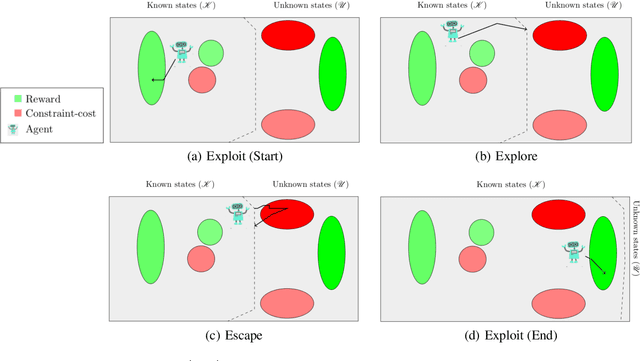
In reinforcement learning (RL), an agent must explore an initially unknown environment in order to learn a desired behaviour. When RL agents are deployed in real world environments, safety is of primary concern. Constrained Markov decision processes (CMDPs) can provide long-term safety constraints; however, the agent may violate the constraints in an effort to explore its environment. This paper proposes a model-based RL algorithm called Explicit Explore, Exploit, or Escape ($E^{4}$), which extends the Explicit Explore or Exploit ($E^{3}$) algorithm to a robust CMDP setting. $E^4$ explicitly separates exploitation, exploration, and escape CMDPs, allowing targeted policies for policy improvement across known states, discovery of unknown states, as well as safe return to known states. $E^4$ robustly optimises these policies on the worst-case CMDP from a set of CMDP models consistent with the empirical observations of the deployment environment. Theoretical results show that $E^4$ finds a near-optimal constraint-satisfying policy in polynomial time whilst satisfying safety constraints throughout the learning process. We discuss robust-constrained offline optimisation algorithms as well as how to incorporate uncertainty in transition dynamics of unknown states based on empirical inference and prior knowledge.