 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBulk-Calibrated Credal Ambiguity Sets: Fast, Tractable Decision Making under Out-of-Sample Contamination
Jan 29, 2026Distributionally robust optimisation (DRO) minimises the worst-case expected loss over an ambiguity set that can capture distributional shifts in out-of-sample environments. While Huber (linear-vacuous) contamination is a classical minimal-assumption model for an $\varepsilon$-fraction of arbitrary perturbations, including it in an ambiguity set can make the worst-case risk infinite and the DRO objective vacuous unless one imposes strong boundedness or support assumptions. We address these challenges by introducing bulk-calibrated credal ambiguity sets: we learn a high-mass bulk set from data while considering contamination inside the bulk and bounding the remaining tail contribution separately. This leads to a closed-form, finite $\mathrm{mean}+\sup$ robust objective and tractable linear or second-order cone programs for common losses and bulk geometries. Through this framework, we highlight and exploit the equivalence between the imprecise probability (IP) notion of upper expectation and the worst-case risk, demonstrating how IP credal sets translate into DRO objectives with interpretable tolerance levels. Experiments on heavy-tailed inventory control, geographically shifted house-price regression, and demographically shifted text classification show competitive robustness-accuracy trade-offs and efficient optimisation times, using Bayesian, frequentist, or empirical reference distributions.
Distributionally Robust Causal Abstractions
Oct 06, 2025Causal Abstraction (CA) theory provides a principled framework for relating causal models that describe the same system at different levels of granularity while ensuring interventional consistency between them. Recently, several approaches for learning CAs have been proposed, but all assume fixed and well-specified exogenous distributions, making them vulnerable to environmental shifts and misspecification. In this work, we address these limitations by introducing the first class of distributionally robust CAs and their associated learning algorithms. The latter cast robust causal abstraction learning as a constrained min-max optimization problem with Wasserstein ambiguity sets. We provide theoretical results, for both empirical and Gaussian environments, leading to principled selection of the level of robustness via the radius of these sets. Furthermore, we present empirical evidence across different problems and CA learning methods, demonstrating our framework's robustness not only to environmental shifts but also to structural model and intervention mapping misspecification.
Decision Making under Model Misspecification: DRO with Robust Bayesian Ambiguity Sets
May 06, 2025Distributionally Robust Optimisation (DRO) protects risk-averse decision-makers by considering the worst-case risk within an ambiguity set of distributions based on the empirical distribution or a model. To further guard against finite, noisy data, model-based approaches admit Bayesian formulations that propagate uncertainty from the posterior to the decision-making problem. However, when the model is misspecified, the decision maker must stretch the ambiguity set to contain the data-generating process (DGP), leading to overly conservative decisions. We address this challenge by introducing DRO with Robust, to model misspecification, Bayesian Ambiguity Sets (DRO-RoBAS). These are Maximum Mean Discrepancy ambiguity sets centred at a robust posterior predictive distribution that incorporates beliefs about the DGP. We show that the resulting optimisation problem obtains a dual formulation in the Reproducing Kernel Hilbert Space and we give probabilistic guarantees on the tolerance level of the ambiguity set. Our method outperforms other Bayesian and empirical DRO approaches in out-of-sample performance on the Newsvendor and Portfolio problems with various cases of model misspecification.
Federated Generalised Variational Inference: A Robust Probabilistic Federated Learning Framework
Feb 02, 2025



We introduce FedGVI, a probabilistic Federated Learning (FL) framework that is provably robust to both prior and likelihood misspecification. FedGVI addresses limitations in both frequentist and Bayesian FL by providing unbiased predictions under model misspecification, with calibrated uncertainty quantification. Our approach generalises previous FL approaches, specifically Partitioned Variational Inference (Ashman et al., 2022), by allowing robust and conjugate updates, decreasing computational complexity at the clients. We offer theoretical analysis in terms of fixed-point convergence, optimality of the cavity distribution, and provable robustness. Additionally, we empirically demonstrate the effectiveness of FedGVI in terms of improved robustness and predictive performance on multiple synthetic and real world classification data sets.
Decision Making under the Exponential Family: Distributionally Robust Optimisation with Bayesian Ambiguity Sets
Nov 25, 2024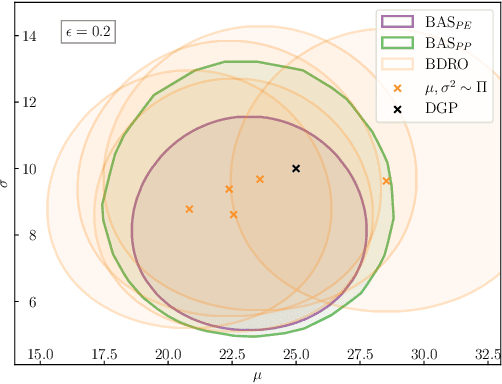
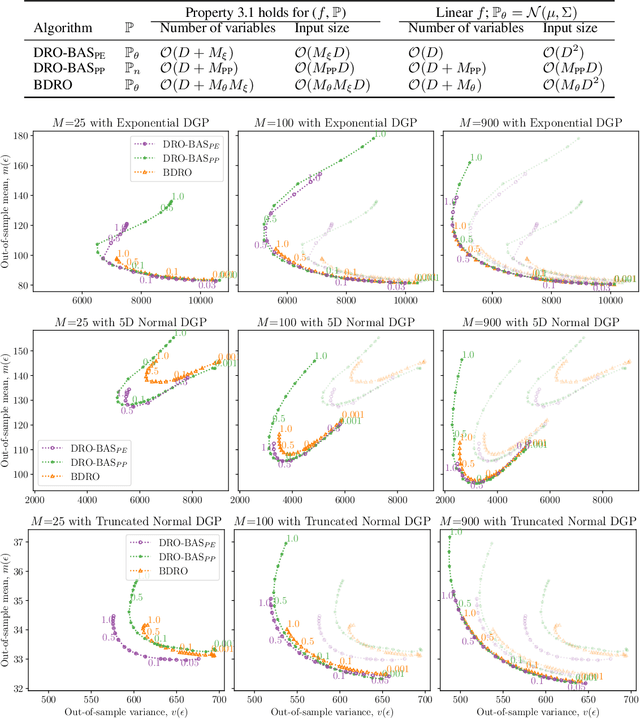

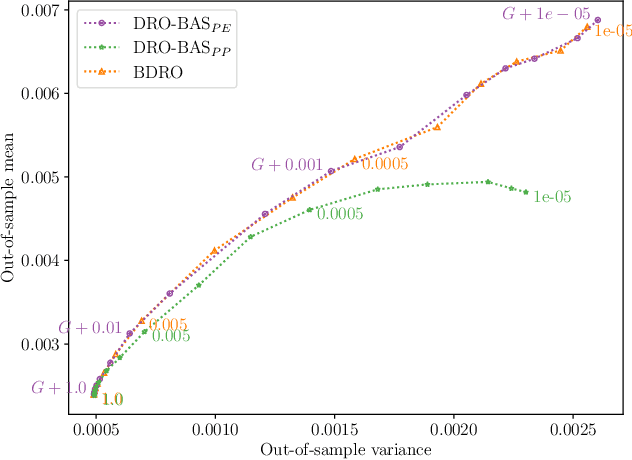
Decision making under uncertainty is challenging as the data-generating process (DGP) is often unknown. Bayesian inference proceeds by estimating the DGP through posterior beliefs on the model's parameters. However, minimising the expected risk under these beliefs can lead to suboptimal decisions due to model uncertainty or limited, noisy observations. To address this, we introduce Distributionally Robust Optimisation with Bayesian Ambiguity Sets (DRO-BAS) which hedges against model uncertainty by optimising the worst-case risk over a posterior-informed ambiguity set. We provide two such sets, based on posterior expectations (DRO-BAS(PE)) or posterior predictives (DRO-BAS(PP)) and prove that both admit, under conditions, strong dual formulations leading to efficient single-stage stochastic programs which are solved with a sample average approximation. For DRO-BAS(PE) this covers all conjugate exponential family members while for DRO-BAS(PP) this is shown under conditions on the predictive's moment generating function. Our DRO-BAS formulations Pareto dominate existing Bayesian DRO on the Newsvendor problem and achieve faster solve times with comparable robustness on the Portfolio problem.
Generating Origin-Destination Matrices in Neural Spatial Interaction Models
Oct 09, 2024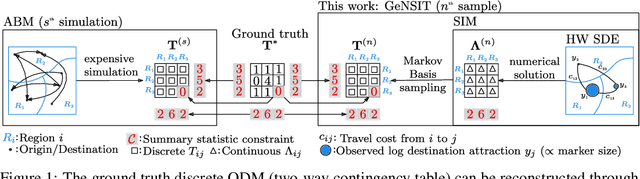


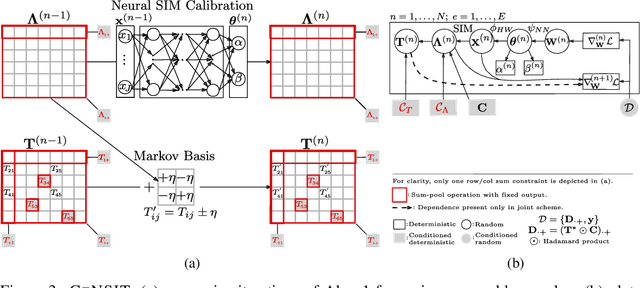
Agent-based models (ABMs) are proliferating as decision-making tools across policy areas in transportation, economics, and epidemiology. In these models, a central object of interest is the discrete origin-destination matrix which captures spatial interactions and agent trip counts between locations. Existing approaches resort to continuous approximations of this matrix and subsequent ad-hoc discretisations in order to perform ABM simulation and calibration. This impedes conditioning on partially observed summary statistics, fails to explore the multimodal matrix distribution over a discrete combinatorial support, and incurs discretisation errors. To address these challenges, we introduce a computationally efficient framework that scales linearly with the number of origin-destination pairs, operates directly on the discrete combinatorial space, and learns the agents' trip intensity through a neural differential equation that embeds spatial interactions. Our approach outperforms the prior art in terms of reconstruction error and ground truth matrix coverage, at a fraction of the computational cost. We demonstrate these benefits in large-scale spatial mobility ABMs in Cambridge, UK and Washington, DC, USA.
Physics-Informed Variational State-Space Gaussian Processes
Sep 20, 2024Differential equations are important mechanistic models that are integral to many scientific and engineering applications. With the abundance of available data there has been a growing interest in data-driven physics-informed models. Gaussian processes (GPs) are particularly suited to this task as they can model complex, non-linear phenomena whilst incorporating prior knowledge and quantifying uncertainty. Current approaches have found some success but are limited as they either achieve poor computational scalings or focus only on the temporal setting. This work addresses these issues by introducing a variational spatio-temporal state-space GP that handles linear and non-linear physical constraints while achieving efficient linear-in-time computation costs. We demonstrate our methods in a range of synthetic and real-world settings and outperform the current state-of-the-art in both predictive and computational performance.
Distributionally Robust Optimisation with Bayesian Ambiguity Sets
Sep 05, 2024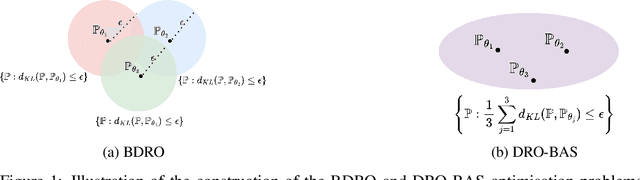
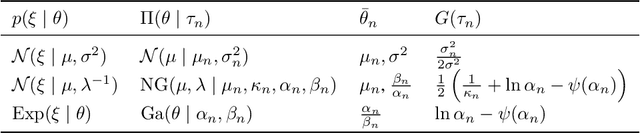
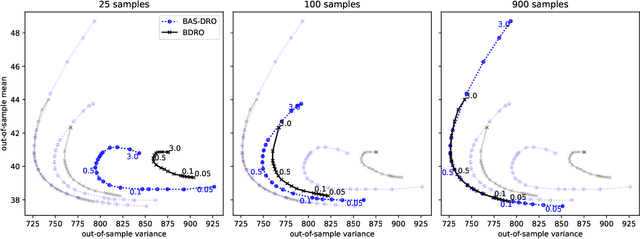
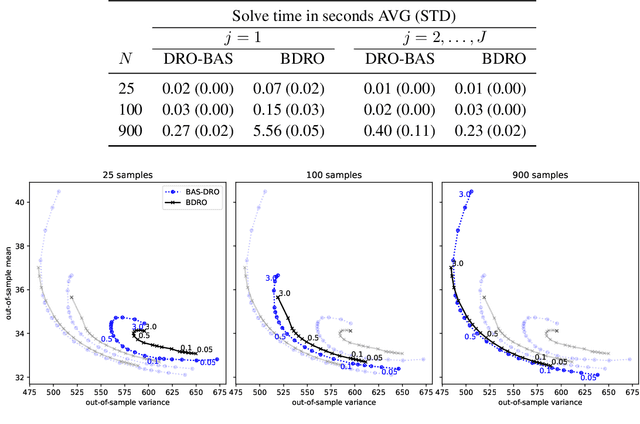
Decision making under uncertainty is challenging since the data-generating process (DGP) is often unknown. Bayesian inference proceeds by estimating the DGP through posterior beliefs about the model's parameters. However, minimising the expected risk under these posterior beliefs can lead to sub-optimal decisions due to model uncertainty or limited, noisy observations. To address this, we introduce Distributionally Robust Optimisation with Bayesian Ambiguity Sets (DRO-BAS) which hedges against uncertainty in the model by optimising the worst-case risk over a posterior-informed ambiguity set. We show that our method admits a closed-form dual representation for many exponential family members and showcase its improved out-of-sample robustness against existing Bayesian DRO methodology in the Newsvendor problem.
Causally Abstracted Multi-armed Bandits
Apr 26, 2024


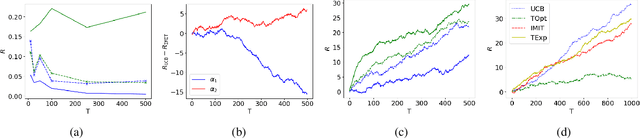
Multi-armed bandits (MAB) and causal MABs (CMAB) are established frameworks for decision-making problems. The majority of prior work typically studies and solves individual MAB and CMAB in isolation for a given problem and associated data. However, decision-makers are often faced with multiple related problems and multi-scale observations where joint formulations are needed in order to efficiently exploit the problem structures and data dependencies. Transfer learning for CMABs addresses the situation where models are defined on identical variables, although causal connections may differ. In this work, we extend transfer learning to setups involving CMABs defined on potentially different variables, with varying degrees of granularity, and related via an abstraction map. Formally, we introduce the problem of causally abstracted MABs (CAMABs) by relying on the theory of causal abstraction in order to express a rigorous abstraction map. We propose algorithms to learn in a CAMAB, and study their regret. We illustrate the limitations and the strengths of our algorithms on a real-world scenario related to online advertising.
Interventionally Consistent Surrogates for Agent-based Simulators
Dec 18, 2023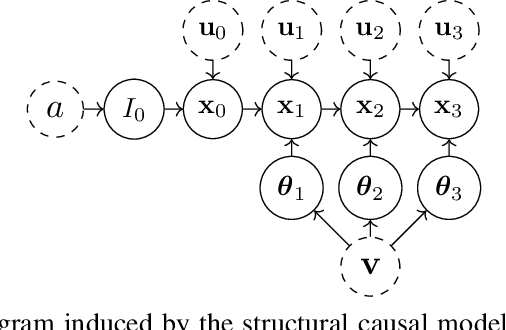
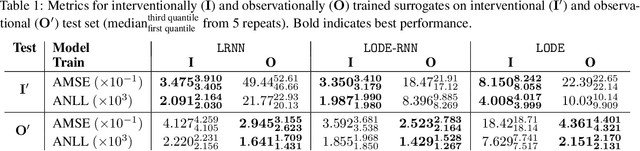
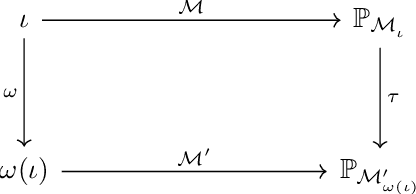
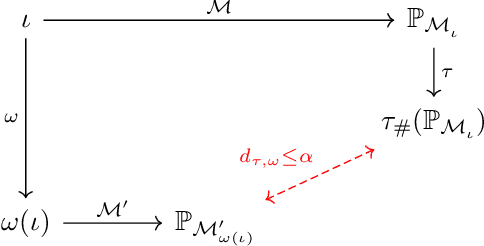
Agent-based simulators provide granular representations of complex intelligent systems by directly modelling the interactions of the system's constituent agents. Their high-fidelity nature enables hyper-local policy evaluation and testing of what-if scenarios, but is associated with large computational costs that inhibits their widespread use. Surrogate models can address these computational limitations, but they must behave consistently with the agent-based model under policy interventions of interest. In this paper, we capitalise on recent developments on causal abstractions to develop a framework for learning interventionally consistent surrogate models for agent-based simulators. Our proposed approach facilitates rapid experimentation with policy interventions in complex systems, while inducing surrogates to behave consistently with high probability with respect to the agent-based simulator across interventions of interest. We demonstrate with empirical studies that observationally trained surrogates can misjudge the effect of interventions and misguide policymakers towards suboptimal policies, while surrogates trained for interventional consistency with our proposed method closely mimic the behaviour of an agent-based model under interventions of interest.