 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Inference and Closure Learning via Adaptive Surrogates for ODEs and PDEs
Mar 04, 2026Inverse problems are the task of calibrating models to match data. They play a pivotal role in diverse engineering applications by allowing practitioners to align models with reality. In many applications, engineers and scientists do not have a complete picture of i) the detailed properties of a system (such as material properties, geometry, initial conditions, etc.); ii) the complete laws describing all dynamics at play (such as friction laws, complicated damping phenomena, and general nonlinear interactions). In this paper, we develop a principled methodology for leveraging data from collections of distinct yet related physical systems to jointly estimate the individual model parameters of each system, and learn the shared unknown dynamics in the form of an ML-based closure model. To robustly infer the unknown parameters for each system, we employ a hierarchical Bayesian framework, which allows for the joint inference of multiple systems and their population-level statistics. To learn the closures, we use a maximum marginal likelihood estimate of a neural network embeded within the ODE/PDE formulation of the problem. To realize this framework we utilize the ensemble Metropolis-Adjusted Langevin Algorithm (MALA) for stable and efficient sampling. To mitigate the computational bottleneck of repetitive forward evaluations in solving inverse problems, we introduce a bilevel optimization strategy to simultaneously train a surrogate forward model alongside the inference. Within this framework, we evaluate and compare distinct surrogate architectures, specifically Fourier Neural Operators (FNO) and parametric Physics-Informed Neural Network (PINNs).
Koopman Autoencoders with Continuous-Time Latent Dynamics for Fluid Dynamics Forecasting
Feb 02, 2026Data-driven surrogate models have emerged as powerful tools for accelerating the simulation of turbulent flows. However, classical approaches which perform autoregressive rollouts often trade off between strong short-term accuracy and long-horizon stability. Koopman autoencoders, inspired by Koopman operator theory, provide a physics-based alternative by mapping nonlinear dynamics into a latent space where linear evolution is conducted. In practice, most existing formulations operate in a discrete-time setting, limiting temporal flexibility. In this work, we introduce a continuous-time Koopman framework that models latent evolution through numerical integration schemes. By allowing variable timesteps at inference, the method demonstrates robustness to temporal resolution and generalizes beyond training regimes. In addition, the learned dynamics closely adhere to the analytical matrix exponential solution, enabling efficient long-horizon forecasting. We evaluate the approach on classical CFD benchmarks and report accuracy, stability, and extrapolation properties.
Efficient Deconvolution in Populational Inverse Problems
May 26, 2025This work is focussed on the inversion task of inferring the distribution over parameters of interest leading to multiple sets of observations. The potential to solve such distributional inversion problems is driven by increasing availability of data, but a major roadblock is blind deconvolution, arising when the observational noise distribution is unknown. However, when data originates from collections of physical systems, a population, it is possible to leverage this information to perform deconvolution. To this end, we propose a methodology leveraging large data sets of observations, collected from different instantiations of the same physical processes, to simultaneously deconvolve the data corrupting noise distribution, and to identify the distribution over model parameters defining the physical processes. A parameter-dependent mathematical model of the physical process is employed. A loss function characterizing the match between the observed data and the output of the mathematical model is defined; it is minimized as a function of the both the parameter inputs to the model of the physics and the parameterized observational noise. This coupled problem is addressed with a modified gradient descent algorithm that leverages specific structure in the noise model. Furthermore, a new active learning scheme is proposed, based on adaptive empirical measures, to train a surrogate model to be accurate in parameter regions of interest; this approach accelerates computation and enables automatic differentiation of black-box, potentially nondifferentiable, code computing parameter-to-solution maps. The proposed methodology is demonstrated on porous medium flow, damped elastodynamics, and simplified models of atmospheric dynamics.
Generating Origin-Destination Matrices in Neural Spatial Interaction Models
Oct 09, 2024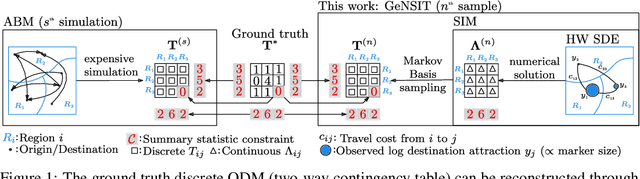


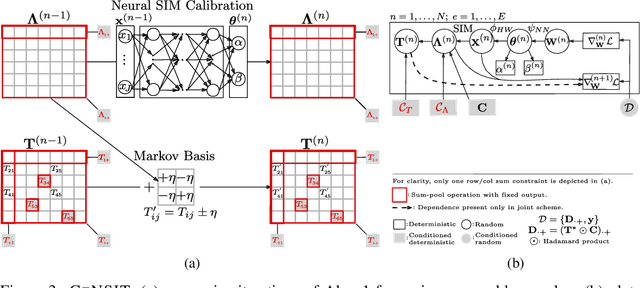
Agent-based models (ABMs) are proliferating as decision-making tools across policy areas in transportation, economics, and epidemiology. In these models, a central object of interest is the discrete origin-destination matrix which captures spatial interactions and agent trip counts between locations. Existing approaches resort to continuous approximations of this matrix and subsequent ad-hoc discretisations in order to perform ABM simulation and calibration. This impedes conditioning on partially observed summary statistics, fails to explore the multimodal matrix distribution over a discrete combinatorial support, and incurs discretisation errors. To address these challenges, we introduce a computationally efficient framework that scales linearly with the number of origin-destination pairs, operates directly on the discrete combinatorial space, and learns the agents' trip intensity through a neural differential equation that embeds spatial interactions. Our approach outperforms the prior art in terms of reconstruction error and ground truth matrix coverage, at a fraction of the computational cost. We demonstrate these benefits in large-scale spatial mobility ABMs in Cambridge, UK and Washington, DC, USA.
A Primer on Variational Inference for Physics-Informed Deep Generative Modelling
Sep 10, 2024
Variational inference (VI) is a computationally efficient and scalable methodology for approximate Bayesian inference. It strikes a balance between accuracy of uncertainty quantification and practical tractability. It excels at generative modelling and inversion tasks due to its built-in Bayesian regularisation and flexibility, essential qualities for physics related problems. Deriving the central learning objective for VI must often be tailored to new learning tasks where the nature of the problems dictates the conditional dependence between variables of interest, such as arising in physics problems. In this paper, we provide an accessible and thorough technical introduction to VI for forward and inverse problems, guiding the reader through standard derivations of the VI framework and how it can best be realized through deep learning. We then review and unify recent literature exemplifying the creative flexibility allowed by VI. This paper is designed for a general scientific audience looking to solve physics-based problems with an emphasis on uncertainty quantification.
Autoencoders in Function Space
Aug 02, 2024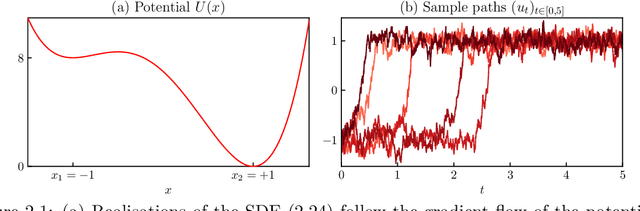
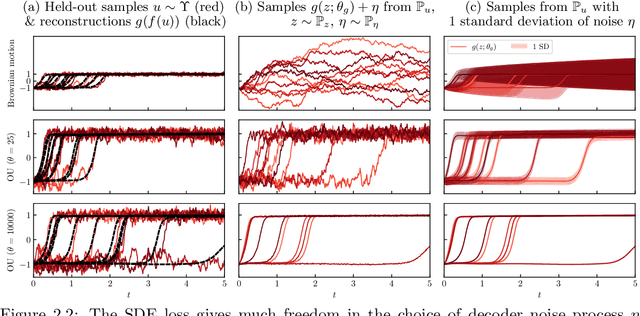
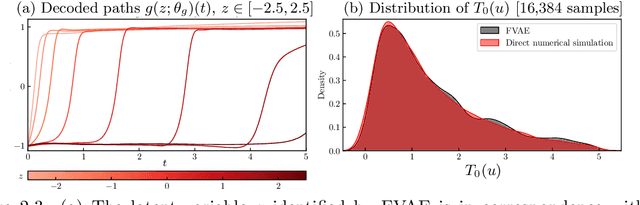
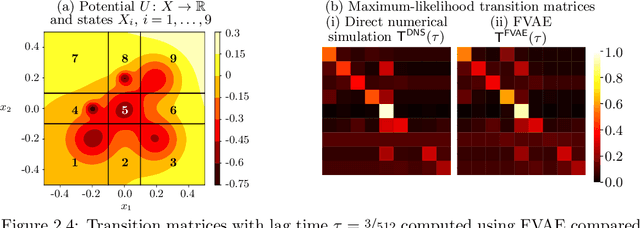
Autoencoders have found widespread application, in both their original deterministic form and in their variational formulation (VAEs). In scientific applications it is often of interest to consider data that are comprised of functions; the same perspective is useful in image processing. In practice, discretisation (of differential equations arising in the sciences) or pixellation (of images) renders problems finite dimensional, but conceiving first of algorithms that operate on functions, and only then discretising or pixellating, leads to better algorithms that smoothly operate between different levels of discretisation or pixellation. In this paper function-space versions of the autoencoder (FAE) and variational autoencoder (FVAE) are introduced, analysed, and deployed. Well-definedness of the objective function governing VAEs is a subtle issue, even in finite dimension, and more so on function space. The FVAE objective is well defined whenever the data distribution is compatible with the chosen generative model; this happens, for example, when the data arise from a stochastic differential equation. The FAE objective is valid much more broadly, and can be straightforwardly applied to data governed by differential equations. Pairing these objectives with neural operator architectures, which can thus be evaluated on any mesh, enables new applications of autoencoders to inpainting, superresolution, and generative modelling of scientific data.
Efficient Prior Calibration From Indirect Data
May 28, 2024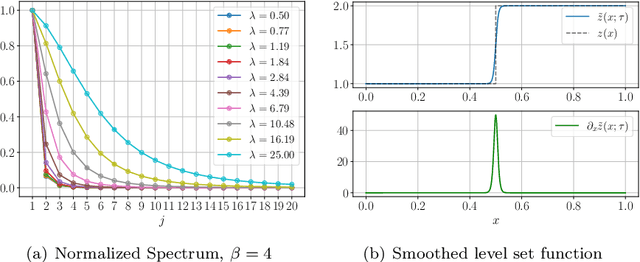
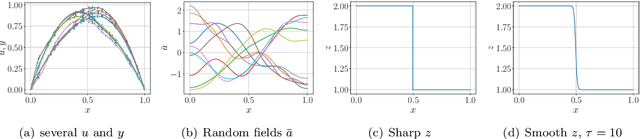
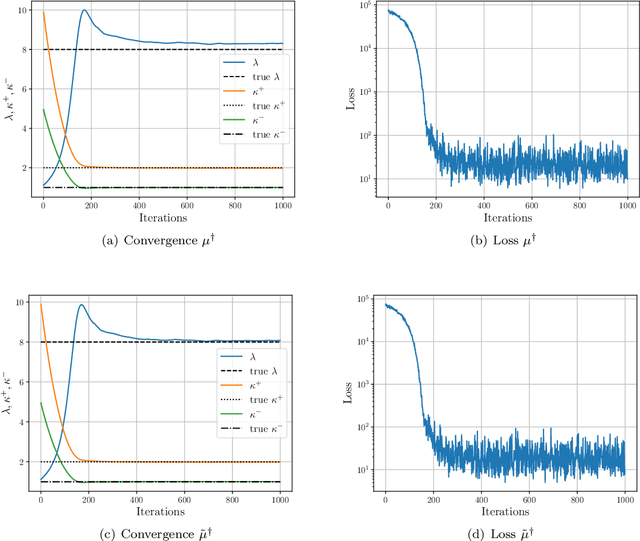
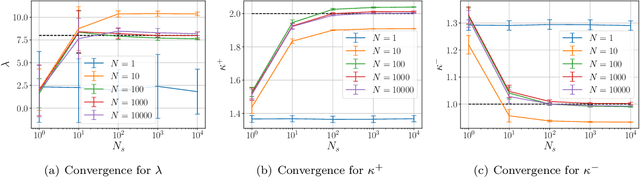
Bayesian inversion is central to the quantification of uncertainty within problems arising from numerous applications in science and engineering. To formulate the approach, four ingredients are required: a forward model mapping the unknown parameter to an element of a solution space, often the solution space for a differential equation; an observation operator mapping an element of the solution space to the data space; a noise model describing how noise pollutes the observations; and a prior model describing knowledge about the unknown parameter before the data is acquired. This paper is concerned with learning the prior model from data; in particular, learning the prior from multiple realizations of indirect data obtained through the noisy observation process. The prior is represented, using a generative model, as the pushforward of a Gaussian in a latent space; the pushforward map is learned by minimizing an appropriate loss function. A metric that is well-defined under empirical approximation is used to define the loss function for the pushforward map to make an implementable methodology. Furthermore, an efficient residual-based neural operator approximation of the forward model is proposed and it is shown that this may be learned concurrently with the pushforward map, using a bilevel optimization formulation of the problem; this use of neural operator approximation has the potential to make prior learning from indirect data more computationally efficient, especially when the observation process is expensive, non-smooth or not known. The ideas are illustrated with the Darcy flow inverse problem of finding permeability from piezometric head measurements.
Towards Multilevel Modelling of Train Passing Events on the Staffordshire Bridge
Mar 26, 2024



We suggest a multilevel model, to represent aggregate train-passing events from the Staffordshire bridge monitoring system. We formulate a combined model from simple units, representing strain envelopes (of each train passing) for two types of commuter train. The measurements are treated as a longitudinal dataset and represented with a (low-rank approximation) hierarchical Gaussian process. For each unit in the combined model, we encode domain expertise as boundary condition constraints and work towards a general representation of the strain response. Looking forward, this should allow for the simulation of train types that were previously unobserved in the training data. For example, trains with more passengers or freights with a heavier payload. The strain event simulations are valuable since they can inform further experiments (including FEM calibration, fatigue analysis, or design) to test the bridge in hypothesised scenarios.
Improving embedding of graphs with missing data by soft manifolds
Nov 29, 2023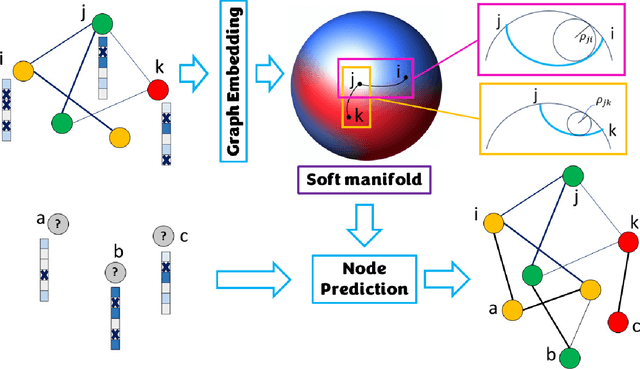
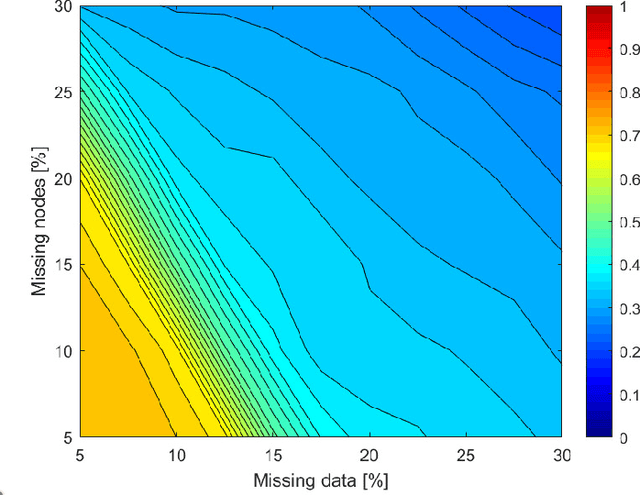
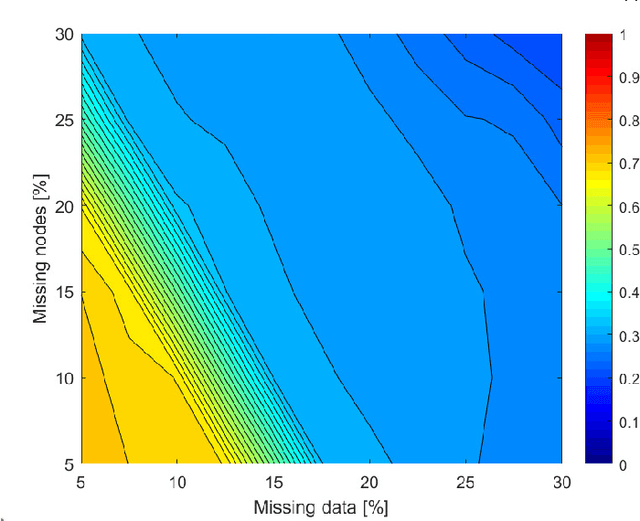
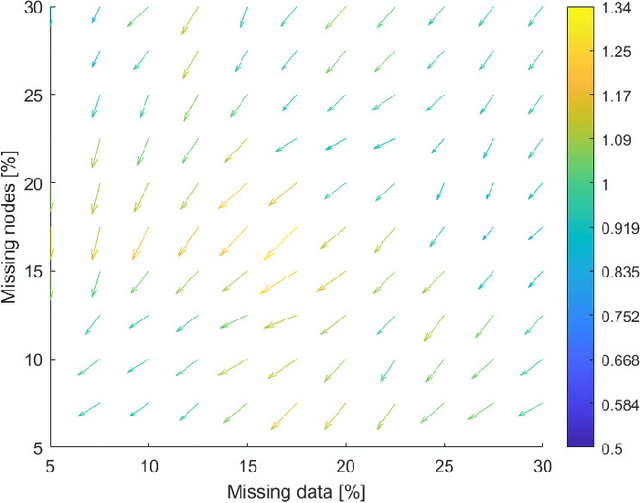
Embedding graphs in continous spaces is a key factor in designing and developing algorithms for automatic information extraction to be applied in diverse tasks (e.g., learning, inferring, predicting). The reliability of graph embeddings directly depends on how much the geometry of the continuous space matches the graph structure. Manifolds are mathematical structure that can enable to incorporate in their topological spaces the graph characteristics, and in particular nodes distances. State-of-the-art of manifold-based graph embedding algorithms take advantage of the assumption that the projection on a tangential space of each point in the manifold (corresponding to a node in the graph) would locally resemble a Euclidean space. Although this condition helps in achieving efficient analytical solutions to the embedding problem, it does not represent an adequate set-up to work with modern real life graphs, that are characterized by weighted connections across nodes often computed over sparse datasets with missing records. In this work, we introduce a new class of manifold, named soft manifold, that can solve this situation. In particular, soft manifolds are mathematical structures with spherical symmetry where the tangent spaces to each point are hypocycloids whose shape is defined according to the velocity of information propagation across the data points. Using soft manifolds for graph embedding, we can provide continuous spaces to pursue any task in data analysis over complex datasets. Experimental results on reconstruction tasks on synthetic and real datasets show how the proposed approach enable more accurate and reliable characterization of graphs in continuous spaces with respect to the state-of-the-art.
Riemannian Laplace Approximation with the Fisher Metric
Nov 08, 2023The Laplace's method approximates a target density with a Gaussian distribution at its mode. It is computationally efficient and asymptotically exact for Bayesian inference due to the Bernstein-von Mises theorem, but for complex targets and finite-data posteriors it is often too crude an approximation. A recent generalization of the Laplace Approximation transforms the Gaussian approximation according to a chosen Riemannian geometry providing a richer approximation family, while still retaining computational efficiency. However, as shown here, its properties heavily depend on the chosen metric, indeed the metric adopted in previous work results in approximations that are overly narrow as well as being biased even at the limit of infinite data. We correct this shortcoming by developing the approximation family further, deriving two alternative variants that are exact at the limit of infinite data, extending the theoretical analysis of the method, and demonstrating practical improvements in a range of experiments.