 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Additive Gaussian Processes for Wind Farm Power Prediction
Mar 18, 2026Population-based Structural Health Monitoring (PBSHM) aims to share information between similar machines or structures. This paper takes a population-level perspective, exploring the use of additive Gaussian processes to reveal variations in turbine-specific and farm-level power models over a collected wind farm dataset. The predictions illustrate patterns in wind farm power generation, which follow intuition and should enable more informed control and decision-making.
Inter-turbine Modelling of Wind-Farm Power using Multi-task Learning
Feb 20, 2025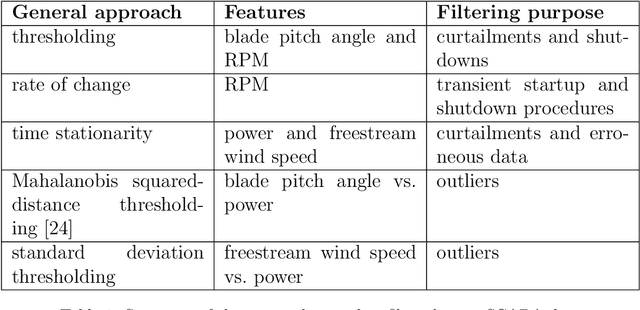
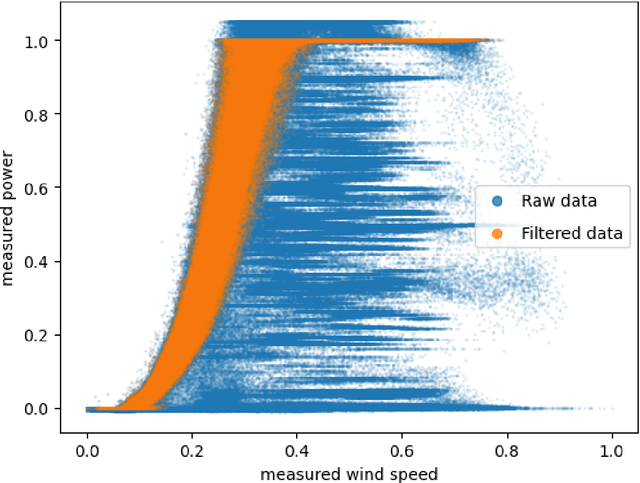
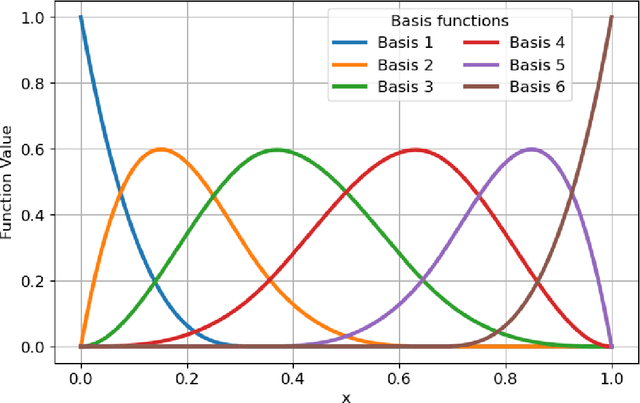
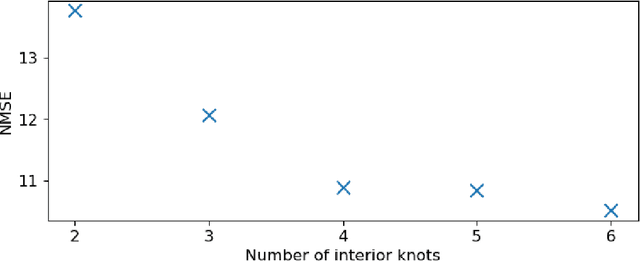
Because of the global need to increase power production from renewable energy resources, developments in the online monitoring of the associated infrastructure is of interest to reduce operation and maintenance costs. However, challenges exist for data-driven approaches to this problem, such as incomplete or limited histories of labelled damage-state data, operational and environmental variability, or the desire for the quantification of uncertainty to support risk management. This work first introduces a probabilistic regression model for predicting wind-turbine power, which adjusts for wake effects learnt from data. Spatial correlations in the learned model parameters for different tasks (turbines) are then leveraged in a hierarchical Bayesian model (an approach to multi-task learning) to develop a "metamodel", which can be used to make power-predictions which adjust for turbine location - including on previously unobserved turbines not included in the training data. The results show that the metamodel is able to outperform a series of benchmark models, and demonstrates a novel strategy for making efficient use of data for inference in populations of structures, in particular where correlations exist in the variable(s) of interest (such as those from wind-turbine wake-effects).
When does a bridge become an aeroplane?
Nov 27, 2024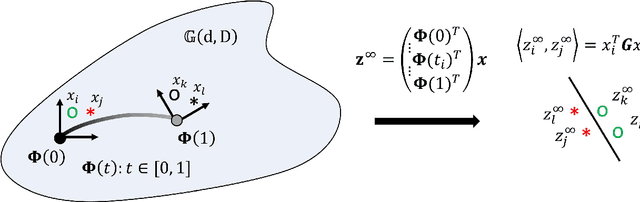
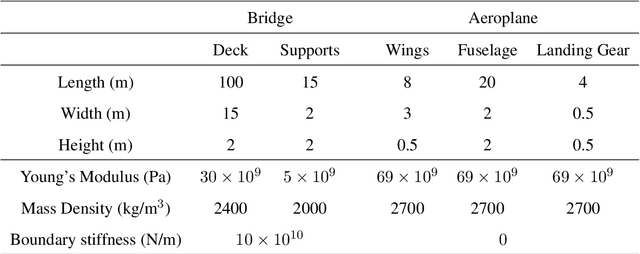
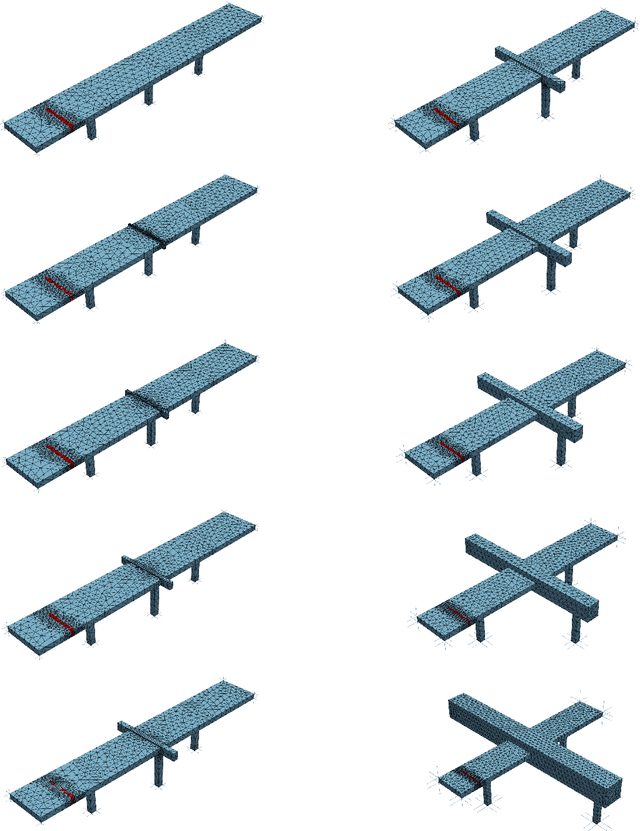

Despite recent advances in population-based structural health monitoring (PBSHM), knowledge transfer between highly-disparate structures (i.e., heterogeneous populations) remains a challenge. It has been proposed that heterogeneous transfer may be accomplished via intermediate structures that bridge the gap in information between the structures of interest. A key aspect of the technique is the idea that by varying parameters such as material properties and geometry, one structure can be continuously morphed into another. The current work demonstrates the development of these interpolating structures, via case studies involving the parameterisation of (and transfer between) a simple, simulated 'bridge' and 'aeroplane'. The facetious question 'When is a bridge not an aeroplane?' has been previously asked in the context of predicting positive transfer based on structural similarity. While the obvious answer to this question is 'Always,' the current work demonstrates that in some cases positive transfer can be achieved between highly-disparate systems.
Active learning for regression in engineering populations: A risk-informed approach
Sep 06, 2024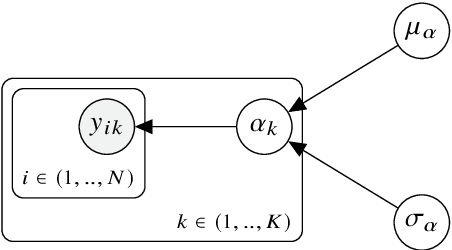



Regression is a fundamental prediction task common in data-centric engineering applications that involves learning mappings between continuous variables. In many engineering applications (e.g.\ structural health monitoring), feature-label pairs used to learn such mappings are of limited availability which hinders the effectiveness of traditional supervised machine learning approaches. The current paper proposes a methodology for overcoming the issue of data scarcity by combining active learning with hierarchical Bayesian modelling. Active learning is an approach for preferentially acquiring feature-label pairs in a resource-efficient manner. In particular, the current work adopts a risk-informed approach that leverages contextual information associated with regression-based engineering decision-making tasks (e.g.\ inspection and maintenance). Hierarchical Bayesian modelling allow multiple related regression tasks to be learned over a population, capturing local and global effects. The information sharing facilitated by this modelling approach means that information acquired for one engineering system can improve predictive performance across the population. The proposed methodology is demonstrated using an experimental case study. Specifically, multiple regressions are performed over a population of machining tools, where the quantity of interest is the surface roughness of the workpieces. An inspection and maintenance decision process is defined using these regression tasks which is in turn used to construct the active-learning algorithm. The novel methodology proposed is benchmarked against an uninformed approach to label acquisition and independent modelling of the regression tasks. It is shown that the proposed approach has superior performance in terms of expected cost -- maintaining predictive performance while reducing the number of inspections required.
Multitask learning for improved scour detection: A dynamic wave tank study
Aug 29, 2024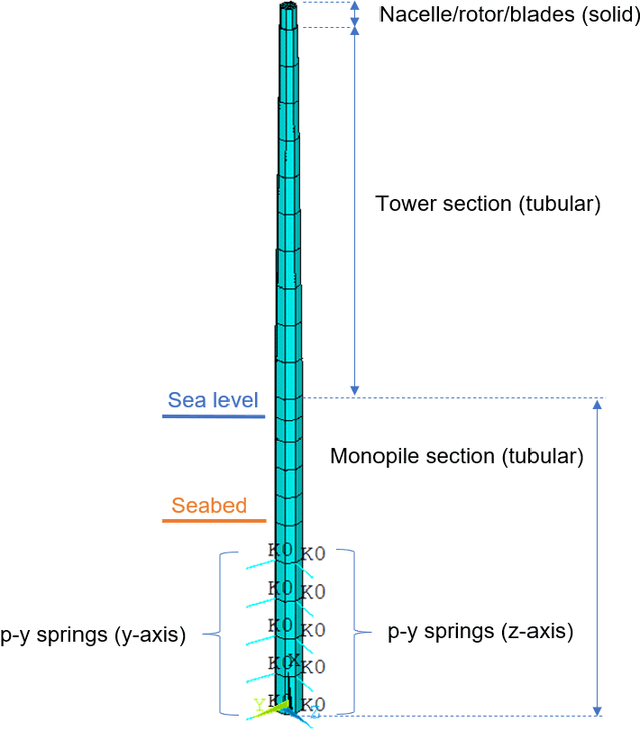


Population-based structural health monitoring (PBSHM), aims to share information between members of a population. An offshore wind (OW) farm could be considered as a population of nominally-identical wind-turbine structures. However, benign variations exist among members, such as geometry, sea-bed conditions and temperature differences. These factors could influence structural properties and therefore the dynamic response, making it more difficult to detect structural problems via traditional SHM techniques. This paper explores the use of a Bayesian hierarchical model as a means of multitask learning, to infer foundation stiffness distribution parameters at both population and local levels. To do this, observations of natural frequency from populations of structures were first generated from both numerical and experimental models. These observations were then used in a partially-pooled Bayesian hierarchical model in tandem with surrogate FE models of the structures to infer foundation stiffness parameters. Finally, it is demonstrated how the learned parameters may be used as a basis to perform more robust anomaly detection (as compared to a no-pooling approach) e.g. as a result of scour.
Towards Multilevel Modelling of Train Passing Events on the Staffordshire Bridge
Mar 26, 2024



We suggest a multilevel model, to represent aggregate train-passing events from the Staffordshire bridge monitoring system. We formulate a combined model from simple units, representing strain envelopes (of each train passing) for two types of commuter train. The measurements are treated as a longitudinal dataset and represented with a (low-rank approximation) hierarchical Gaussian process. For each unit in the combined model, we encode domain expertise as boundary condition constraints and work towards a general representation of the strain response. Looking forward, this should allow for the simulation of train types that were previously unobserved in the training data. For example, trains with more passengers or freights with a heavier payload. The strain event simulations are valuable since they can inform further experiments (including FEM calibration, fatigue analysis, or design) to test the bridge in hypothesised scenarios.
Sharing Information Between Machine Tools to Improve Surface Finish Forecasting
Oct 09, 2023



At present, most surface-quality prediction methods can only perform single-task prediction which results in under-utilised datasets, repetitive work and increased experimental costs. To counter this, the authors propose a Bayesian hierarchical model to predict surface-roughness measurements for a turning machining process. The hierarchical model is compared to multiple independent Bayesian linear regression models to showcase the benefits of partial pooling in a machining setting with respect to prediction accuracy and uncertainty quantification.
Encoding Domain Expertise into Multilevel Models for Source Location
May 15, 2023Data from populations of systems are prevalent in many industrial applications. Machines and infrastructure are increasingly instrumented with sensing systems, emitting streams of telemetry data with complex interdependencies. In practice, data-centric monitoring procedures tend to consider these assets (and respective models) as distinct -- operating in isolation and associated with independent data. In contrast, this work captures the statistical correlations and interdependencies between models of a group of systems. Utilising a Bayesian multilevel approach, the value of data can be extended, since the population can be considered as a whole, rather than constituent parts. Most interestingly, domain expertise and knowledge of the underlying physics can be encoded in the model at the system, subgroup, or population level. We present an example of acoustic emission (time-of-arrival) mapping for source location, to illustrate how multilevel models naturally lend themselves to representing aggregate systems in engineering. In particular, we focus on constraining the combined models with domain knowledge to enhance transfer learning and enable further insights at the population level.
Mitigating sampling bias in risk-based active learning via an EM algorithm
Jun 25, 2022

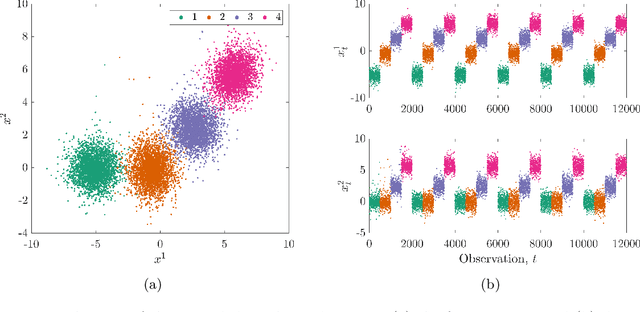
Risk-based active learning is an approach to developing statistical classifiers for online decision-support. In this approach, data-label querying is guided according to the expected value of perfect information for incipient data points. For SHM applications, the value of information is evaluated with respect to a maintenance decision process, and the data-label querying corresponds to the inspection of a structure to determine its health state. Sampling bias is a known issue within active-learning paradigms; this occurs when an active learning process over- or undersamples specific regions of a feature-space, thereby resulting in a training set that is not representative of the underlying distribution. This bias ultimately degrades decision-making performance, and as a consequence, results in unnecessary costs incurred. The current paper outlines a risk-based approach to active learning that utilises a semi-supervised Gaussian mixture model. The semi-supervised approach counteracts sampling bias by incorporating pseudo-labels for unlabelled data via an EM algorithm. The approach is demonstrated on a numerical example representative of the decision processes found in SHM.
A generalised form for a homogeneous population of structures using an overlapping mixture of Gaussian processes
Jun 23, 2022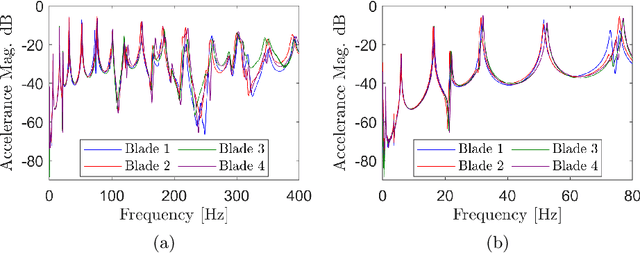

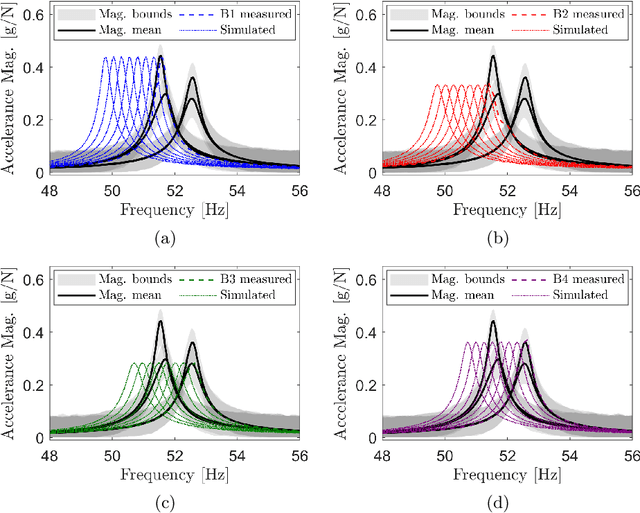
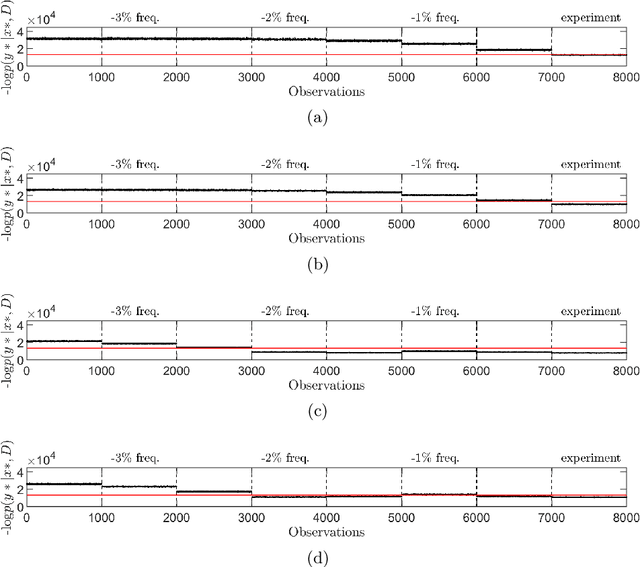
Reductions in natural frequency are often used as a damage indicator for structural health monitoring (SHM) purposes. However, fluctuations in operational and environmental conditions, changes in boundary conditions, and slight differences among nominally-identical structures can also affect stiffness, producing frequency changes that mimic or mask damage. This variability has limited the practical implementation and generalisation of SHM technologies. The aim of this work is to investigate the effects of normal variation, and to identify methods that account for the resulting uncertainty. This work considers vibration data collected from a set of four healthy full-scale composite helicopter blades. The blades were nominally-identical but distinct, and slight differences in material properties and geometry among the blades caused significant variability in the frequency response functions, which presented as four separate trajectories across the input space. In this paper, an overlapping mixture of Gaussian processes (OMGP), was used to generate labels and quantify the uncertainty of normal-condition frequency response data from the helicopter blades. Using a population-based approach, the OMGP model provided a generic representation, called a form, to characterise the normal condition of the blades. Additional simulated data were then compared against the form and evaluated for damage using a marginal-likelihood novelty index.