 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Path Samplers via Sequential Monte Carlo
Jan 29, 2026We develop a diffusion-based sampler for target distributions known up to a normalising constant. To this end, we rely on the well-known diffusion path that smoothly interpolates between a (simple) base distribution and the target distribution, widely used in diffusion models. Our approach is based on a practical implementation of diffusion-annealed Langevin Monte Carlo, which approximates the diffusion path with convergence guarantees. We tackle the score estimation problem by developing an efficient sequential Monte Carlo sampler that evolves auxiliary variables from conditional distributions along the path, which provides principled score estimates for time-varying distributions. We further develop novel control variate schedules that minimise the variance of these score estimates. Finally, we provide theoretical guarantees and empirically demonstrate the effectiveness of our method on several synthetic and real-world datasets.
How to Train Private Clinical Language Models: A Comparative Study of Privacy-Preserving Pipelines for ICD-9 Coding
Nov 18, 2025Large language models trained on clinical text risk exposing sensitive patient information, yet differential privacy (DP) methods often severely degrade the diagnostic accuracy needed for deployment. Despite rapid progress in DP optimisation and text generation, it remains unclear which privacy-preserving strategy actually works best for clinical language tasks. We present the first systematic head-to-head comparison of four training pipelines for automated diagnostic coding from hospital discharge summaries. All pipelines use identical 1B-parameter models and matched privacy budgets to predict ICD-9 codes. At moderate and relaxed privacy budgets ($\varepsilon \in \{4, 6\}$), knowledge distillation from DP-trained teachers outperforms both direct DP-SGD and DP-synthetic data training, recovering up to 63\% of the non-private performance whilst maintaining strong empirical privacy (membership-inference AUC $\approx$ 0.5). These findings expose large differences in the privacy-utility trade-off across architectures and identify knowledge distillation as the most practical route to privacy-preserving clinical NLP.
Uniform-in-time convergence bounds for Persistent Contrastive Divergence Algorithms
Oct 02, 2025We propose a continuous-time formulation of persistent contrastive divergence (PCD) for maximum likelihood estimation (MLE) of unnormalised densities. Our approach expresses PCD as a coupled, multiscale system of stochastic differential equations (SDEs), which perform optimisation of the parameter and sampling of the associated parametrised density, simultaneously. From this novel formulation, we are able to derive explicit bounds for the error between the PCD iterates and the MLE solution for the model parameter. This is made possible by deriving uniform-in-time (UiT) bounds for the difference in moments between the multiscale system and the averaged regime. An efficient implementation of the continuous-time scheme is introduced, leveraging a class of explicit, stable intregators, stochastic orthogonal Runge-Kutta Chebyshev (S-ROCK), for which we provide explicit error estimates in the long-time regime. This leads to a novel method for training energy-based models (EBMs) with explicit error guarantees.
Robust and Conjugate Spatio-Temporal Gaussian Processes
Feb 04, 2025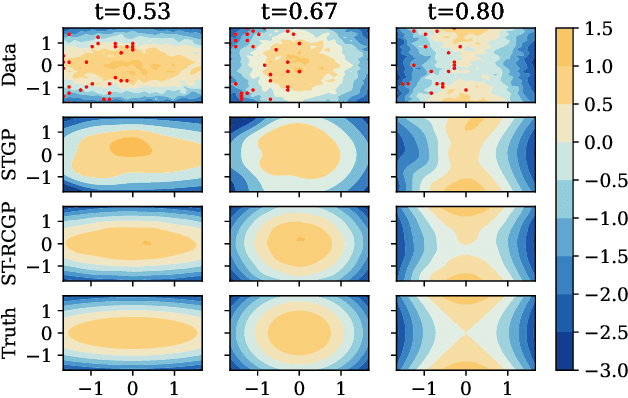
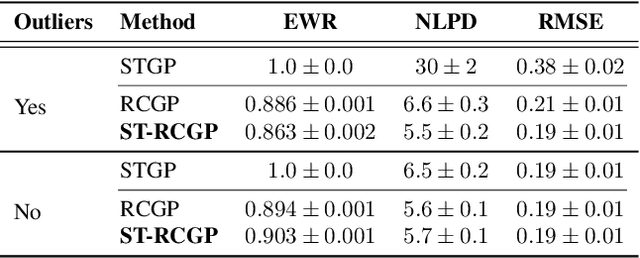
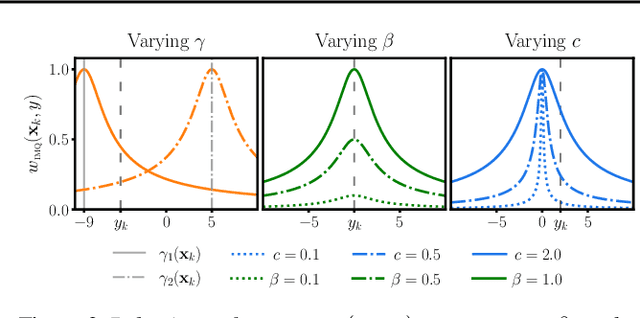
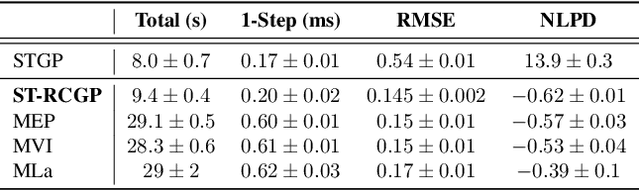
State-space formulations allow for Gaussian process (GP) regression with linear-in-time computational cost in spatio-temporal settings, but performance typically suffers in the presence of outliers. In this paper, we adapt and specialise the robust and conjugate GP (RCGP) framework of Altamirano et al. (2024) to the spatio-temporal setting. In doing so, we obtain an outlier-robust spatio-temporal GP with a computational cost comparable to classical spatio-temporal GPs. We also overcome the three main drawbacks of RCGPs: their unreliable performance when the prior mean is chosen poorly, their lack of reliable uncertainty quantification, and the need to carefully select a hyperparameter by hand. We study our method extensively in finance and weather forecasting applications, demonstrating that it provides a reliable approach to spatio-temporal modelling in the presence of outliers.
Expanding on the BRIAR Dataset: A Comprehensive Whole Body Biometric Recognition Resource at Extreme Distances and Real-World Scenarios (Collections 1-4)
Jan 23, 2025
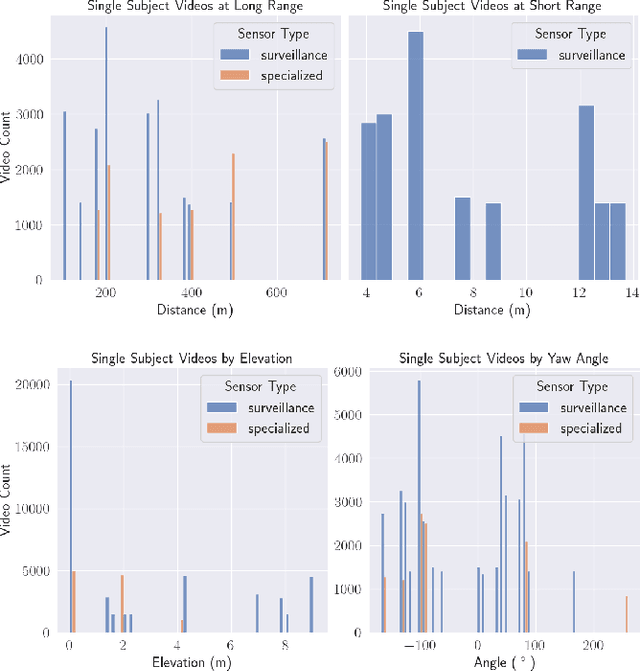
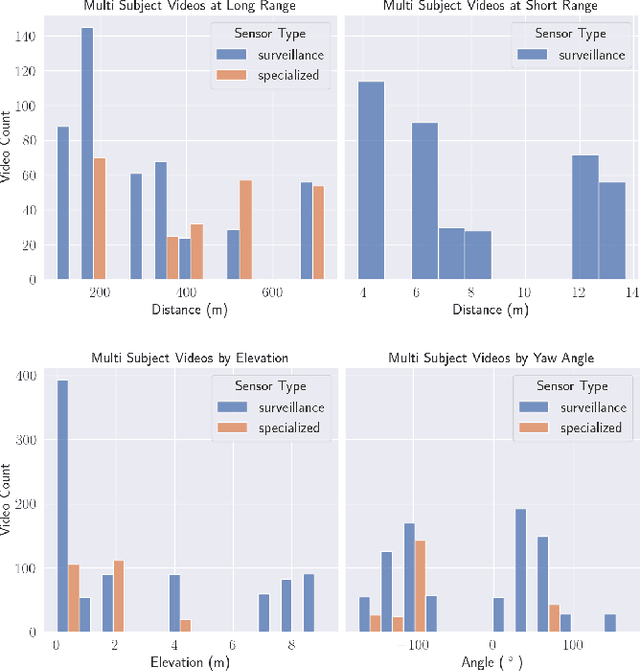

The state-of-the-art in biometric recognition algorithms and operational systems has advanced quickly in recent years providing high accuracy and robustness in more challenging collection environments and consumer applications. However, the technology still suffers greatly when applied to non-conventional settings such as those seen when performing identification at extreme distances or from elevated cameras on buildings or mounted to UAVs. This paper summarizes an extension to the largest dataset currently focused on addressing these operational challenges, and describes its composition as well as methodologies of collection, curation, and annotation.
Deep Optimal Sensor Placement for Black Box Stochastic Simulations
Oct 15, 2024Selecting cost-effective optimal sensor configurations for subsequent inference of parameters in black-box stochastic systems faces significant computational barriers. We propose a novel and robust approach, modelling the joint distribution over input parameters and solution with a joint energy-based model, trained on simulation data. Unlike existing simulation-based inference approaches, which must be tied to a specific set of point evaluations, we learn a functional representation of parameters and solution. This is used as a resolution-independent plug-and-play surrogate for the joint distribution, which can be conditioned over any set of points, permitting an efficient approach to sensor placement. We demonstrate the validity of our framework on a variety of stochastic problems, showing that our method provides highly informative sensor locations at a lower computational cost compared to conventional approaches.
Modelling Global Trade with Optimal Transport
Sep 10, 2024Global trade is shaped by a complex mix of factors beyond supply and demand, including tangible variables like transport costs and tariffs, as well as less quantifiable influences such as political and economic relations. Traditionally, economists model trade using gravity models, which rely on explicit covariates but often struggle to capture these subtler drivers of trade. In this work, we employ optimal transport and a deep neural network to learn a time-dependent cost function from data, without imposing a specific functional form. This approach consistently outperforms traditional gravity models in accuracy while providing natural uncertainty quantification. Applying our framework to global food and agricultural trade, we show that the global South suffered disproportionately from the war in Ukraine's impact on wheat markets. We also analyze the effects of free-trade agreements and trade disputes with China, as well as Brexit's impact on British trade with Europe, uncovering hidden patterns that trade volumes alone cannot reveal.
Towards Multilevel Modelling of Train Passing Events on the Staffordshire Bridge
Mar 26, 2024



We suggest a multilevel model, to represent aggregate train-passing events from the Staffordshire bridge monitoring system. We formulate a combined model from simple units, representing strain envelopes (of each train passing) for two types of commuter train. The measurements are treated as a longitudinal dataset and represented with a (low-rank approximation) hierarchical Gaussian process. For each unit in the combined model, we encode domain expertise as boundary condition constraints and work towards a general representation of the strain response. Looking forward, this should allow for the simulation of train types that were previously unobserved in the training data. For example, trains with more passengers or freights with a heavier payload. The strain event simulations are valuable since they can inform further experiments (including FEM calibration, fatigue analysis, or design) to test the bridge in hypothesised scenarios.
Encoding Domain Expertise into Multilevel Models for Source Location
May 15, 2023Data from populations of systems are prevalent in many industrial applications. Machines and infrastructure are increasingly instrumented with sensing systems, emitting streams of telemetry data with complex interdependencies. In practice, data-centric monitoring procedures tend to consider these assets (and respective models) as distinct -- operating in isolation and associated with independent data. In contrast, this work captures the statistical correlations and interdependencies between models of a group of systems. Utilising a Bayesian multilevel approach, the value of data can be extended, since the population can be considered as a whole, rather than constituent parts. Most interestingly, domain expertise and knowledge of the underlying physics can be encoded in the model at the system, subgroup, or population level. We present an example of acoustic emission (time-of-arrival) mapping for source location, to illustrate how multilevel models naturally lend themselves to representing aggregate systems in engineering. In particular, we focus on constraining the combined models with domain knowledge to enhance transfer learning and enable further insights at the population level.
Expanding Accurate Person Recognition to New Altitudes and Ranges: The BRIAR Dataset
Nov 03, 2022



Face recognition technology has advanced significantly in recent years due largely to the availability of large and increasingly complex training datasets for use in deep learning models. These datasets, however, typically comprise images scraped from news sites or social media platforms and, therefore, have limited utility in more advanced security, forensics, and military applications. These applications require lower resolution, longer ranges, and elevated viewpoints. To meet these critical needs, we collected and curated the first and second subsets of a large multi-modal biometric dataset designed for use in the research and development (R&D) of biometric recognition technologies under extremely challenging conditions. Thus far, the dataset includes more than 350,000 still images and over 1,300 hours of video footage of approximately 1,000 subjects. To collect this data, we used Nikon DSLR cameras, a variety of commercial surveillance cameras, specialized long-rage R&D cameras, and Group 1 and Group 2 UAV platforms. The goal is to support the development of algorithms capable of accurately recognizing people at ranges up to 1,000 m and from high angles of elevation. These advances will include improvements to the state of the art in face recognition and will support new research in the area of whole-body recognition using methods based on gait and anthropometry. This paper describes methods used to collect and curate the dataset, and the dataset's characteristics at the current stage.