 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildCat: Near-Linear Attention in Theory and Practice
Feb 10, 2026We introduce WildCat, a high-accuracy, low-cost approach to compressing the attention mechanism in neural networks. While attention is a staple of modern network architectures, it is also notoriously expensive to deploy due to resource requirements that scale quadratically with the input sequence length $n$. WildCat avoids these quadratic costs by only attending over a small weighted coreset. Crucially, we select the coreset using a fast but spectrally-accurate subsampling algorithm -- randomly pivoted Cholesky -- and weight the elements optimally to minimise reconstruction error. Remarkably, given bounded inputs, WildCat approximates exact attention with super-polynomial $O(n^{-\sqrt{\log(\log(n))}})$ error decay while running in near-linear $O(n^{1+o(1)})$ time. In contrast, prior practical approximations either lack error guarantees or require quadratic runtime to guarantee such high fidelity. We couple this advance with a GPU-optimized PyTorch implementation and a suite of benchmark experiments demonstrating the benefits of WildCat for image generation, image classification, and language model KV cache compression.
Energy-Based Modelling for Discrete and Mixed Data via Heat Equations on Structured Spaces
Dec 02, 2024



Energy-based models (EBMs) offer a flexible framework for probabilistic modelling across various data domains. However, training EBMs on data in discrete or mixed state spaces poses significant challenges due to the lack of robust and fast sampling methods. In this work, we propose to train discrete EBMs with Energy Discrepancy, a loss function which only requires the evaluation of the energy function at data points and their perturbed counterparts, thus eliminating the need for Markov chain Monte Carlo. We introduce perturbations of the data distribution by simulating a diffusion process on the discrete state space endowed with a graph structure. This allows us to inform the choice of perturbation from the structure of the modelled discrete variable, while the continuous time parameter enables fine-grained control of the perturbation. Empirically, we demonstrate the efficacy of the proposed approaches in a wide range of applications, including the estimation of discrete densities with non-binary vocabulary and binary image modelling. Finally, we train EBMs on tabular data sets with applications in synthetic data generation and calibrated classification.
Deep Optimal Sensor Placement for Black Box Stochastic Simulations
Oct 15, 2024Selecting cost-effective optimal sensor configurations for subsequent inference of parameters in black-box stochastic systems faces significant computational barriers. We propose a novel and robust approach, modelling the joint distribution over input parameters and solution with a joint energy-based model, trained on simulation data. Unlike existing simulation-based inference approaches, which must be tied to a specific set of point evaluations, we learn a functional representation of parameters and solution. This is used as a resolution-independent plug-and-play surrogate for the joint distribution, which can be conditioned over any set of points, permitting an efficient approach to sensor placement. We demonstrate the validity of our framework on a variety of stochastic problems, showing that our method provides highly informative sensor locations at a lower computational cost compared to conventional approaches.
Training Discrete Energy-Based Models with Energy Discrepancy
Jul 14, 2023



Training energy-based models (EBMs) on discrete spaces is challenging because sampling over such spaces can be difficult. We propose to train discrete EBMs with energy discrepancy (ED), a novel type of contrastive loss functional which only requires the evaluation of the energy function at data points and their perturbed counter parts, thus not relying on sampling strategies like Markov chain Monte Carlo (MCMC). Energy discrepancy offers theoretical guarantees for a broad class of perturbation processes of which we investigate three types: perturbations based on Bernoulli noise, based on deterministic transforms, and based on neighbourhood structures. We demonstrate their relative performance on lattice Ising models, binary synthetic data, and discrete image data sets.
Energy Discrepancies: A Score-Independent Loss for Energy-Based Models
Jul 12, 2023



Energy-based models are a simple yet powerful class of probabilistic models, but their widespread adoption has been limited by the computational burden of training them. We propose a novel loss function called Energy Discrepancy (ED) which does not rely on the computation of scores or expensive Markov chain Monte Carlo. We show that ED approaches the explicit score matching and negative log-likelihood loss under different limits, effectively interpolating between both. Consequently, minimum ED estimation overcomes the problem of nearsightedness encountered in score-based estimation methods, while also enjoying theoretical guarantees. Through numerical experiments, we demonstrate that ED learns low-dimensional data distributions faster and more accurately than explicit score matching or contrastive divergence. For high-dimensional image data, we describe how the manifold hypothesis puts limitations on our approach and demonstrate the effectiveness of energy discrepancy by training the energy-based model as a prior of a variational decoder model.
Acoustic Leak Detection in Water Networks
Jan 05, 2021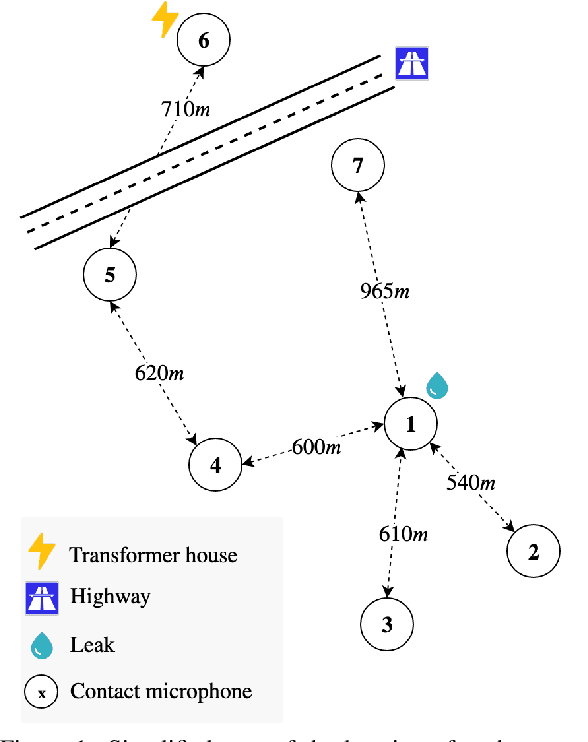
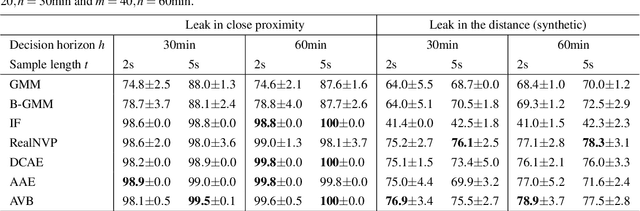
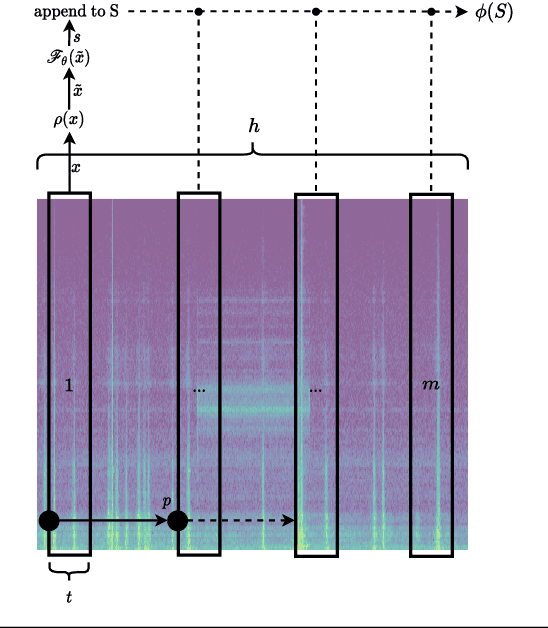
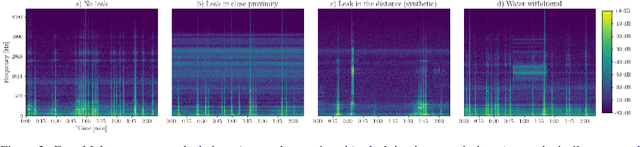
In this work, we present a general procedure for acoustic leak detection in water networks that satisfies multiple real-world constraints such as energy efficiency and ease of deployment. Based on recordings from seven contact microphones attached to the water supply network of a municipal suburb, we trained several shallow and deep anomaly detection models. Inspired by how human experts detect leaks using electronic sounding-sticks, we use these models to repeatedly listen for leaks over a predefined decision horizon. This way we avoid constant monitoring of the system. While we found the detection of leaks in close proximity to be a trivial task for almost all models, neural network based approaches achieve better results at the detection of distant leaks.
Emosaic: Visualizing Affective Content of Text at Varying Granularity
Feb 24, 2020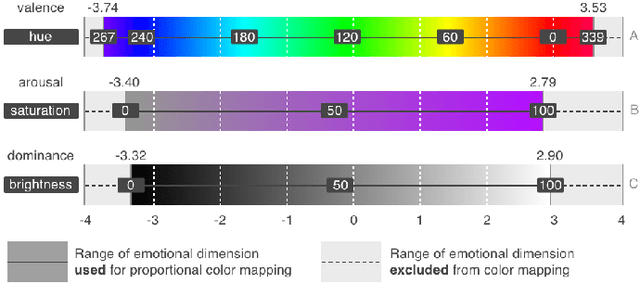

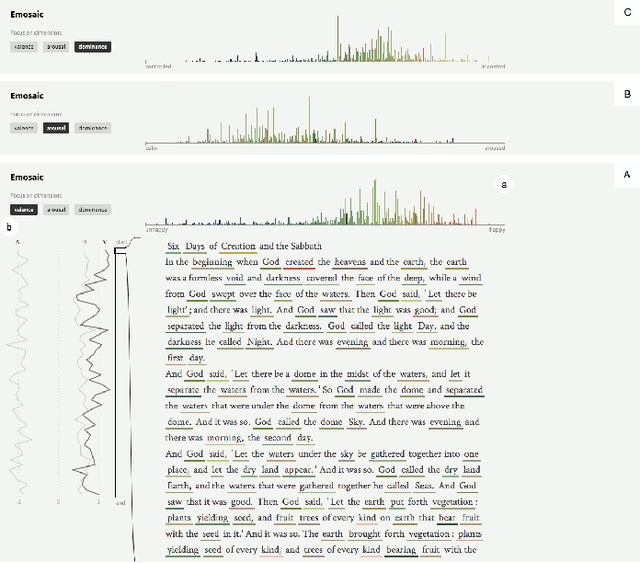
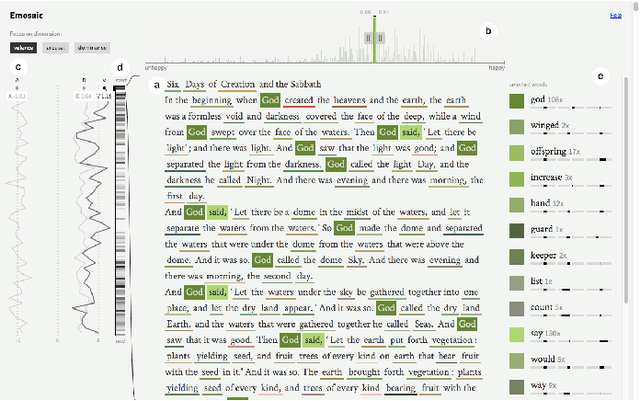
This paper presents Emosaic, a tool for visualizing the emotional tone of text documents, considering multiple dimensions of emotion and varying levels of semantic granularity. Emosaic is grounded in psychological research on the relationship between language, affect, and color perception. We capitalize on an established three-dimensional model of human emotion: valence (good, nice vs. bad, awful), arousal (calm, passive vs. exciting, active) and dominance (weak, controlled vs. strong, in control). Previously, multi-dimensional models of emotion have been used rarely in visualizations of textual data, due to the perceptual challenges involved. Furthermore, until recently most text visualizations remained at a high level, precluding closer engagement with the deep semantic content of the text. Informed by empirical studies, we introduce a color mapping that translates any point in three-dimensional affective space into a unique color. Emosaic uses affective dictionaries of words annotated with the three emotional parameters of the valence-arousal-dominance model to extract emotional meanings from texts and then assigns to them corresponding color parameters of the hue-saturation-brightness color space. This approach of mapping emotion to color is aimed at helping readers to more easily grasp the emotional tone of the text. Several features of Emosaic allow readers to interactively explore the affective content of the text in more detail; e.g., in aggregated form as histograms, in sequential form following the order of text, and in detail embedded into the text display itself. Interaction techniques have been included to allow for filtering and navigating of text and visualizations.