 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAquarium: A Comprehensive Framework for Exploring Predator-Prey Dynamics through Multi-Agent Reinforcement Learning Algorithms
Jan 13, 2024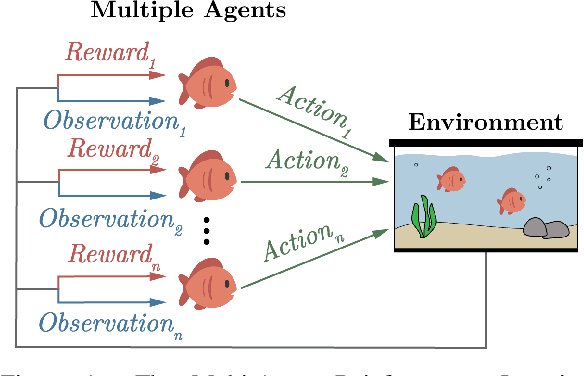

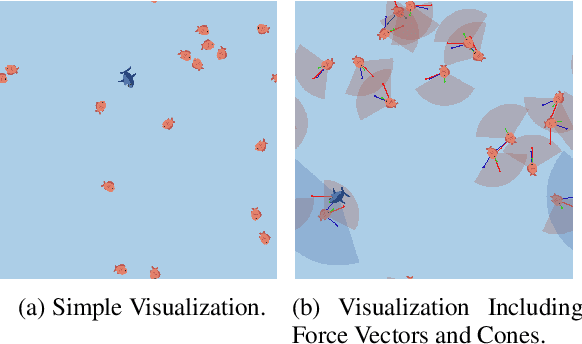
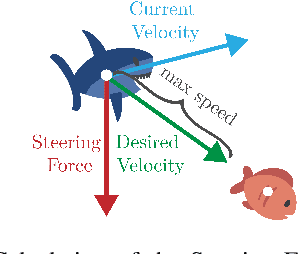
Recent advances in Multi-Agent Reinforcement Learning have prompted the modeling of intricate interactions between agents in simulated environments. In particular, the predator-prey dynamics have captured substantial interest and various simulations been tailored to unique requirements. To prevent further time-intensive developments, we introduce Aquarium, a comprehensive Multi-Agent Reinforcement Learning environment for predator-prey interaction, enabling the study of emergent behavior. Aquarium is open source and offers a seamless integration of the PettingZoo framework, allowing a quick start with proven algorithm implementations. It features physics-based agent movement on a two-dimensional, edge-wrapping plane. The agent-environment interaction (observations, actions, rewards) and the environment settings (agent speed, prey reproduction, predator starvation, and others) are fully customizable. Besides a resource-efficient visualization, Aquarium supports to record video files, providing a visual comprehension of agent behavior. To demonstrate the environment's capabilities, we conduct preliminary studies which use PPO to train multiple prey agents to evade a predator. In accordance to the literature, we find Individual Learning to result in worse performance than Parameter Sharing, which significantly improves coordination and sample-efficiency.
Improving Primate Sounds Classification using Binary Presorting for Deep Learning
Jun 28, 2023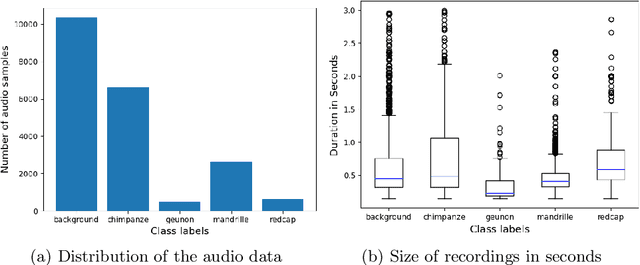
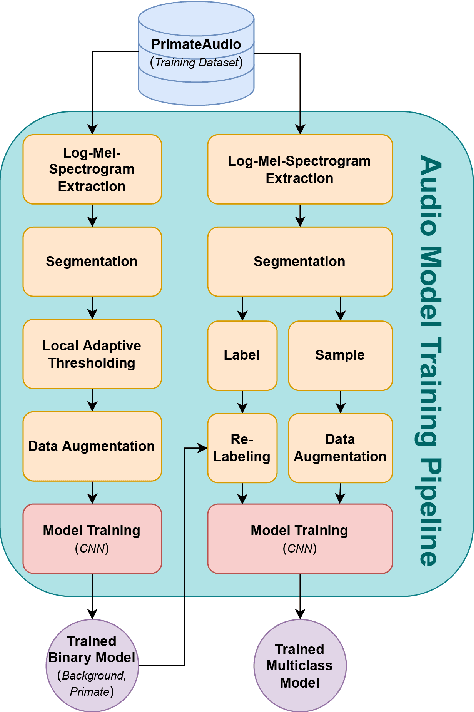
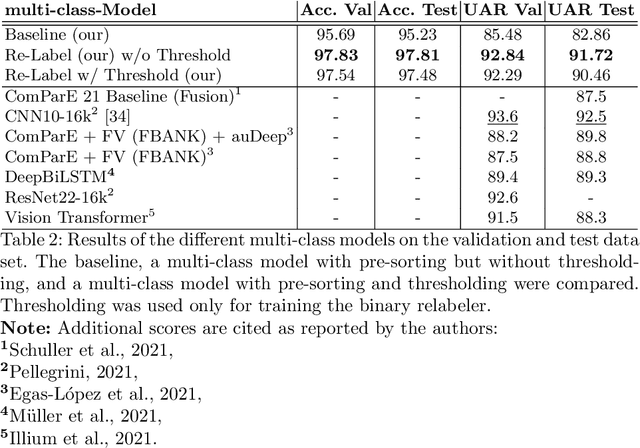
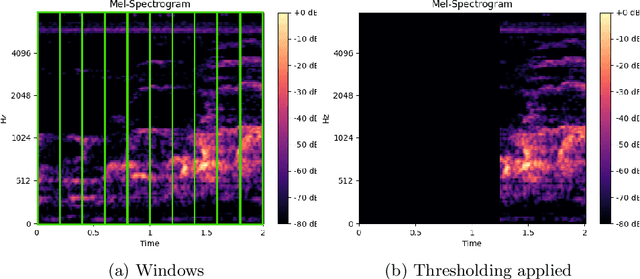
In the field of wildlife observation and conservation, approaches involving machine learning on audio recordings are becoming increasingly popular. Unfortunately, available datasets from this field of research are often not optimal learning material; Samples can be weakly labeled, of different lengths or come with a poor signal-to-noise ratio. In this work, we introduce a generalized approach that first relabels subsegments of MEL spectrogram representations, to achieve higher performances on the actual multi-class classification tasks. For both the binary pre-sorting and the classification, we make use of convolutional neural networks (CNN) and various data-augmentation techniques. We showcase the results of this approach on the challenging \textit{ComparE 2021} dataset, with the task of classifying between different primate species sounds, and report significantly higher Accuracy and UAR scores in contrast to comparatively equipped model baselines.
Compression of GPS Trajectories using Autoencoders
Jan 18, 2023



The ubiquitous availability of mobile devices capable of location tracking led to a significant rise in the collection of GPS data. Several compression methods have been developed in order to reduce the amount of storage needed while keeping the important information. In this paper, we present an lstm-autoencoder based approach in order to compress and reconstruct GPS trajectories, which is evaluated on both a gaming and real-world dataset. We consider various compression ratios and trajectory lengths. The performance is compared to other trajectory compression algorithms, i.e., Douglas-Peucker. Overall, the results indicate that our approach outperforms Douglas-Peucker significantly in terms of the discrete Fr\'echet distance and dynamic time warping. Furthermore, by reconstructing every point lossy, the proposed methodology offers multiple advantages over traditional methods.
VoronoiPatches: Evaluating A New Data Augmentation Method
Dec 23, 2022



Overfitting is a problem in Convolutional Neural Networks (CNN) that causes poor generalization of models on unseen data. To remediate this problem, many new and diverse data augmentation methods (DA) have been proposed to supplement or generate more training data, and thereby increase its quality. In this work, we propose a new data augmentation algorithm: VoronoiPatches (VP). We primarily utilize non-linear recombination of information within an image, fragmenting and occluding small information patches. Unlike other DA methods, VP uses small convex polygon-shaped patches in a random layout to transport information around within an image. Sudden transitions created between patches and the original image can, optionally, be smoothed. In our experiments, VP outperformed current DA methods regarding model variance and overfitting tendencies. We demonstrate data augmentation utilizing non-linear re-combination of information within images, and non-orthogonal shapes and structures improves CNN model robustness on unseen data.
Constructing Organism Networks from Collaborative Self-Replicators
Dec 20, 2022


We introduce organism networks, which function like a single neural network but are composed of several neural particle networks; while each particle network fulfils the role of a single weight application within the organism network, it is also trained to self-replicate its own weights. As organism networks feature vastly more parameters than simpler architectures, we perform our initial experiments on an arithmetic task as well as on simplified MNIST-dataset classification as a collective. We observe that individual particle networks tend to specialise in either of the tasks and that the ones fully specialised in the secondary task may be dropped from the network without hindering the computational accuracy of the primary task. This leads to the discovery of a novel pruning-strategy for sparse neural networks
Empirical Analysis of Limits for Memory Distance in Recurrent Neural Networks
Dec 20, 2022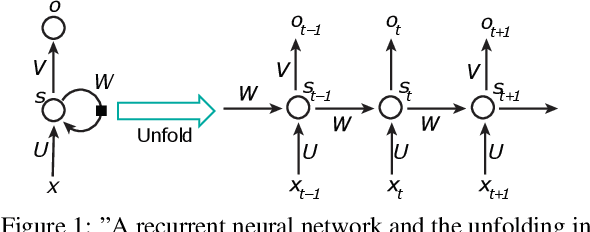
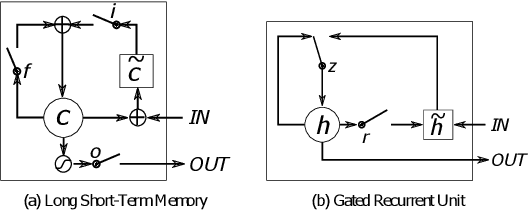
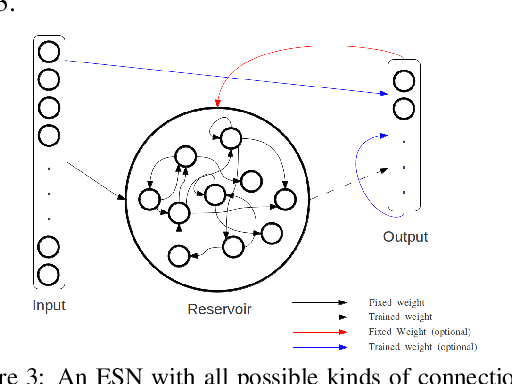
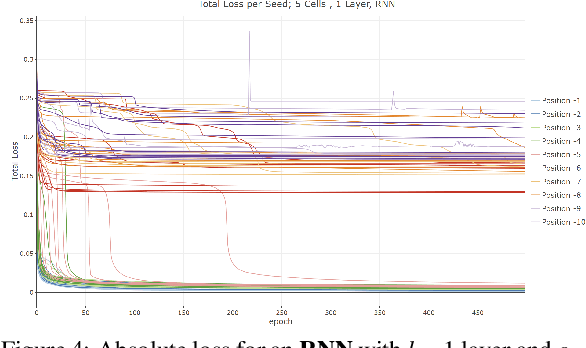
Common to all different kinds of recurrent neural networks (RNNs) is the intention to model relations between data points through time. When there is no immediate relationship between subsequent data points (like when the data points are generated at random, e.g.), we show that RNNs are still able to remember a few data points back into the sequence by memorizing them by heart using standard backpropagation. However, we also show that for classical RNNs, LSTM and GRU networks the distance of data points between recurrent calls that can be reproduced this way is highly limited (compared to even a loose connection between data points) and subject to various constraints imposed by the type and size of the RNN in question. This implies the existence of a hard limit (way below the information-theoretic one) for the distance between related data points within which RNNs are still able to recognize said relation.
Visual Transformers for Primates Classification and Covid Detection
Dec 20, 2022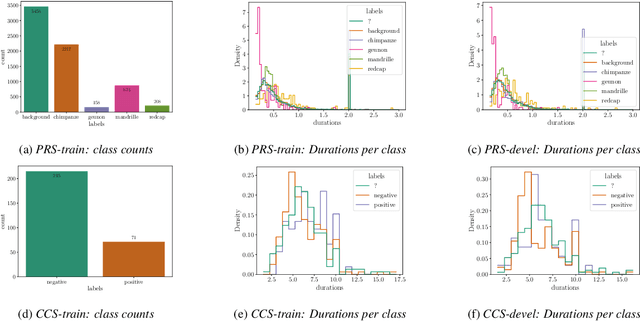
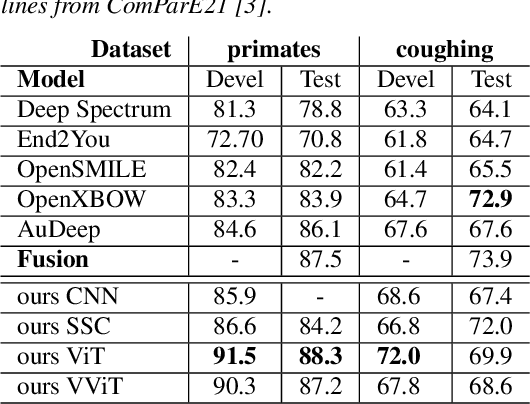
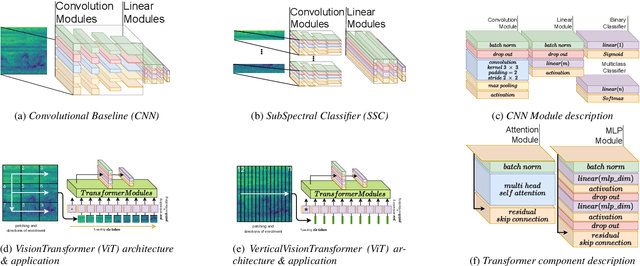
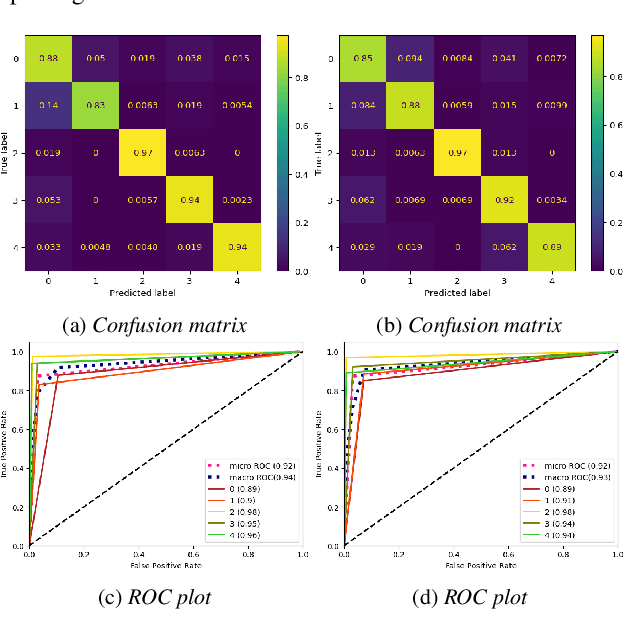
We apply the vision transformer, a deep machine learning model build around the attention mechanism, on mel-spectrogram representations of raw audio recordings. When adding mel-based data augmentation techniques and sample-weighting, we achieve comparable performance on both (PRS and CCS challenge) tasks of ComParE21, outperforming most single model baselines. We further introduce overlapping vertical patching and evaluate the influence of parameter configurations. Index Terms: audio classification, attention, mel-spectrogram, unbalanced data-sets, computational paralinguistics
Case-Based Inverse Reinforcement Learning Using Temporal Coherence
Jun 12, 2022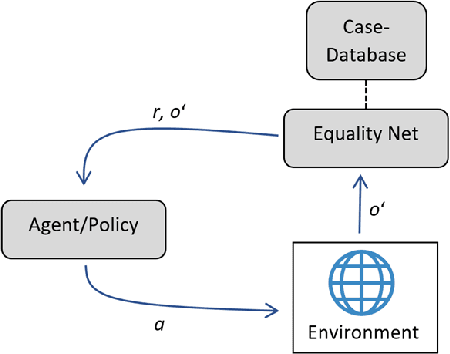
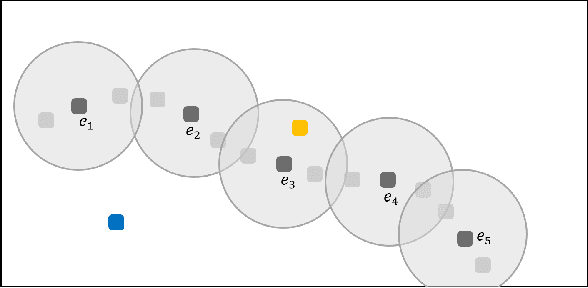
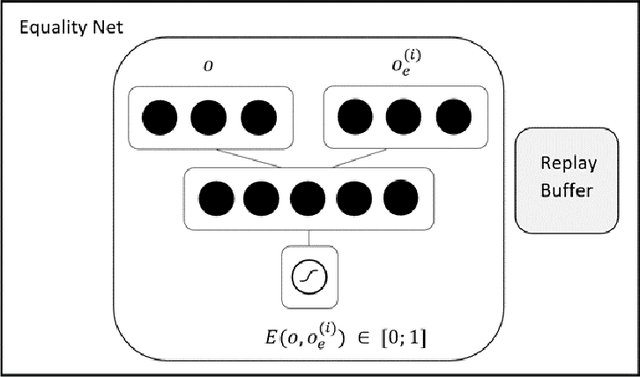
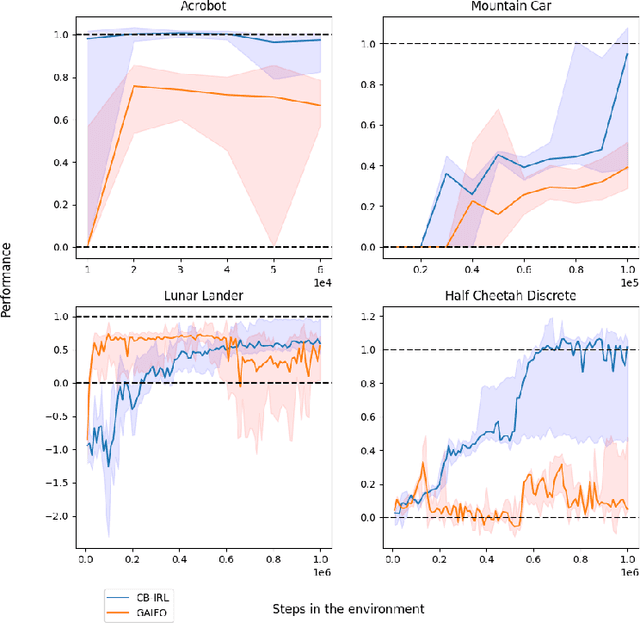
Providing expert trajectories in the context of Imitation Learning is often expensive and time-consuming. The goal must therefore be to create algorithms which require as little expert data as possible. In this paper we present an algorithm that imitates the higher-level strategy of the expert rather than just imitating the expert on action level, which we hypothesize requires less expert data and makes training more stable. As a prior, we assume that the higher-level strategy is to reach an unknown target state area, which we hypothesize is a valid prior for many domains in Reinforcement Learning. The target state area is unknown, but since the expert has demonstrated how to reach it, the agent tries to reach states similar to the expert. Building on the idea of Temporal Coherence, our algorithm trains a neural network to predict whether two states are similar, in the sense that they may occur close in time. During inference, the agent compares its current state with expert states from a Case Base for similarity. The results show that our approach can still learn a near-optimal policy in settings with very little expert data, where algorithms that try to imitate the expert at the action level can no longer do so.
Acoustic Leak Detection in Water Networks
Jan 05, 2021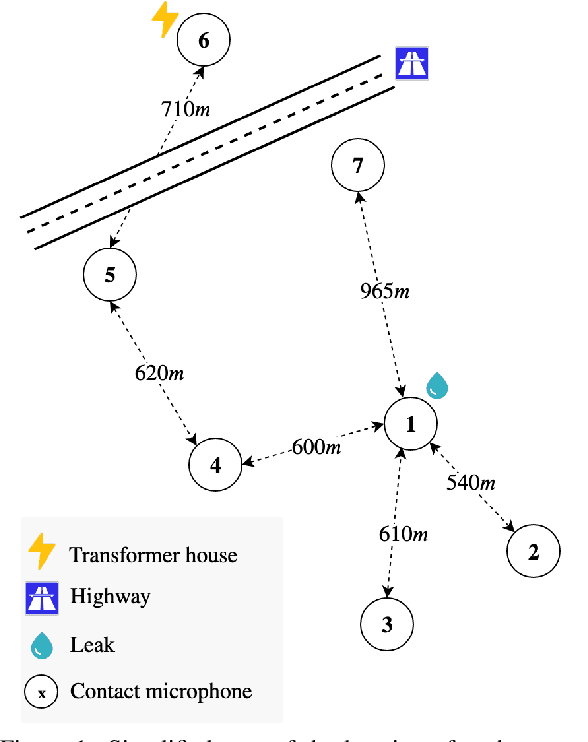
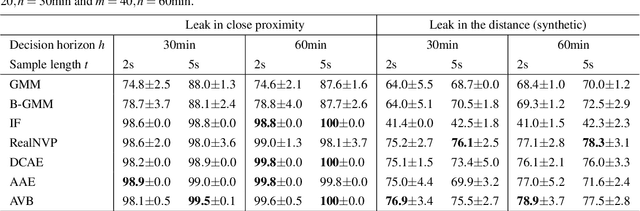
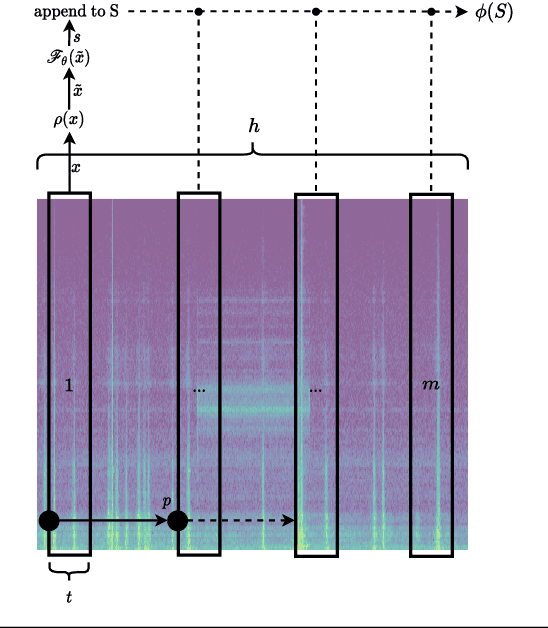
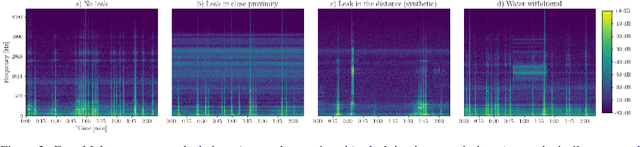
In this work, we present a general procedure for acoustic leak detection in water networks that satisfies multiple real-world constraints such as energy efficiency and ease of deployment. Based on recordings from seven contact microphones attached to the water supply network of a municipal suburb, we trained several shallow and deep anomaly detection models. Inspired by how human experts detect leaks using electronic sounding-sticks, we use these models to repeatedly listen for leaks over a predefined decision horizon. This way we avoid constant monitoring of the system. While we found the detection of leaks in close proximity to be a trivial task for almost all models, neural network based approaches achieve better results at the detection of distant leaks.
Analysis of Feature Representations for Anomalous Sound Detection
Dec 11, 2020
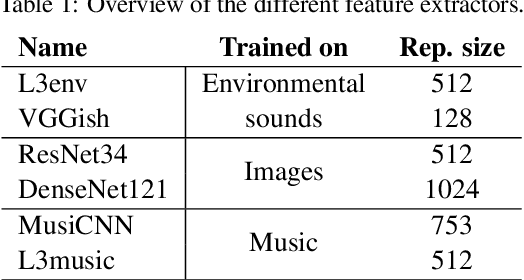
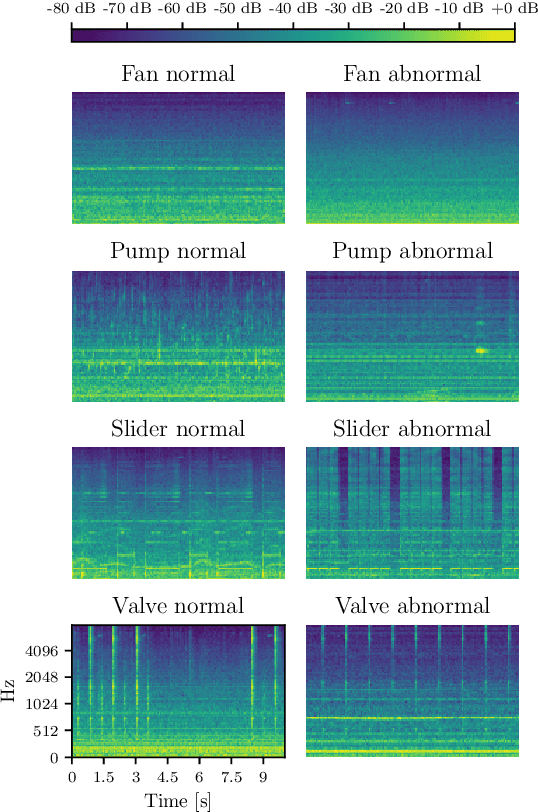
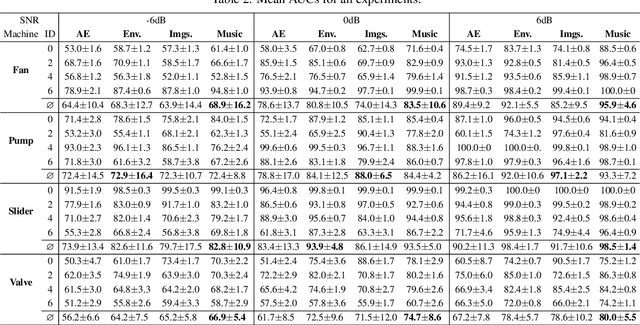
In this work, we thoroughly evaluate the efficacy of pretrained neural networks as feature extractors for anomalous sound detection. In doing so, we leverage the knowledge that is contained in these neural networks to extract semantically rich features (representations) that serve as input to a Gaussian Mixture Model which is used as a density estimator to model normality. We compare feature extractors that were trained on data from various domains, namely: images, environmental sounds and music. Our approach is evaluated on recordings from factory machinery such as valves, pumps, sliders and fans. All of the evaluated representations outperform the autoencoder baseline with music based representations yielding the best performance in most cases. These results challenge the common assumption that closely matching the domain of the feature extractor and the downstream task results in better downstream task performance.