 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Optimization Algorithms
Nov 15, 2025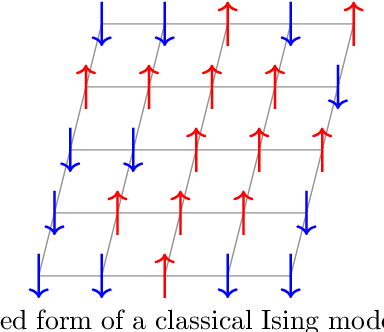
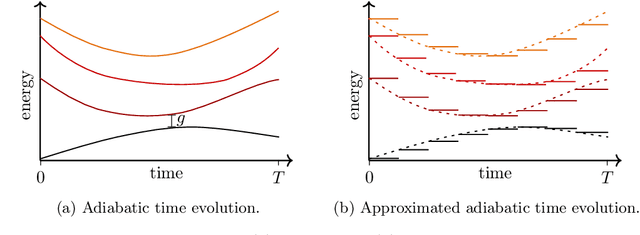
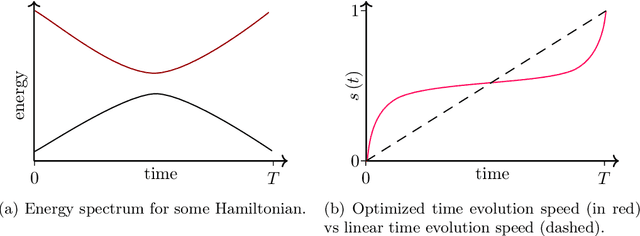
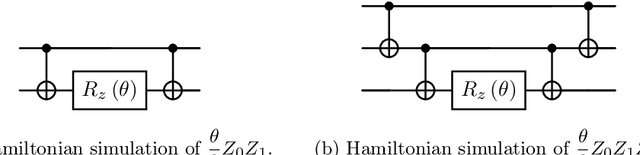
Quantum optimization allows for up to exponential quantum speedups for specific, possibly industrially relevant problems. As the key algorithm in this field, we motivate and discuss the Quantum Approximate Optimization Algorithm (QAOA), which can be understood as a slightly generalized version of Quantum Annealing for gate-based quantum computers. We delve into the quantum circuit implementation of the QAOA, including Hamiltonian simulation techniques for higher-order Ising models, and discuss parameter training using the parameter shift rule. An example implementation with Pennylane source code demonstrates practical application for the Maximum Cut problem. Further, we show how constraints can be incorporated into the QAOA using Grover mixers, allowing to restrict the search space to strictly valid solutions for specific problems. Finally, we outline the Variational Quantum Eigensolver (VQE) as a generalization of the QAOA, highlighting its potential in the NISQ era and addressing challenges such as barren plateaus and ansatz design.
Towards Scalable Lottery Ticket Networks using Genetic Algorithms
Aug 12, 2025Building modern deep learning systems that are not just effective but also efficient requires rethinking established paradigms for model training and neural architecture design. Instead of adapting highly overparameterized networks and subsequently applying model compression techniques to reduce resource consumption, a new class of high-performing networks skips the need for expensive parameter updates, while requiring only a fraction of parameters, making them highly scalable. The Strong Lottery Ticket Hypothesis posits that within randomly initialized, sufficiently overparameterized neural networks, there exist subnetworks that can match the accuracy of the trained original model-without any training. This work explores the usage of genetic algorithms for identifying these strong lottery ticket subnetworks. We find that for instances of binary and multi-class classification tasks, our approach achieves better accuracies and sparsity levels than the current state-of-the-art without requiring any gradient information. In addition, we provide justification for the need for appropriate evaluation metrics when scaling to more complex network architectures and learning tasks.
Surrogate Fitness Metrics for Interpretable Reinforcement Learning
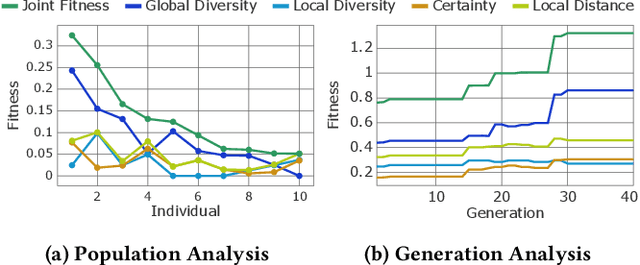
Apr 20, 2025We employ an evolutionary optimization framework that perturbs initial states to generate informative and diverse policy demonstrations. A joint surrogate fitness function guides the optimization by combining local diversity, behavioral certainty, and global population diversity. To assess demonstration quality, we apply a set of evaluation metrics, including the reward-based optimality gap, fidelity interquartile means (IQMs), fitness composition analysis, and trajectory visualizations. Hyperparameter sensitivity is also examined to better understand the dynamics of trajectory optimization. Our findings demonstrate that optimizing trajectory selection via surrogate fitness metrics significantly improves interpretability of RL policies in both discrete and continuous environments. In gridworld domains, evaluations reveal significantly enhanced demonstration fidelities compared to random and ablated baselines. In continuous control, the proposed framework offers valuable insights, particularly for early-stage policies, while fidelity-based optimization proves more effective for mature policies. By refining and systematically analyzing surrogate fitness functions, this study advances the interpretability of RL models. The proposed improvements provide deeper insights into RL decision-making, benefiting applications in safety-critical and explainability-focused domains.
Evaluating Mutation Techniques in Genetic Algorithm-Based Quantum Circuit Synthesis
Apr 08, 2025Quantum computing leverages the unique properties of qubits and quantum parallelism to solve problems intractable for classical systems, offering unparalleled computational potential. However, the optimization of quantum circuits remains critical, especially for noisy intermediate-scale quantum (NISQ) devices with limited qubits and high error rates. Genetic algorithms (GAs) provide a promising approach for efficient quantum circuit synthesis by automating optimization tasks. This work examines the impact of various mutation strategies within a GA framework for quantum circuit synthesis. By analyzing how different mutations transform circuits, it identifies strategies that enhance efficiency and performance. Experiments utilized a fitness function emphasizing fidelity, while accounting for circuit depth and T operations, to optimize circuits with four to six qubits. Comprehensive hyperparameter testing revealed that combining delete and swap strategies outperformed other approaches, demonstrating their effectiveness in developing robust GA-based quantum circuit optimizers.
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
Dec 10, 2024



Reinforcement Learning (RL) policies are designed to predict actions based on current observations to maximize cumulative future rewards. In real-world applications (i.e., non-simulated environments), sensors are essential for measuring the current state and providing the observations on which RL policies rely to make decisions. A significant challenge in deploying RL policies in real-world scenarios is handling sensor dropouts, which can result from hardware malfunctions, physical damage, or environmental factors like dust on a camera lens. A common strategy to mitigate this issue is the use of backup sensors, though this comes with added costs. This paper explores the optimization of backup sensor configurations to maximize expected returns while keeping costs below a specified threshold, C. Our approach uses a second-order approximation of expected returns and includes penalties for exceeding cost constraints. We then optimize this quadratic program using Tabu Search, a meta-heuristic algorithm. The approach is evaluated across eight OpenAI Gym environments and a custom Unity-based robotic environment (RobotArmGrasping). Empirical results demonstrate that our quadratic program effectively approximates real expected returns, facilitating the identification of optimal sensor configurations.
Finding Strong Lottery Ticket Networks with Genetic Algorithms
Nov 07, 2024According to the Strong Lottery Ticket Hypothesis, every sufficiently large neural network with randomly initialized weights contains a sub-network which - still with its random weights - already performs as well for a given task as the trained super-network. We present the first approach based on a genetic algorithm to find such strong lottery ticket sub-networks without training or otherwise computing any gradient. We show that, for smaller instances of binary classification tasks, our evolutionary approach even produces smaller and better-performing lottery ticket networks than the state-of-the-art approach using gradient information.
A Study on Optimization Techniques for Variational Quantum Circuits in Reinforcement Learning
May 20, 2024Quantum Computing aims to streamline machine learning, making it more effective with fewer trainable parameters. This reduction of parameters can speed up the learning process and reduce the use of computational resources. However, in the current phase of quantum computing development, known as the noisy intermediate-scale quantum era (NISQ), learning is difficult due to a limited number of qubits and widespread quantum noise. To overcome these challenges, researchers are focusing on variational quantum circuits (VQCs). VQCs are hybrid algorithms that merge a quantum circuit, which can be adjusted through parameters, with traditional classical optimization techniques. These circuits require only few qubits for effective learning. Recent studies have presented new ways of applying VQCs to reinforcement learning, showing promising results that warrant further exploration. This study investigates the effects of various techniques -- data re-uploading, input scaling, output scaling -- and introduces exponential learning rate decay in the quantum proximal policy optimization algorithm's actor-VQC. We assess these methods in the popular Frozen Lake and Cart Pole environments. Our focus is on their ability to reduce the number of parameters in the VQC without losing effectiveness. Our findings indicate that data re-uploading and an exponential learning rate decay significantly enhance hyperparameter stability and overall performance. While input scaling does not improve parameter efficiency, output scaling effectively manages greediness, leading to increased learning speed and robustness.
Qandle: Accelerating State Vector Simulation Using Gate-Matrix Caching and Circuit Splitting
Apr 14, 2024



To address the computational complexity associated with state-vector simulation for quantum circuits, we propose a combination of advanced techniques to accelerate circuit execution. Quantum gate matrix caching reduces the overhead of repeated applications of the Kronecker product when applying a gate matrix to the state vector by storing decomposed partial matrices for each gate. Circuit splitting divides the circuit into sub-circuits with fewer gates by constructing a dependency graph, enabling parallel or sequential execution on disjoint subsets of the state vector. These techniques are implemented using the PyTorch machine learning framework. We demonstrate the performance of our approach by comparing it to other PyTorch-compatible quantum state-vector simulators. Our implementation, named Qandle, is designed to seamlessly integrate with existing machine learning workflows, providing a user-friendly API and compatibility with the OpenQASM format. Qandle is an open-source project hosted on GitHub https://github.com/gstenzel/qandle and PyPI https://pypi.org/project/qandle/ .
REACT: Revealing Evolutionary Action Consequence Trajectories for Interpretable Reinforcement Learning
Apr 04, 2024
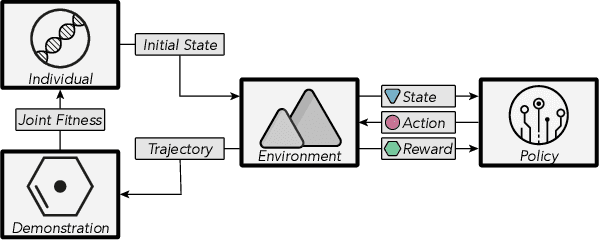

To enhance the interpretability of Reinforcement Learning (RL), we propose Revealing Evolutionary Action Consequence Trajectories (REACT). In contrast to the prevalent practice of validating RL models based on their optimal behavior learned during training, we posit that considering a range of edge-case trajectories provides a more comprehensive understanding of their inherent behavior. To induce such scenarios, we introduce a disturbance to the initial state, optimizing it through an evolutionary algorithm to generate a diverse population of demonstrations. To evaluate the fitness of trajectories, REACT incorporates a joint fitness function that encourages both local and global diversity in the encountered states and chosen actions. Through assessments with policies trained for varying durations in discrete and continuous environments, we demonstrate the descriptive power of REACT. Our results highlight its effectiveness in revealing nuanced aspects of RL models' behavior beyond optimal performance, thereby contributing to improved interpretability.
Challenges for Reinforcement Learning in Quantum Computing
Dec 18, 2023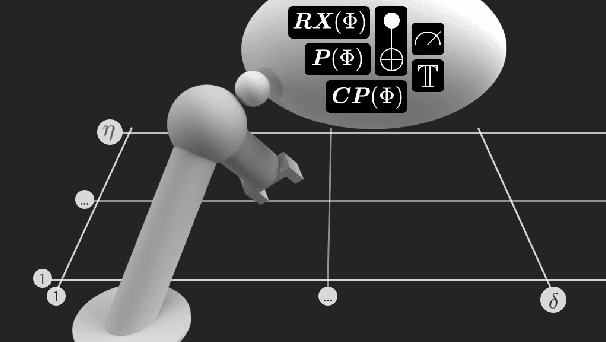
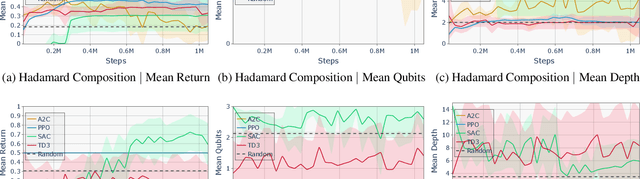
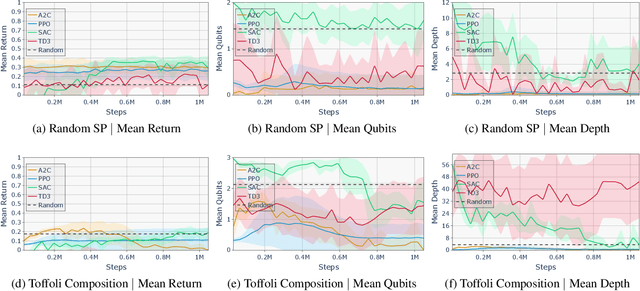
Quantum computing (QC) in the current NISQ-era is still limited. To gain early insights and advantages, hybrid applications are widely considered mitigating those shortcomings. Hybrid quantum machine learning (QML) comprises both the application of QC to improve machine learning (ML), and the application of ML to improve QC architectures. This work considers the latter, focusing on leveraging reinforcement learning (RL) to improve current QC approaches. We therefore introduce various generic challenges arising from quantum architecture search and quantum circuit optimization that RL algorithms need to solve to provide benefits for more complex applications and combinations of those. Building upon these challenges we propose a concrete framework, formalized as a Markov decision process, to enable to learn policies that are capable of controlling a universal set of quantum gates. Furthermore, we provide benchmark results to assess shortcomings and strengths of current state-of-the-art algorithms.