 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Fitness Metrics for Interpretable Reinforcement Learning
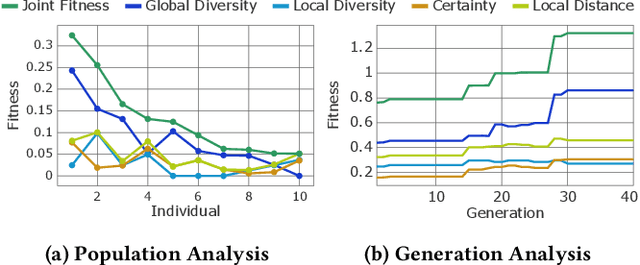
Apr 20, 2025We employ an evolutionary optimization framework that perturbs initial states to generate informative and diverse policy demonstrations. A joint surrogate fitness function guides the optimization by combining local diversity, behavioral certainty, and global population diversity. To assess demonstration quality, we apply a set of evaluation metrics, including the reward-based optimality gap, fidelity interquartile means (IQMs), fitness composition analysis, and trajectory visualizations. Hyperparameter sensitivity is also examined to better understand the dynamics of trajectory optimization. Our findings demonstrate that optimizing trajectory selection via surrogate fitness metrics significantly improves interpretability of RL policies in both discrete and continuous environments. In gridworld domains, evaluations reveal significantly enhanced demonstration fidelities compared to random and ablated baselines. In continuous control, the proposed framework offers valuable insights, particularly for early-stage policies, while fidelity-based optimization proves more effective for mature policies. By refining and systematically analyzing surrogate fitness functions, this study advances the interpretability of RL models. The proposed improvements provide deeper insights into RL decision-making, benefiting applications in safety-critical and explainability-focused domains.
REACT: Revealing Evolutionary Action Consequence Trajectories for Interpretable Reinforcement Learning
Apr 04, 2024
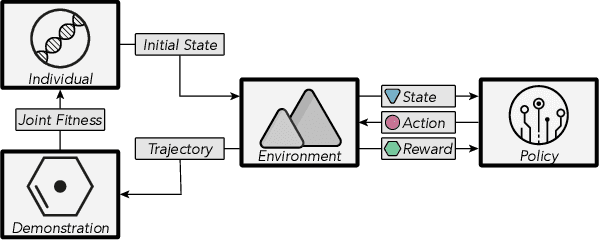

To enhance the interpretability of Reinforcement Learning (RL), we propose Revealing Evolutionary Action Consequence Trajectories (REACT). In contrast to the prevalent practice of validating RL models based on their optimal behavior learned during training, we posit that considering a range of edge-case trajectories provides a more comprehensive understanding of their inherent behavior. To induce such scenarios, we introduce a disturbance to the initial state, optimizing it through an evolutionary algorithm to generate a diverse population of demonstrations. To evaluate the fitness of trajectories, REACT incorporates a joint fitness function that encourages both local and global diversity in the encountered states and chosen actions. Through assessments with policies trained for varying durations in discrete and continuous environments, we demonstrate the descriptive power of REACT. Our results highlight its effectiveness in revealing nuanced aspects of RL models' behavior beyond optimal performance, thereby contributing to improved interpretability.