 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Fitness Metrics for Interpretable Reinforcement Learning
Apr 20, 2025We employ an evolutionary optimization framework that perturbs initial states to generate informative and diverse policy demonstrations. A joint surrogate fitness function guides the optimization by combining local diversity, behavioral certainty, and global population diversity. To assess demonstration quality, we apply a set of evaluation metrics, including the reward-based optimality gap, fidelity interquartile means (IQMs), fitness composition analysis, and trajectory visualizations. Hyperparameter sensitivity is also examined to better understand the dynamics of trajectory optimization. Our findings demonstrate that optimizing trajectory selection via surrogate fitness metrics significantly improves interpretability of RL policies in both discrete and continuous environments. In gridworld domains, evaluations reveal significantly enhanced demonstration fidelities compared to random and ablated baselines. In continuous control, the proposed framework offers valuable insights, particularly for early-stage policies, while fidelity-based optimization proves more effective for mature policies. By refining and systematically analyzing surrogate fitness functions, this study advances the interpretability of RL models. The proposed improvements provide deeper insights into RL decision-making, benefiting applications in safety-critical and explainability-focused domains.
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
Dec 10, 2024



Reinforcement Learning (RL) policies are designed to predict actions based on current observations to maximize cumulative future rewards. In real-world applications (i.e., non-simulated environments), sensors are essential for measuring the current state and providing the observations on which RL policies rely to make decisions. A significant challenge in deploying RL policies in real-world scenarios is handling sensor dropouts, which can result from hardware malfunctions, physical damage, or environmental factors like dust on a camera lens. A common strategy to mitigate this issue is the use of backup sensors, though this comes with added costs. This paper explores the optimization of backup sensor configurations to maximize expected returns while keeping costs below a specified threshold, C. Our approach uses a second-order approximation of expected returns and includes penalties for exceeding cost constraints. We then optimize this quadratic program using Tabu Search, a meta-heuristic algorithm. The approach is evaluated across eight OpenAI Gym environments and a custom Unity-based robotic environment (RobotArmGrasping). Empirical results demonstrate that our quadratic program effectively approximates real expected returns, facilitating the identification of optimal sensor configurations.
REACT: Revealing Evolutionary Action Consequence Trajectories for Interpretable Reinforcement Learning
Apr 04, 2024
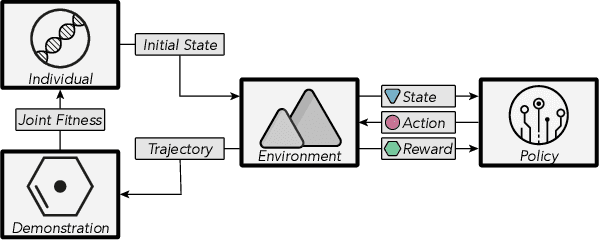

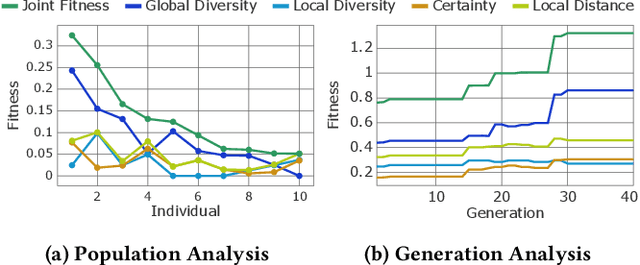
To enhance the interpretability of Reinforcement Learning (RL), we propose Revealing Evolutionary Action Consequence Trajectories (REACT). In contrast to the prevalent practice of validating RL models based on their optimal behavior learned during training, we posit that considering a range of edge-case trajectories provides a more comprehensive understanding of their inherent behavior. To induce such scenarios, we introduce a disturbance to the initial state, optimizing it through an evolutionary algorithm to generate a diverse population of demonstrations. To evaluate the fitness of trajectories, REACT incorporates a joint fitness function that encourages both local and global diversity in the encountered states and chosen actions. Through assessments with policies trained for varying durations in discrete and continuous environments, we demonstrate the descriptive power of REACT. Our results highlight its effectiveness in revealing nuanced aspects of RL models' behavior beyond optimal performance, thereby contributing to improved interpretability.
Aquarium: A Comprehensive Framework for Exploring Predator-Prey Dynamics through Multi-Agent Reinforcement Learning Algorithms
Jan 13, 2024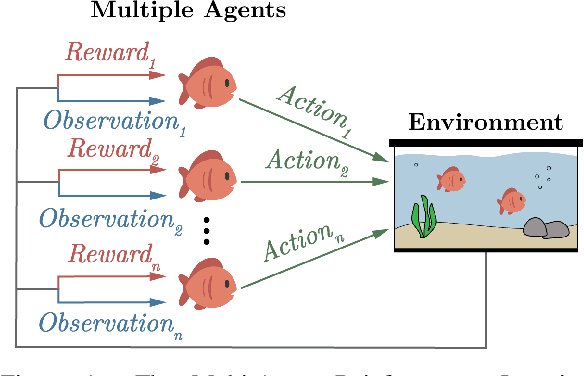

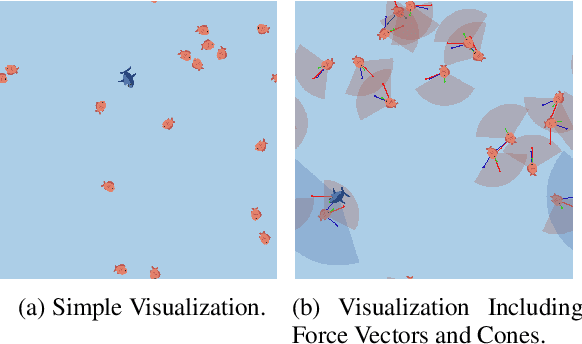
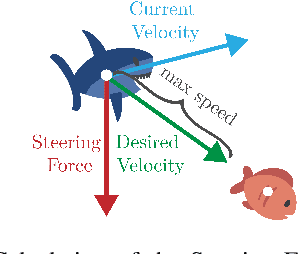
Recent advances in Multi-Agent Reinforcement Learning have prompted the modeling of intricate interactions between agents in simulated environments. In particular, the predator-prey dynamics have captured substantial interest and various simulations been tailored to unique requirements. To prevent further time-intensive developments, we introduce Aquarium, a comprehensive Multi-Agent Reinforcement Learning environment for predator-prey interaction, enabling the study of emergent behavior. Aquarium is open source and offers a seamless integration of the PettingZoo framework, allowing a quick start with proven algorithm implementations. It features physics-based agent movement on a two-dimensional, edge-wrapping plane. The agent-environment interaction (observations, actions, rewards) and the environment settings (agent speed, prey reproduction, predator starvation, and others) are fully customizable. Besides a resource-efficient visualization, Aquarium supports to record video files, providing a visual comprehension of agent behavior. To demonstrate the environment's capabilities, we conduct preliminary studies which use PPO to train multiple prey agents to evade a predator. In accordance to the literature, we find Individual Learning to result in worse performance than Parameter Sharing, which significantly improves coordination and sample-efficiency.
Quantum Advantage Actor-Critic for Reinforcement Learning
Jan 13, 2024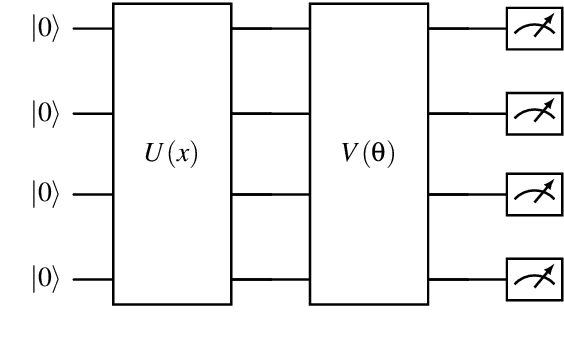
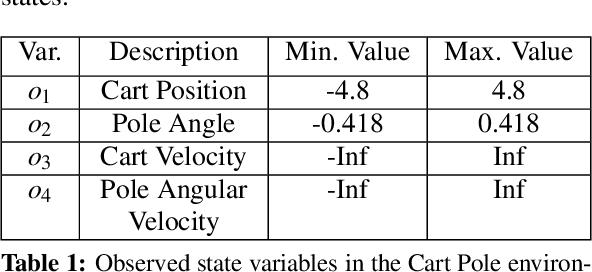
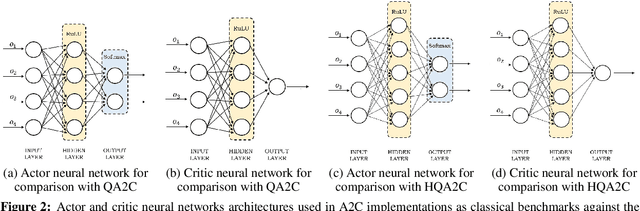
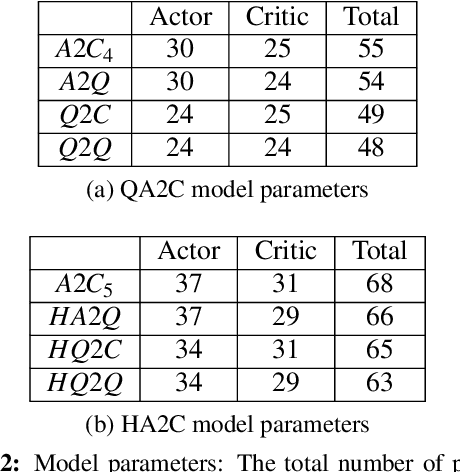
Quantum computing offers efficient encapsulation of high-dimensional states. In this work, we propose a novel quantum reinforcement learning approach that combines the Advantage Actor-Critic algorithm with variational quantum circuits by substituting parts of the classical components. This approach addresses reinforcement learning's scalability concerns while maintaining high performance. We empirically test multiple quantum Advantage Actor-Critic configurations with the well known Cart Pole environment to evaluate our approach in control tasks with continuous state spaces. Our results indicate that the hybrid strategy of using either a quantum actor or quantum critic with classical post-processing yields a substantial performance increase compared to pure classical and pure quantum variants with similar parameter counts. They further reveal the limits of current quantum approaches due to the hardware constraints of noisy intermediate-scale quantum computers, suggesting further research to scale hybrid approaches for larger and more complex control tasks.
CROP: Towards Distributional-Shift Robust Reinforcement Learning using Compact Reshaped Observation Processing
Apr 26, 2023

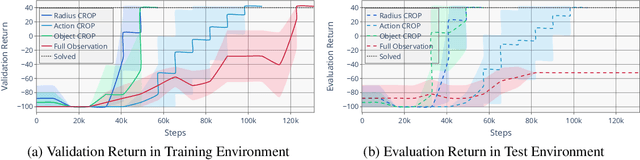
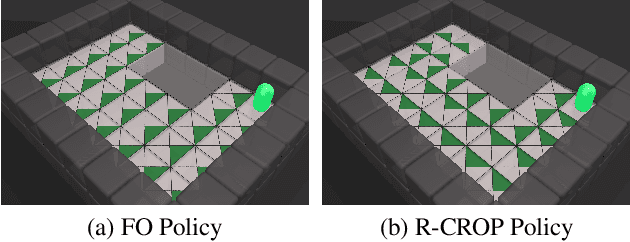
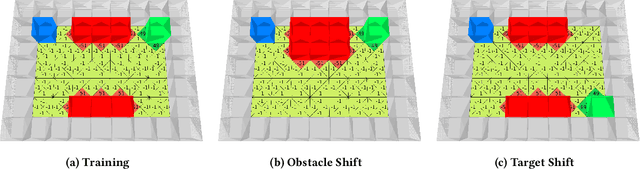
The safe application of reinforcement learning (RL) requires generalization from limited training data to unseen scenarios. Yet, fulfilling tasks under changing circumstances is a key challenge in RL. Current state-of-the-art approaches for generalization apply data augmentation techniques to increase the diversity of training data. Even though this prevents overfitting to the training environment(s), it hinders policy optimization. Crafting a suitable observation, only containing crucial information, has been shown to be a challenging task itself. To improve data efficiency and generalization capabilities, we propose Compact Reshaped Observation Processing (CROP) to reduce the state information used for policy optimization. By providing only relevant information, overfitting to a specific training layout is precluded and generalization to unseen environments is improved. We formulate three CROPs that can be applied to fully observable observation- and action-spaces and provide methodical foundation. We empirically show the improvements of CROP in a distributionally shifted safety gridworld. We furthermore provide benchmark comparisons to full observability and data-augmentation in two different-sized procedurally generated mazes.
DIRECT: Learning from Sparse and Shifting Rewards using Discriminative Reward Co-Training
Jan 18, 2023


We propose discriminative reward co-training (DIRECT) as an extension to deep reinforcement learning algorithms. Building upon the concept of self-imitation learning (SIL), we introduce an imitation buffer to store beneficial trajectories generated by the policy determined by their return. A discriminator network is trained concurrently to the policy to distinguish between trajectories generated by the current policy and beneficial trajectories generated by previous policies. The discriminator's verdict is used to construct a reward signal for optimizing the policy. By interpolating prior experience, DIRECT is able to act as a surrogate, steering policy optimization towards more valuable regions of the reward landscape thus learning an optimal policy. Our results show that DIRECT outperforms state-of-the-art algorithms in sparse- and shifting-reward environments being able to provide a surrogate reward to the policy and direct the optimization towards valuable areas.
Capturing Dependencies within Machine Learning via a Formal Process Model
Aug 10, 2022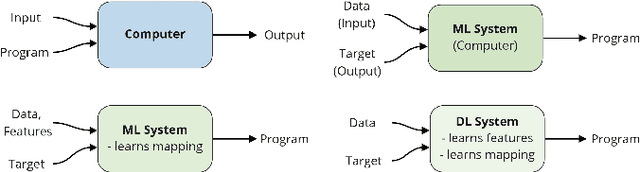
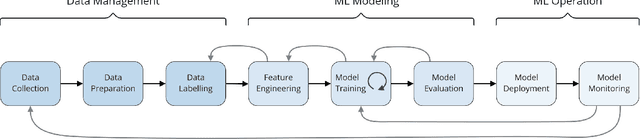
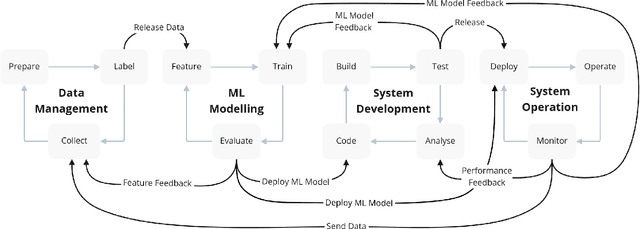
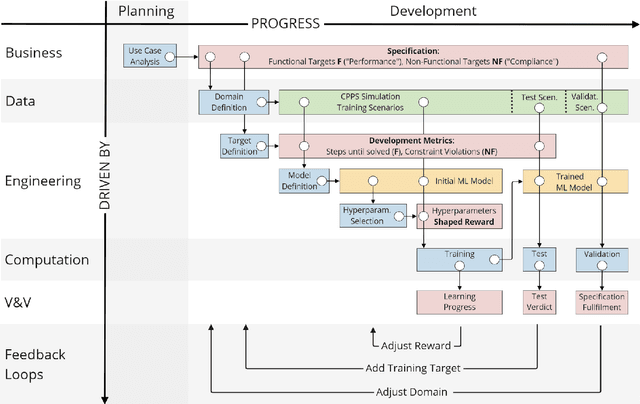
The development of Machine Learning (ML) models is more than just a special case of software development (SD): ML models acquire properties and fulfill requirements even without direct human interaction in a seemingly uncontrollable manner. Nonetheless, the underlying processes can be described in a formal way. We define a comprehensive SD process model for ML that encompasses most tasks and artifacts described in the literature in a consistent way. In addition to the production of the necessary artifacts, we also focus on generating and validating fitting descriptions in the form of specifications. We stress the importance of further evolving the ML model throughout its life-cycle even after initial training and testing. Thus, we provide various interaction points with standard SD processes in which ML often is an encapsulated task. Further, our SD process model allows to formulate ML as a (meta-) optimization problem. If automated rigorously, it can be used to realize self-adaptive autonomous systems. Finally, our SD process model features a description of time that allows to reason about the progress within ML development processes. This might lead to further applications of formal methods within the field of ML.
Acoustic Leak Detection in Water Networks
Jan 05, 2021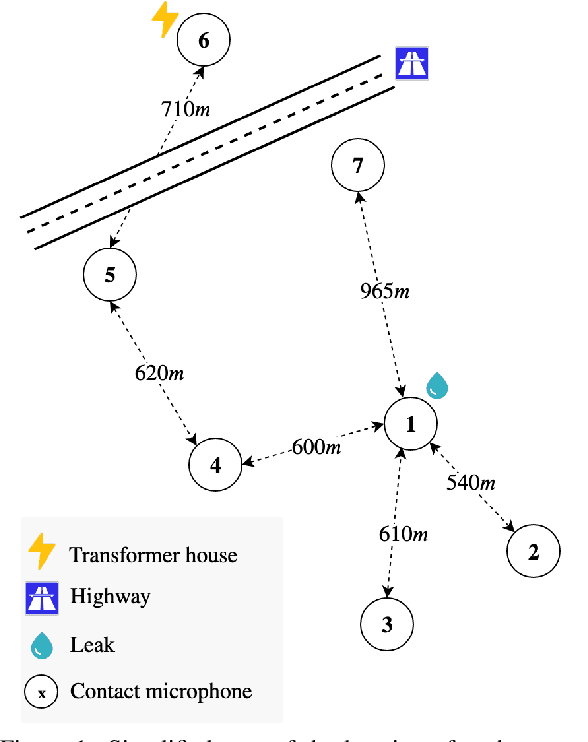
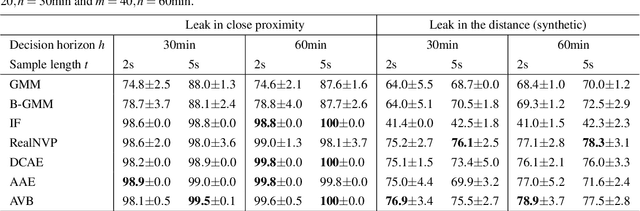
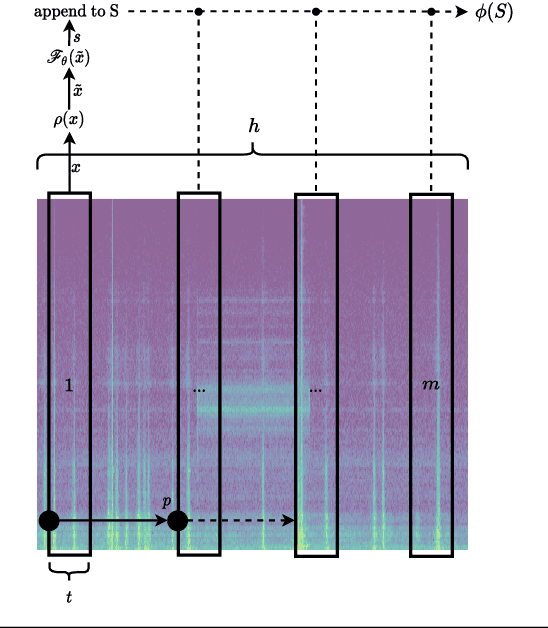
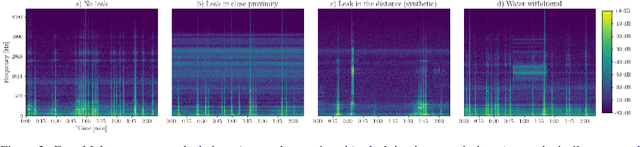
In this work, we present a general procedure for acoustic leak detection in water networks that satisfies multiple real-world constraints such as energy efficiency and ease of deployment. Based on recordings from seven contact microphones attached to the water supply network of a municipal suburb, we trained several shallow and deep anomaly detection models. Inspired by how human experts detect leaks using electronic sounding-sticks, we use these models to repeatedly listen for leaks over a predefined decision horizon. This way we avoid constant monitoring of the system. While we found the detection of leaks in close proximity to be a trivial task for almost all models, neural network based approaches achieve better results at the detection of distant leaks.
SAT-MARL: Specification Aware Training in Multi-Agent Reinforcement Learning
Dec 14, 2020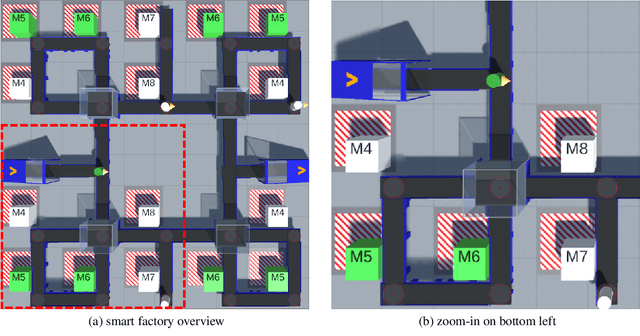
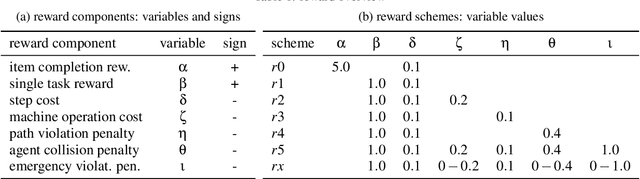
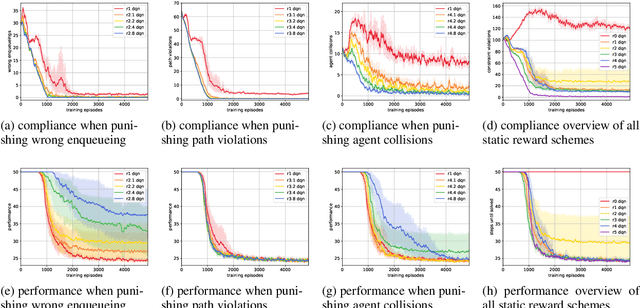
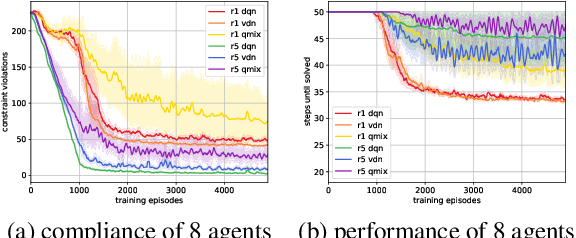
A characteristic of reinforcement learning is the ability to develop unforeseen strategies when solving problems. While such strategies sometimes yield superior performance, they may also result in undesired or even dangerous behavior. In industrial scenarios, a system's behavior also needs to be predictable and lie within defined ranges. To enable the agents to learn (how) to align with a given specification, this paper proposes to explicitly transfer functional and non-functional requirements into shaped rewards. Experiments are carried out on the smart factory, a multi-agent environment modeling an industrial lot-size-one production facility, with up to eight agents and different multi-agent reinforcement learning algorithms. Results indicate that compliance with functional and non-functional constraints can be achieved by the proposed approach.