 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Lottery Ticket Networks using Genetic Algorithms
Aug 12, 2025Building modern deep learning systems that are not just effective but also efficient requires rethinking established paradigms for model training and neural architecture design. Instead of adapting highly overparameterized networks and subsequently applying model compression techniques to reduce resource consumption, a new class of high-performing networks skips the need for expensive parameter updates, while requiring only a fraction of parameters, making them highly scalable. The Strong Lottery Ticket Hypothesis posits that within randomly initialized, sufficiently overparameterized neural networks, there exist subnetworks that can match the accuracy of the trained original model-without any training. This work explores the usage of genetic algorithms for identifying these strong lottery ticket subnetworks. We find that for instances of binary and multi-class classification tasks, our approach achieves better accuracies and sparsity levels than the current state-of-the-art without requiring any gradient information. In addition, we provide justification for the need for appropriate evaluation metrics when scaling to more complex network architectures and learning tasks.
Swarm Behavior Cloning
Dec 10, 2024In sequential decision-making environments, the primary approaches for training agents are Reinforcement Learning (RL) and Imitation Learning (IL). Unlike RL, which relies on modeling a reward function, IL leverages expert demonstrations, where an expert policy $\pi_e$ (e.g., a human) provides the desired behavior. Formally, a dataset $D$ of state-action pairs is provided: $D = {(s, a = \pi_e(s))}$. A common technique within IL is Behavior Cloning (BC), where a policy $\pi(s) = a$ is learned through supervised learning on $D$. Further improvements can be achieved by using an ensemble of $N$ individually trained BC policies, denoted as $E = {\pi_i(s)}{1 \leq i \leq N}$. The ensemble's action $a$ for a given state $s$ is the aggregated output of the $N$ actions: $a = \frac{1}{N} \sum{i} \pi_i(s)$. This paper addresses the issue of increasing action differences -- the observation that discrepancies between the $N$ predicted actions grow in states that are underrepresented in the training data. Large action differences can result in suboptimal aggregated actions. To address this, we propose a method that fosters greater alignment among the policies while preserving the diversity of their computations. This approach reduces action differences and ensures that the ensemble retains its inherent strengths, such as robustness and varied decision-making. We evaluate our approach across eight diverse environments, demonstrating a notable decrease in action differences and significant improvements in overall performance, as measured by mean episode returns.
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
Dec 10, 2024



Reinforcement Learning (RL) policies are designed to predict actions based on current observations to maximize cumulative future rewards. In real-world applications (i.e., non-simulated environments), sensors are essential for measuring the current state and providing the observations on which RL policies rely to make decisions. A significant challenge in deploying RL policies in real-world scenarios is handling sensor dropouts, which can result from hardware malfunctions, physical damage, or environmental factors like dust on a camera lens. A common strategy to mitigate this issue is the use of backup sensors, though this comes with added costs. This paper explores the optimization of backup sensor configurations to maximize expected returns while keeping costs below a specified threshold, C. Our approach uses a second-order approximation of expected returns and includes penalties for exceeding cost constraints. We then optimize this quadratic program using Tabu Search, a meta-heuristic algorithm. The approach is evaluated across eight OpenAI Gym environments and a custom Unity-based robotic environment (RobotArmGrasping). Empirical results demonstrate that our quadratic program effectively approximates real expected returns, facilitating the identification of optimal sensor configurations.
Architectural Influence on Variational Quantum Circuits in Multi-Agent Reinforcement Learning: Evolutionary Strategies for Optimization
Jul 30, 2024



In recent years, Multi-Agent Reinforcement Learning (MARL) has found application in numerous areas of science and industry, such as autonomous driving, telecommunications, and global health. Nevertheless, MARL suffers from, for instance, an exponential growth of dimensions. Inherent properties of quantum mechanics help to overcome these limitations, e.g., by significantly reducing the number of trainable parameters. Previous studies have developed an approach that uses gradient-free quantum Reinforcement Learning and evolutionary optimization for variational quantum circuits (VQCs) to reduce the trainable parameters and avoid barren plateaus as well as vanishing gradients. This leads to a significantly better performance of VQCs compared to classical neural networks with a similar number of trainable parameters and a reduction in the number of parameters by more than 97 \% compared to similarly good neural networks. We extend an approach of K\"olle et al. by proposing a Gate-Based, a Layer-Based, and a Prototype-Based concept to mutate and recombine VQCs. Our results show the best performance for mutation-only strategies and the Gate-Based approach. In particular, we observe a significantly better score, higher total and own collected coins, as well as a superior own coin rate for the best agent when evaluated in the Coin Game environment.
Qandle: Accelerating State Vector Simulation Using Gate-Matrix Caching and Circuit Splitting
Apr 14, 2024



To address the computational complexity associated with state-vector simulation for quantum circuits, we propose a combination of advanced techniques to accelerate circuit execution. Quantum gate matrix caching reduces the overhead of repeated applications of the Kronecker product when applying a gate matrix to the state vector by storing decomposed partial matrices for each gate. Circuit splitting divides the circuit into sub-circuits with fewer gates by constructing a dependency graph, enabling parallel or sequential execution on disjoint subsets of the state vector. These techniques are implemented using the PyTorch machine learning framework. We demonstrate the performance of our approach by comparing it to other PyTorch-compatible quantum state-vector simulators. Our implementation, named Qandle, is designed to seamlessly integrate with existing machine learning workflows, providing a user-friendly API and compatibility with the OpenQASM format. Qandle is an open-source project hosted on GitHub https://github.com/gstenzel/qandle and PyPI https://pypi.org/project/qandle/ .
ClusterComm: Discrete Communication in Decentralized MARL using Internal Representation Clustering
Jan 07, 2024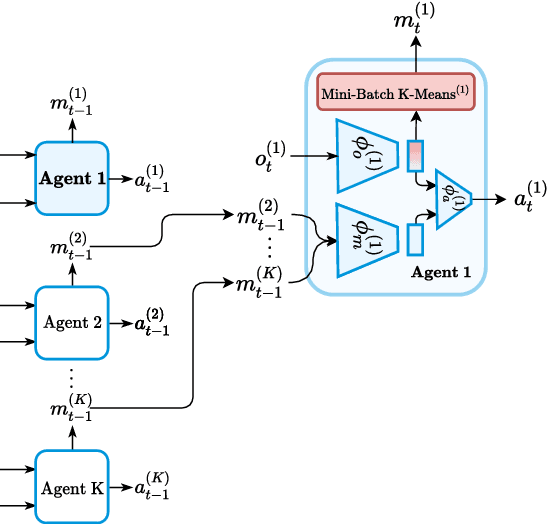
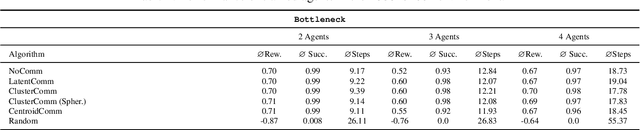

In the realm of Multi-Agent Reinforcement Learning (MARL), prevailing approaches exhibit shortcomings in aligning with human learning, robustness, and scalability. Addressing this, we introduce ClusterComm, a fully decentralized MARL framework where agents communicate discretely without a central control unit. ClusterComm utilizes Mini-Batch-K-Means clustering on the last hidden layer's activations of an agent's policy network, translating them into discrete messages. This approach outperforms no communication and competes favorably with unbounded, continuous communication and hence poses a simple yet effective strategy for enhancing collaborative task-solving in MARL.
Multi-Agent Quantum Reinforcement Learning using Evolutionary Optimization
Nov 09, 2023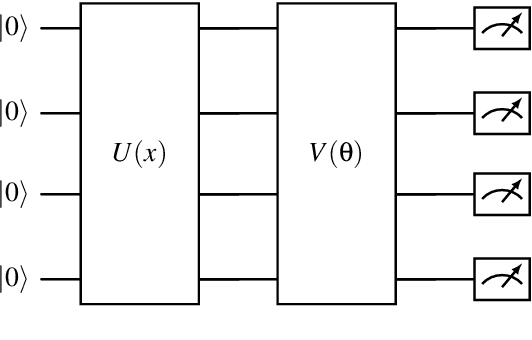



Multi-Agent Reinforcement Learning is becoming increasingly more important in times of autonomous driving and other smart industrial applications. Simultaneously a promising new approach to Reinforcement Learning arises using the inherent properties of quantum mechanics, reducing the trainable parameters of a model significantly. However, gradient-based Multi-Agent Quantum Reinforcement Learning methods often have to struggle with barren plateaus, holding them back from matching the performance of classical approaches. We build upon a existing approach for gradient free Quantum Reinforcement Learning and propose tree approaches with Variational Quantum Circuits for Multi-Agent Reinforcement Learning using evolutionary optimization. We evaluate our approach in the Coin Game environment and compare them to classical approaches. We showed that our Variational Quantum Circuit approaches perform significantly better compared to a neural network with a similar amount of trainable parameters. Compared to the larger neural network, our approaches archive similar results using $97.88\%$ less parameters.
Improving Primate Sounds Classification using Binary Presorting for Deep Learning
Jun 28, 2023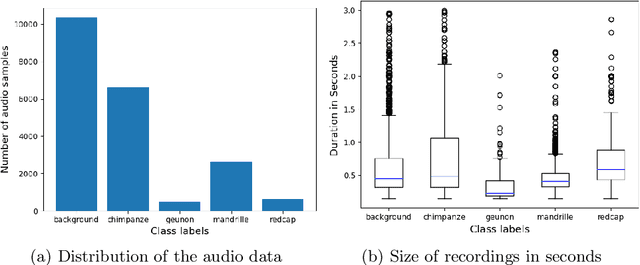
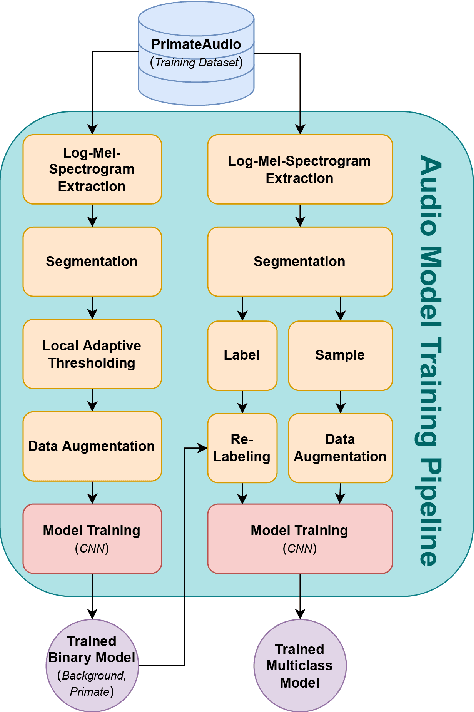
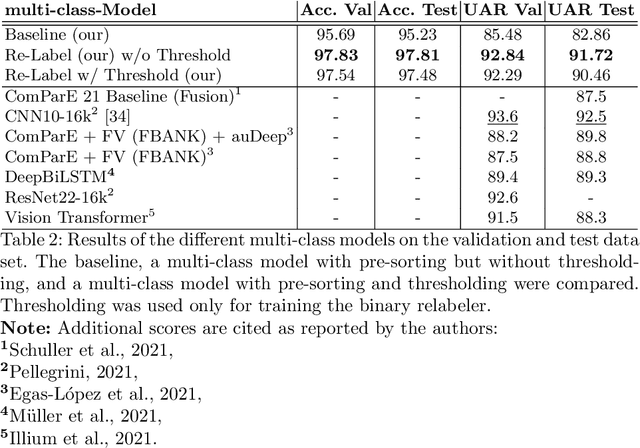
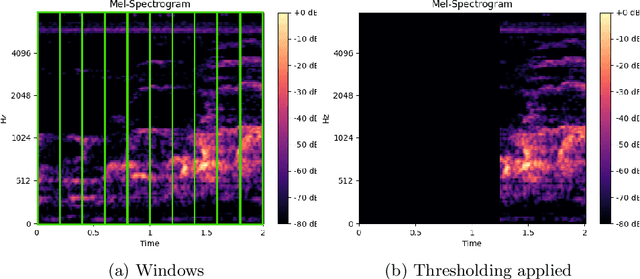
In the field of wildlife observation and conservation, approaches involving machine learning on audio recordings are becoming increasingly popular. Unfortunately, available datasets from this field of research are often not optimal learning material; Samples can be weakly labeled, of different lengths or come with a poor signal-to-noise ratio. In this work, we introduce a generalized approach that first relabels subsegments of MEL spectrogram representations, to achieve higher performances on the actual multi-class classification tasks. For both the binary pre-sorting and the classification, we make use of convolutional neural networks (CNN) and various data-augmentation techniques. We showcase the results of this approach on the challenging \textit{ComparE 2021} dataset, with the task of classifying between different primate species sounds, and report significantly higher Accuracy and UAR scores in contrast to comparatively equipped model baselines.
CROP: Towards Distributional-Shift Robust Reinforcement Learning using Compact Reshaped Observation Processing
Apr 26, 2023

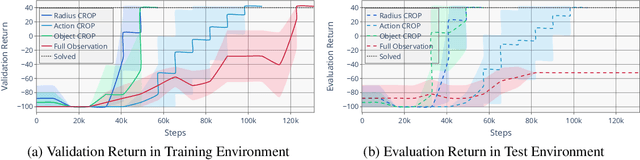
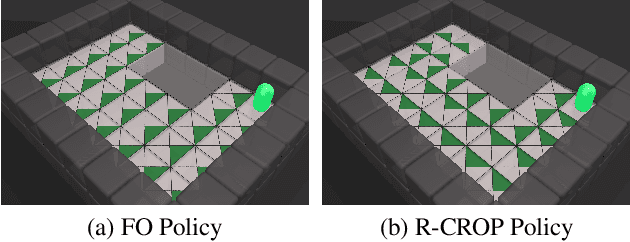
The safe application of reinforcement learning (RL) requires generalization from limited training data to unseen scenarios. Yet, fulfilling tasks under changing circumstances is a key challenge in RL. Current state-of-the-art approaches for generalization apply data augmentation techniques to increase the diversity of training data. Even though this prevents overfitting to the training environment(s), it hinders policy optimization. Crafting a suitable observation, only containing crucial information, has been shown to be a challenging task itself. To improve data efficiency and generalization capabilities, we propose Compact Reshaped Observation Processing (CROP) to reduce the state information used for policy optimization. By providing only relevant information, overfitting to a specific training layout is precluded and generalization to unseen environments is improved. We formulate three CROPs that can be applied to fully observable observation- and action-spaces and provide methodical foundation. We empirically show the improvements of CROP in a distributionally shifted safety gridworld. We furthermore provide benchmark comparisons to full observability and data-augmentation in two different-sized procedurally generated mazes.
VoronoiPatches: Evaluating A New Data Augmentation Method
Dec 23, 2022



Overfitting is a problem in Convolutional Neural Networks (CNN) that causes poor generalization of models on unseen data. To remediate this problem, many new and diverse data augmentation methods (DA) have been proposed to supplement or generate more training data, and thereby increase its quality. In this work, we propose a new data augmentation algorithm: VoronoiPatches (VP). We primarily utilize non-linear recombination of information within an image, fragmenting and occluding small information patches. Unlike other DA methods, VP uses small convex polygon-shaped patches in a random layout to transport information around within an image. Sudden transitions created between patches and the original image can, optionally, be smoothed. In our experiments, VP outperformed current DA methods regarding model variance and overfitting tendencies. We demonstrate data augmentation utilizing non-linear re-combination of information within images, and non-orthogonal shapes and structures improves CNN model robustness on unseen data.