 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Parameterized Quantum State Preparation: A Comparative Study
Feb 18, 2026We extend directed quantum circuit synthesis (DQCS) with reinforcement learning from purely discrete gate selection to parameterized quantum state preparation with continuous single-qubit rotations \(R_x\), \(R_y\), and \(R_z\). We compare two training regimes: a one-stage agent that jointly selects the gate type, the affected qubit(s), and the rotation angle; and a two-stage variant that first proposes a discrete circuit and subsequently optimizes the rotation angles with Adam using parameter-shift gradients. Using Gymnasium and PennyLane, we evaluate Proximal Policy Optimization (PPO) and Advantage Actor--Critic (A2C) on systems comprising two to ten qubits and on targets of increasing complexity with \(λ\) ranging from one to five. Whereas A2C does not learn effective policies in this setting, PPO succeeds under stable hyperparameters (one-stage: learning rate approximately \(5\times10^{-4}\) with a self-fidelity-error threshold of 0.01; two-stage: learning rate approximately \(10^{-4}\)). Both approaches reliably reconstruct computational basis states (between 83\% and 99\% success) and Bell states (between 61\% and 77\% success). However, scalability saturates for \(λ\) of approximately three to four and does not extend to ten-qubit targets even at \(λ=2\). The two-stage method offers only marginal accuracy gains while requiring around three times the runtime. For practicality under a fixed compute budget, we therefore recommend the one-stage PPO policy, provide explicit synthesized circuits, and contrast with a classical variational baseline to outline avenues for improved scalability.
Illustration of Barren Plateaus in Quantum Computing
Feb 18, 2026Variational Quantum Circuits (VQCs) have emerged as a promising paradigm for quantum machine learning in the NISQ era. While parameter sharing in VQCs can reduce the parameter space dimensionality and potentially mitigate the barren plateau phenomenon, it introduces a complex trade-off that has been largely overlooked. This paper investigates how parameter sharing, despite creating better global optima with fewer parameters, fundamentally alters the optimization landscape through deceptive gradients -- regions where gradient information exists but systematically misleads optimizers away from global optima. Through systematic experimental analysis, we demonstrate that increasing degrees of parameter sharing generate more complex solution landscapes with heightened gradient magnitudes and measurably higher deceptiveness ratios. Our findings reveal that traditional gradient-based optimizers (Adam, SGD) show progressively degraded convergence as parameter sharing increases, with performance heavily dependent on hyperparameter selection. We introduce a novel gradient deceptiveness detection algorithm and a quantitative framework for measuring optimization difficulty in quantum circuits, establishing that while parameter sharing can improve circuit expressivity by orders of magnitude, this comes at the cost of significantly increased landscape deceptiveness. These insights provide important considerations for quantum circuit design in practical applications, highlighting the fundamental mismatch between classical optimization strategies and quantum parameter landscapes shaped by parameter sharing.
Emergent Cooperation in Quantum Multi-Agent Reinforcement Learning Using Communication
Jan 26, 2026Emergent cooperation in classical Multi-Agent Reinforcement Learning has gained significant attention, particularly in the context of Sequential Social Dilemmas (SSDs). While classical reinforcement learning approaches have demonstrated capability for emergent cooperation, research on extending these methods to Quantum Multi-Agent Reinforcement Learning remains limited, particularly through communication. In this paper, we apply communication approaches to quantum Q-Learning agents: the Mutual Acknowledgment Token Exchange (MATE) protocol, its extension Mutually Endorsed Distributed Incentive Acknowledgment Token Exchange (MEDIATE), the peer rewarding mechanism Gifting, and Reinforced Inter-Agent Learning (RIAL). We evaluate these approaches in three SSDs: the Iterated Prisoner's Dilemma, Iterated Stag Hunt, and Iterated Game of Chicken. Our experimental results show that approaches using MATE with temporal-difference measure (MATE\textsubscript{TD}), AutoMATE, MEDIATE-I, and MEDIATE-S achieved high cooperation levels across all dilemmas, demonstrating that communication is a viable mechanism for fostering emergent cooperation in Quantum Multi-Agent Reinforcement Learning.
Quantum King-Ring Domination in Chess: A QAOA Approach
Jan 01, 2026The Quantum Approximate Optimization Algorithm (QAOA) is extensively benchmarked on synthetic random instances such as MaxCut, TSP, and SAT problems, but these lack semantic structure and human interpretability, offering limited insight into performance on real-world problems with meaningful constraints. We introduce Quantum King-Ring Domination (QKRD), a NISQ-scale benchmark derived from chess tactical positions that provides 5,000 structured instances with one-hot constraints, spatial locality, and 10--40 qubit scale. The benchmark pairs human-interpretable coverage metrics with intrinsic validation against classical heuristics, enabling algorithmic conclusions without external oracles. Using QKRD, we systematically evaluate QAOA design choices and find that constraint-preserving mixers (XY, domain-wall) converge approximately 13 steps faster than standard mixers (p<10^{-7}, d\approx0.5) while eliminating penalty tuning, warm-start strategies reduce convergence by 45 steps (p<10^{-127}, d=3.35) with energy improvements exceeding d=8, and Conditional Value-at-Risk (CVaR) optimization yields an informative negative result with worse energy (p<10^{-40}, d=1.21) and no coverage benefit. Intrinsic validation shows QAOA outperforms greedy heuristics by 12.6\% and random selection by 80.1\%. Our results demonstrate that structured benchmarks reveal advantages of problem-informed QAOA techniques obscured in random instances. We release all code, data, and experimental artifacts for reproducible NISQ algorithm research.
Topology-Guided Quantum GANs for Constrained Graph Generation
Dec 11, 2025Quantum computing (QC) promises theoretical advantages, benefiting computational problems that would not be efficiently classically simulatable. However, much of this theoretical speedup depends on the quantum circuit design solving the problem. We argue that QC literature has yet to explore more domain specific ansatz-topologies, instead of relying on generic, one-size-fits-all architectures. In this work, we show that incorporating task-specific inductive biases -- specifically geometric priors -- into quantum circuit design can enhance the performance of hybrid Quantum Generative Adversarial Networks (QuGANs) on the task of generating geometrically constrained K4 graphs. We evaluate a portfolio of entanglement topologies and loss-function designs to assess their impact on both statistical fidelity and compliance with geometric constraints, including the Triangle and Ptolemaic inequalities. Our results show that aligning circuit topology with the underlying problem structure yields substantial benefits: the Triangle-topology QuGAN achieves the highest geometric validity among quantum models and matches the performance of classical Generative Adversarial Networks (GAN). Additionally, we showcase how specific architectural choices, such as entangling gate types, variance regularization and output-scaling govern the trade-off between geometric consistency and distributional accuracy, thus emphasizing the value of structured, task-aware quantum ansatz-topologies.
Evaluating Mutation Techniques in Genetic Algorithm-Based Quantum Circuit Synthesis
Apr 08, 2025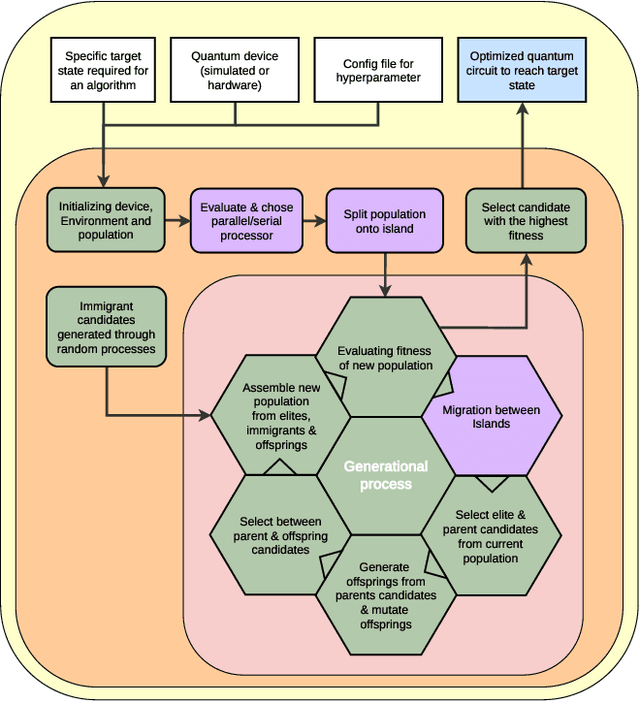
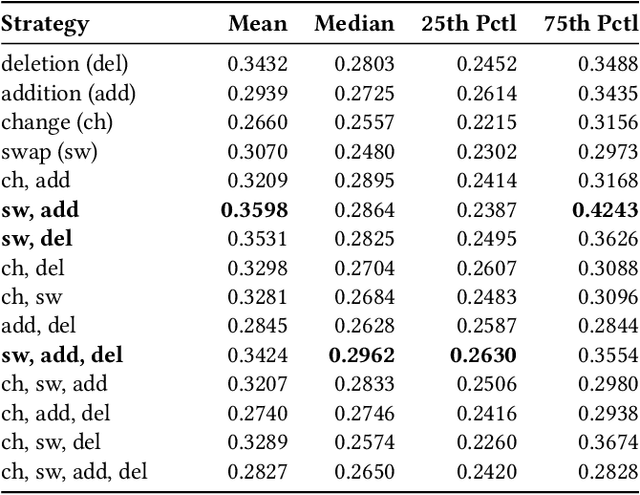
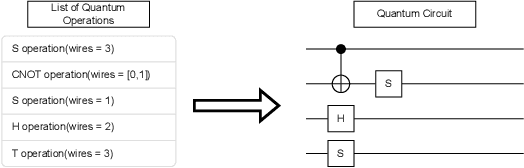
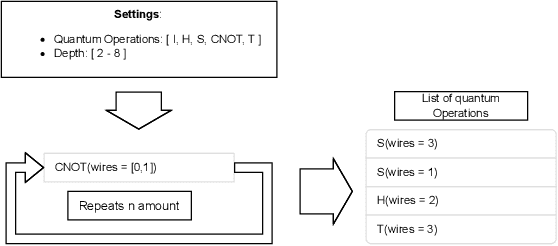
Quantum computing leverages the unique properties of qubits and quantum parallelism to solve problems intractable for classical systems, offering unparalleled computational potential. However, the optimization of quantum circuits remains critical, especially for noisy intermediate-scale quantum (NISQ) devices with limited qubits and high error rates. Genetic algorithms (GAs) provide a promising approach for efficient quantum circuit synthesis by automating optimization tasks. This work examines the impact of various mutation strategies within a GA framework for quantum circuit synthesis. By analyzing how different mutations transform circuits, it identifies strategies that enhance efficiency and performance. Experiments utilized a fitness function emphasizing fidelity, while accounting for circuit depth and T operations, to optimize circuits with four to six qubits. Comprehensive hyperparameter testing revealed that combining delete and swap strategies outperformed other approaches, demonstrating their effectiveness in developing robust GA-based quantum circuit optimizers.
PIMAEX: Multi-Agent Exploration through Peer Incentivization
Jan 02, 2025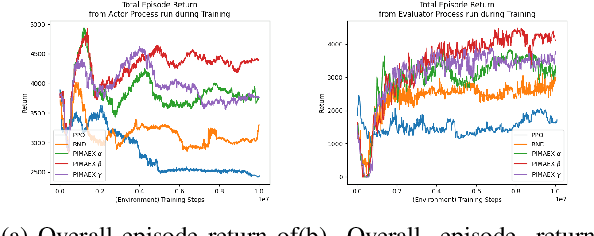

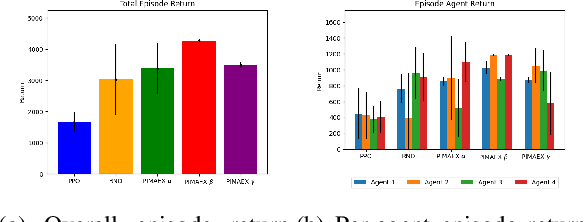
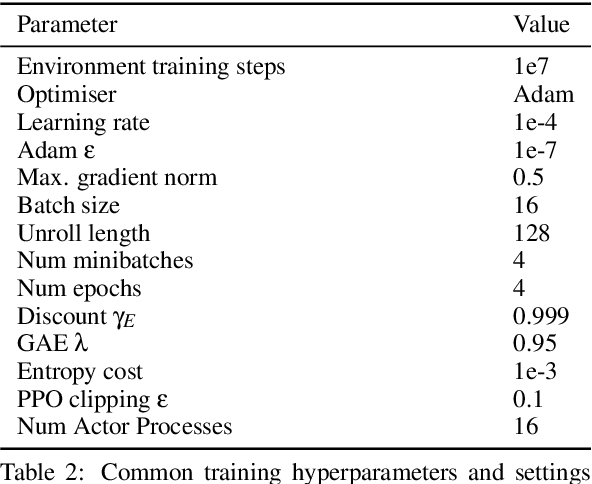
While exploration in single-agent reinforcement learning has been studied extensively in recent years, considerably less work has focused on its counterpart in multi-agent reinforcement learning. To address this issue, this work proposes a peer-incentivized reward function inspired by previous research on intrinsic curiosity and influence-based rewards. The \textit{PIMAEX} reward, short for Peer-Incentivized Multi-Agent Exploration, aims to improve exploration in the multi-agent setting by encouraging agents to exert influence over each other to increase the likelihood of encountering novel states. We evaluate the \textit{PIMAEX} reward in conjunction with \textit{PIMAEX-Communication}, a multi-agent training algorithm that employs a communication channel for agents to influence one another. The evaluation is conducted in the \textit{Consume/Explore} environment, a partially observable environment with deceptive rewards, specifically designed to challenge the exploration vs.\ exploitation dilemma and the credit-assignment problem. The results empirically demonstrate that agents using the \textit{PIMAEX} reward with \textit{PIMAEX-Communication} outperform those that do not.
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
Dec 10, 2024



Reinforcement Learning (RL) policies are designed to predict actions based on current observations to maximize cumulative future rewards. In real-world applications (i.e., non-simulated environments), sensors are essential for measuring the current state and providing the observations on which RL policies rely to make decisions. A significant challenge in deploying RL policies in real-world scenarios is handling sensor dropouts, which can result from hardware malfunctions, physical damage, or environmental factors like dust on a camera lens. A common strategy to mitigate this issue is the use of backup sensors, though this comes with added costs. This paper explores the optimization of backup sensor configurations to maximize expected returns while keeping costs below a specified threshold, C. Our approach uses a second-order approximation of expected returns and includes penalties for exceeding cost constraints. We then optimize this quadratic program using Tabu Search, a meta-heuristic algorithm. The approach is evaluated across eight OpenAI Gym environments and a custom Unity-based robotic environment (RobotArmGrasping). Empirical results demonstrate that our quadratic program effectively approximates real expected returns, facilitating the identification of optimal sensor configurations.
A Study on Optimization Techniques for Variational Quantum Circuits in Reinforcement Learning
May 20, 2024Quantum Computing aims to streamline machine learning, making it more effective with fewer trainable parameters. This reduction of parameters can speed up the learning process and reduce the use of computational resources. However, in the current phase of quantum computing development, known as the noisy intermediate-scale quantum era (NISQ), learning is difficult due to a limited number of qubits and widespread quantum noise. To overcome these challenges, researchers are focusing on variational quantum circuits (VQCs). VQCs are hybrid algorithms that merge a quantum circuit, which can be adjusted through parameters, with traditional classical optimization techniques. These circuits require only few qubits for effective learning. Recent studies have presented new ways of applying VQCs to reinforcement learning, showing promising results that warrant further exploration. This study investigates the effects of various techniques -- data re-uploading, input scaling, output scaling -- and introduces exponential learning rate decay in the quantum proximal policy optimization algorithm's actor-VQC. We assess these methods in the popular Frozen Lake and Cart Pole environments. Our focus is on their ability to reduce the number of parameters in the VQC without losing effectiveness. Our findings indicate that data re-uploading and an exponential learning rate decay significantly enhance hyperparameter stability and overall performance. While input scaling does not improve parameter efficiency, output scaling effectively manages greediness, leading to increased learning speed and robustness.
Qandle: Accelerating State Vector Simulation Using Gate-Matrix Caching and Circuit Splitting
Apr 14, 2024



To address the computational complexity associated with state-vector simulation for quantum circuits, we propose a combination of advanced techniques to accelerate circuit execution. Quantum gate matrix caching reduces the overhead of repeated applications of the Kronecker product when applying a gate matrix to the state vector by storing decomposed partial matrices for each gate. Circuit splitting divides the circuit into sub-circuits with fewer gates by constructing a dependency graph, enabling parallel or sequential execution on disjoint subsets of the state vector. These techniques are implemented using the PyTorch machine learning framework. We demonstrate the performance of our approach by comparing it to other PyTorch-compatible quantum state-vector simulators. Our implementation, named Qandle, is designed to seamlessly integrate with existing machine learning workflows, providing a user-friendly API and compatibility with the OpenQASM format. Qandle is an open-source project hosted on GitHub https://github.com/gstenzel/qandle and PyPI https://pypi.org/project/qandle/ .