 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Cooperation in Quantum Multi-Agent Reinforcement Learning Using Communication
Jan 26, 2026Emergent cooperation in classical Multi-Agent Reinforcement Learning has gained significant attention, particularly in the context of Sequential Social Dilemmas (SSDs). While classical reinforcement learning approaches have demonstrated capability for emergent cooperation, research on extending these methods to Quantum Multi-Agent Reinforcement Learning remains limited, particularly through communication. In this paper, we apply communication approaches to quantum Q-Learning agents: the Mutual Acknowledgment Token Exchange (MATE) protocol, its extension Mutually Endorsed Distributed Incentive Acknowledgment Token Exchange (MEDIATE), the peer rewarding mechanism Gifting, and Reinforced Inter-Agent Learning (RIAL). We evaluate these approaches in three SSDs: the Iterated Prisoner's Dilemma, Iterated Stag Hunt, and Iterated Game of Chicken. Our experimental results show that approaches using MATE with temporal-difference measure (MATE\textsubscript{TD}), AutoMATE, MEDIATE-I, and MEDIATE-S achieved high cooperation levels across all dilemmas, demonstrating that communication is a viable mechanism for fostering emergent cooperation in Quantum Multi-Agent Reinforcement Learning.
Quantum King-Ring Domination in Chess: A QAOA Approach
Jan 01, 2026The Quantum Approximate Optimization Algorithm (QAOA) is extensively benchmarked on synthetic random instances such as MaxCut, TSP, and SAT problems, but these lack semantic structure and human interpretability, offering limited insight into performance on real-world problems with meaningful constraints. We introduce Quantum King-Ring Domination (QKRD), a NISQ-scale benchmark derived from chess tactical positions that provides 5,000 structured instances with one-hot constraints, spatial locality, and 10--40 qubit scale. The benchmark pairs human-interpretable coverage metrics with intrinsic validation against classical heuristics, enabling algorithmic conclusions without external oracles. Using QKRD, we systematically evaluate QAOA design choices and find that constraint-preserving mixers (XY, domain-wall) converge approximately 13 steps faster than standard mixers (p<10^{-7}, d\approx0.5) while eliminating penalty tuning, warm-start strategies reduce convergence by 45 steps (p<10^{-127}, d=3.35) with energy improvements exceeding d=8, and Conditional Value-at-Risk (CVaR) optimization yields an informative negative result with worse energy (p<10^{-40}, d=1.21) and no coverage benefit. Intrinsic validation shows QAOA outperforms greedy heuristics by 12.6\% and random selection by 80.1\%. Our results demonstrate that structured benchmarks reveal advantages of problem-informed QAOA techniques obscured in random instances. We release all code, data, and experimental artifacts for reproducible NISQ algorithm research.
Evaluating Parameter-Based Training Performance of Neural Networks and Variational Quantum Circuits
Apr 09, 2025



In recent years, neural networks (NNs) have driven significant advances in machine learning. However, as tasks grow more complex, NNs often require large numbers of trainable parameters, which increases computational and energy demands. Variational quantum circuits (VQCs) offer a promising alternative: they leverage quantum mechanics to capture intricate relationships and typically need fewer parameters. In this work, we evaluate NNs and VQCs on simple supervised and reinforcement learning tasks, examining models with different parameter sizes. We simulate VQCs and execute selected parts of the training process on real quantum hardware to approximate actual training times. Our results show that VQCs can match NNs in performance while using significantly fewer parameters, despite longer training durations. As quantum technology and algorithms advance, and VQC architectures improve, we posit that VQCs could become advantageous for certain machine learning tasks.
Evaluating Mutation Techniques in Genetic Algorithm-Based Quantum Circuit Synthesis
Apr 08, 2025Quantum computing leverages the unique properties of qubits and quantum parallelism to solve problems intractable for classical systems, offering unparalleled computational potential. However, the optimization of quantum circuits remains critical, especially for noisy intermediate-scale quantum (NISQ) devices with limited qubits and high error rates. Genetic algorithms (GAs) provide a promising approach for efficient quantum circuit synthesis by automating optimization tasks. This work examines the impact of various mutation strategies within a GA framework for quantum circuit synthesis. By analyzing how different mutations transform circuits, it identifies strategies that enhance efficiency and performance. Experiments utilized a fitness function emphasizing fidelity, while accounting for circuit depth and T operations, to optimize circuits with four to six qubits. Comprehensive hyperparameter testing revealed that combining delete and swap strategies outperformed other approaches, demonstrating their effectiveness in developing robust GA-based quantum circuit optimizers.
Investigating Parameter-Efficiency of Hybrid QuGANs Based on Geometric Properties of Generated Sea Route Graphs
Jan 15, 2025The demand for artificially generated data for the development, training and testing of new algorithms is omnipresent. Quantum computing (QC), does offer the hope that its inherent probabilistic functionality can be utilised in this field of generative artificial intelligence. In this study, we use quantum-classical hybrid generative adversarial networks (QuGANs) to artificially generate graphs of shipping routes. We create a training dataset based on real shipping data and investigate to what extent QuGANs are able to learn and reproduce inherent distributions and geometric features of this data. We compare hybrid QuGANs with classical Generative Adversarial Networks (GANs), with a special focus on their parameter efficiency. Our results indicate that QuGANs are indeed able to quickly learn and represent underlying geometric properties and distributions, although they seem to have difficulties in introducing variance into the sampled data. Compared to classical GANs of greater size, measured in the number of parameters used, some QuGANs show similar result quality. Our reference to concrete use cases, such as the generation of shipping data, provides an illustrative example and demonstrate the potential and diversity in which QC can be used.
Optimization of Link Configuration for Satellite Communication Using Reinforcement Learning
Jan 14, 2025Satellite communication is a key technology in our modern connected world. With increasingly complex hardware, one challenge is to efficiently configure links (connections) on a satellite transponder. Planning an optimal link configuration is extremely complex and depends on many parameters and metrics. The optimal use of the limited resources, bandwidth and power of the transponder is crucial. Such an optimization problem can be approximated using metaheuristic methods such as simulated annealing, but recent research results also show that reinforcement learning can achieve comparable or even better performance in optimization methods. However, there have not yet been any studies on link configuration on satellite transponders. In order to close this research gap, a transponder environment was developed as part of this work. For this environment, the performance of the reinforcement learning algorithm PPO was compared with the metaheuristic simulated annealing in two experiments. The results show that Simulated Annealing delivers better results for this static problem than the PPO algorithm, however, the research in turn also underlines the potential of reinforcement learning for optimization problems.
PIMAEX: Multi-Agent Exploration through Peer Incentivization
Jan 02, 2025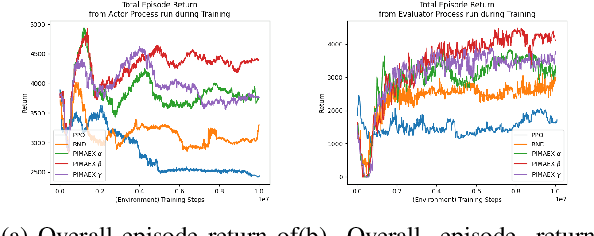

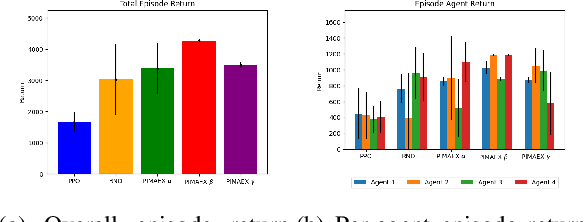
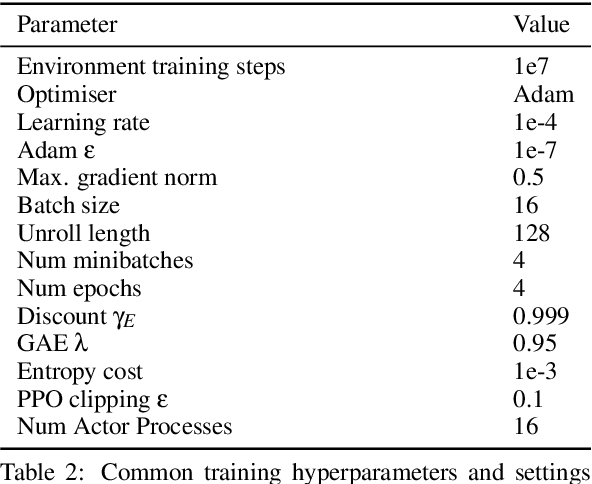
While exploration in single-agent reinforcement learning has been studied extensively in recent years, considerably less work has focused on its counterpart in multi-agent reinforcement learning. To address this issue, this work proposes a peer-incentivized reward function inspired by previous research on intrinsic curiosity and influence-based rewards. The \textit{PIMAEX} reward, short for Peer-Incentivized Multi-Agent Exploration, aims to improve exploration in the multi-agent setting by encouraging agents to exert influence over each other to increase the likelihood of encountering novel states. We evaluate the \textit{PIMAEX} reward in conjunction with \textit{PIMAEX-Communication}, a multi-agent training algorithm that employs a communication channel for agents to influence one another. The evaluation is conducted in the \textit{Consume/Explore} environment, a partially observable environment with deceptive rewards, specifically designed to challenge the exploration vs.\ exploitation dilemma and the credit-assignment problem. The results empirically demonstrate that agents using the \textit{PIMAEX} reward with \textit{PIMAEX-Communication} outperform those that do not.
Coconut Palm Tree Counting on Drone Images with Deep Object Detection and Synthetic Training Data
Dec 16, 2024



Drones have revolutionized various domains, including agriculture. Recent advances in deep learning have propelled among other things object detection in computer vision. This study utilized YOLO, a real-time object detector, to identify and count coconut palm trees in Ghanaian farm drone footage. The farm presented has lost track of its trees due to different planting phases. While manual counting would be very tedious and error-prone, accurately determining the number of trees is crucial for efficient planning and management of agricultural processes, especially for optimizing yields and predicting production. We assessed YOLO for palm detection within a semi-automated framework, evaluated accuracy augmentations, and pondered its potential for farmers. Data was captured in September 2022 via drones. To optimize YOLO with scarce data, synthetic images were created for model training and validation. The YOLOv7 model, pretrained on the COCO dataset (excluding coconut palms), was adapted using tailored data. Trees from footage were repositioned on synthetic images, with testing on distinct authentic images. In our experiments, we adjusted hyperparameters, improving YOLO's mean average precision (mAP). We also tested various altitudes to determine the best drone height. From an initial mAP@.5 of $0.65$, we achieved 0.88, highlighting the value of synthetic images in agricultural scenarios.
Architectural Influence on Variational Quantum Circuits in Multi-Agent Reinforcement Learning: Evolutionary Strategies for Optimization
Jul 30, 2024



In recent years, Multi-Agent Reinforcement Learning (MARL) has found application in numerous areas of science and industry, such as autonomous driving, telecommunications, and global health. Nevertheless, MARL suffers from, for instance, an exponential growth of dimensions. Inherent properties of quantum mechanics help to overcome these limitations, e.g., by significantly reducing the number of trainable parameters. Previous studies have developed an approach that uses gradient-free quantum Reinforcement Learning and evolutionary optimization for variational quantum circuits (VQCs) to reduce the trainable parameters and avoid barren plateaus as well as vanishing gradients. This leads to a significantly better performance of VQCs compared to classical neural networks with a similar number of trainable parameters and a reduction in the number of parameters by more than 97 \% compared to similarly good neural networks. We extend an approach of K\"olle et al. by proposing a Gate-Based, a Layer-Based, and a Prototype-Based concept to mutate and recombine VQCs. Our results show the best performance for mutation-only strategies and the Gate-Based approach. In particular, we observe a significantly better score, higher total and own collected coins, as well as a superior own coin rate for the best agent when evaluated in the Coin Game environment.
Efficient Quantum One-Class Support Vector Machines for Anomaly Detection Using Randomized Measurements and Variable Subsampling
Jul 30, 2024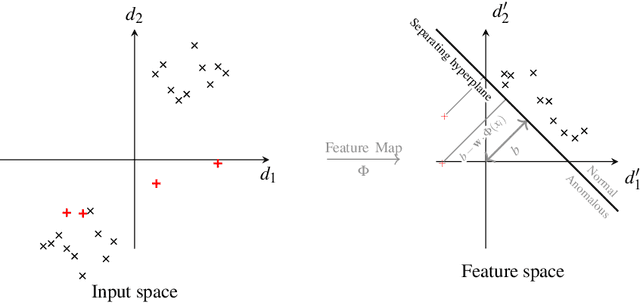
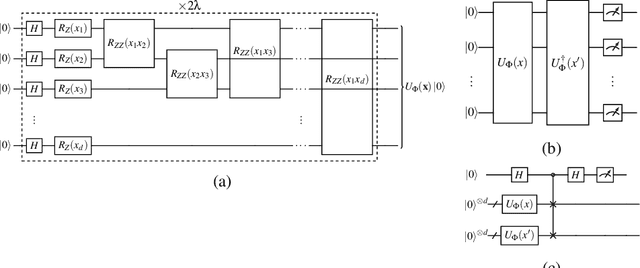
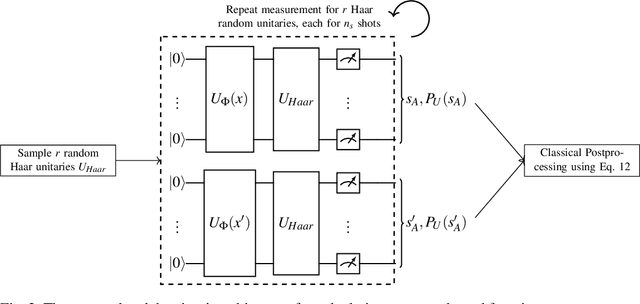
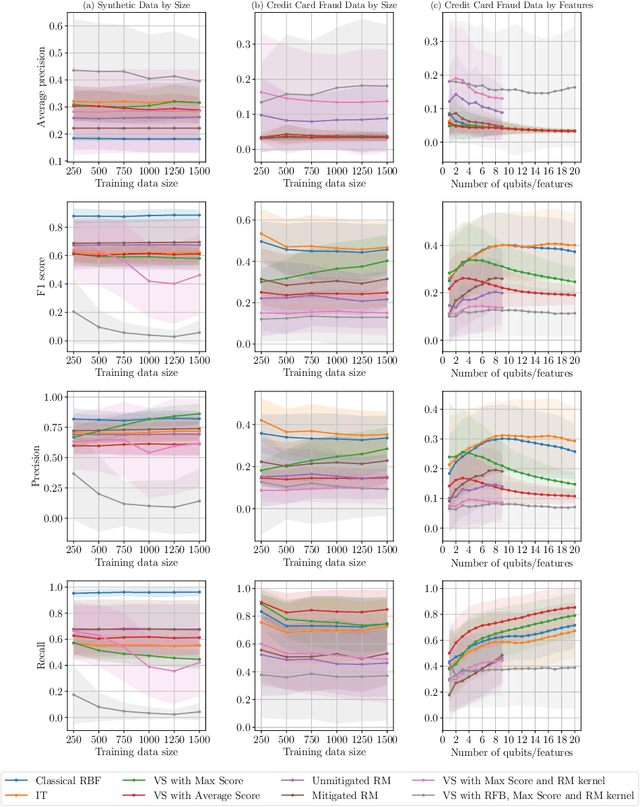
Quantum one-class support vector machines leverage the advantage of quantum kernel methods for semi-supervised anomaly detection. However, their quadratic time complexity with respect to data size poses challenges when dealing with large datasets. In recent work, quantum randomized measurements kernels and variable subsampling were proposed, as two independent methods to address this problem. The former achieves higher average precision, but suffers from variance, while the latter achieves linear complexity to data size and has lower variance. The current work focuses instead on combining these two methods, along with rotated feature bagging, to achieve linear time complexity both to data size and to number of features. Despite their instability, the resulting models exhibit considerably higher performance and faster training and testing times.