 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Autoencoder for Multivariate Time Series Anomaly Detection
Apr 24, 2025Anomaly Detection (AD) defines the task of identifying observations or events that deviate from typical - or normal - patterns, a critical capability in IT security for recognizing incidents such as system misconfigurations, malware infections, or cyberattacks. In enterprise environments like SAP HANA Cloud systems, this task often involves monitoring high-dimensional, multivariate time series (MTS) derived from telemetry and log data. With the advent of quantum machine learning offering efficient calculations in high-dimensional latent spaces, many avenues open for dealing with such complex data. One approach is the Quantum Autoencoder (QAE), an emerging and promising method with potential for application in both data compression and AD. However, prior applications of QAEs to time series AD have been restricted to univariate data, limiting their relevance for real-world enterprise systems. In this work, we introduce a novel QAE-based framework designed specifically for MTS AD towards enterprise scale. We theoretically develop and experimentally validate the architecture, demonstrating that our QAE achieves performance competitive with neural-network-based autoencoders while requiring fewer trainable parameters. We evaluate our model on datasets that closely reflect SAP system telemetry and show that the proposed QAE is a viable and efficient alternative for semisupervised AD in real-world enterprise settings.
Efficient Quantum One-Class Support Vector Machines for Anomaly Detection Using Randomized Measurements and Variable Subsampling
Jul 30, 2024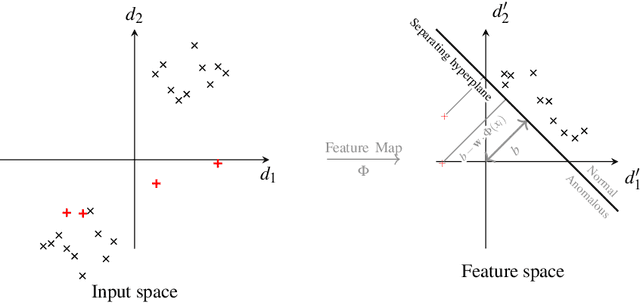
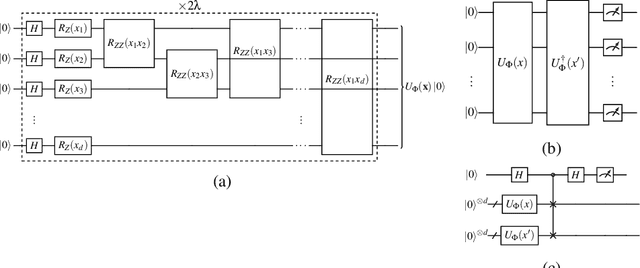
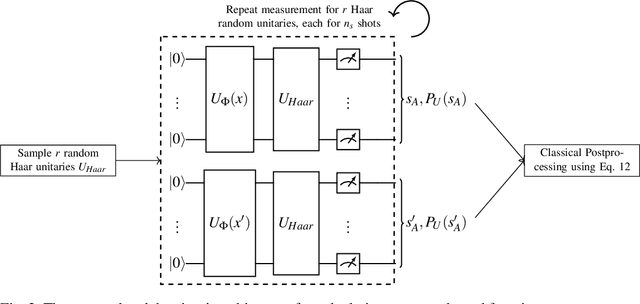
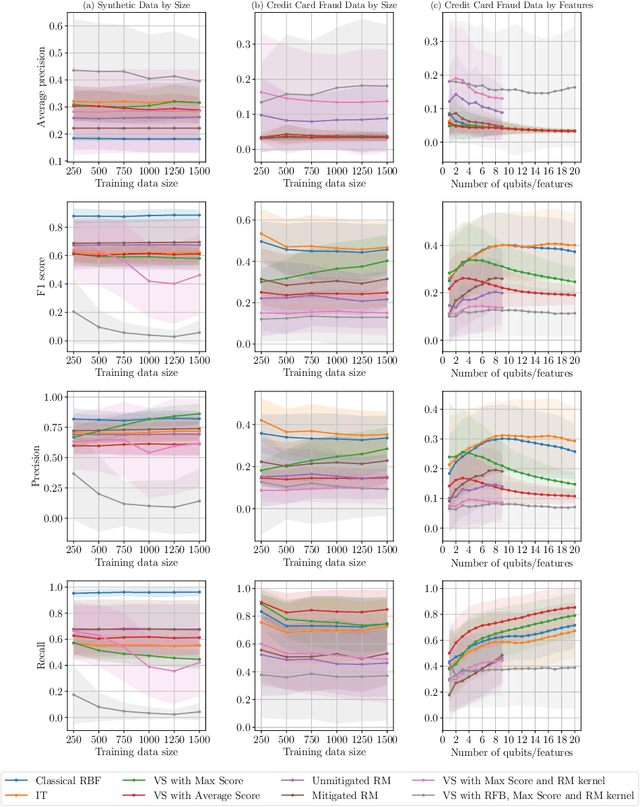
Quantum one-class support vector machines leverage the advantage of quantum kernel methods for semi-supervised anomaly detection. However, their quadratic time complexity with respect to data size poses challenges when dealing with large datasets. In recent work, quantum randomized measurements kernels and variable subsampling were proposed, as two independent methods to address this problem. The former achieves higher average precision, but suffers from variance, while the latter achieves linear complexity to data size and has lower variance. The current work focuses instead on combining these two methods, along with rotated feature bagging, to achieve linear time complexity both to data size and to number of features. Despite their instability, the resulting models exhibit considerably higher performance and faster training and testing times.
Towards Efficient Quantum Anomaly Detection: One-Class SVMs using Variable Subsampling and Randomized Measurements
Dec 14, 2023



Quantum computing, with its potential to enhance various machine learning tasks, allows significant advancements in kernel calculation and model precision. Utilizing the one-class Support Vector Machine alongside a quantum kernel, known for its classically challenging representational capacity, notable improvements in average precision compared to classical counterparts were observed in previous studies. Conventional calculations of these kernels, however, present a quadratic time complexity concerning data size, posing challenges in practical applications. To mitigate this, we explore two distinct approaches: utilizing randomized measurements to evaluate the quantum kernel and implementing the variable subsampling ensemble method, both targeting linear time complexity. Experimental results demonstrate a substantial reduction in training and inference times by up to 95\% and 25\% respectively, employing these methods. Although unstable, the average precision of randomized measurements discernibly surpasses that of the classical Radial Basis Function kernel, suggesting a promising direction for further research in scalable, efficient quantum computing applications in machine learning.