 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Quantum One-Class Support Vector Machines for Anomaly Detection Using Randomized Measurements and Variable Subsampling
Paper and Code
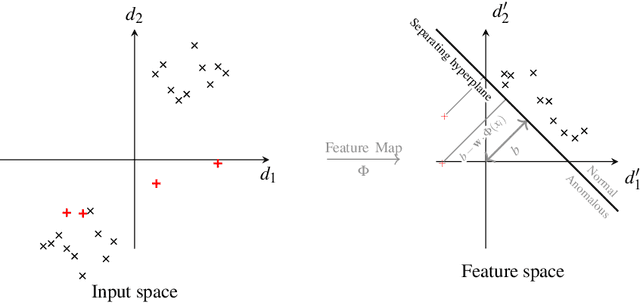
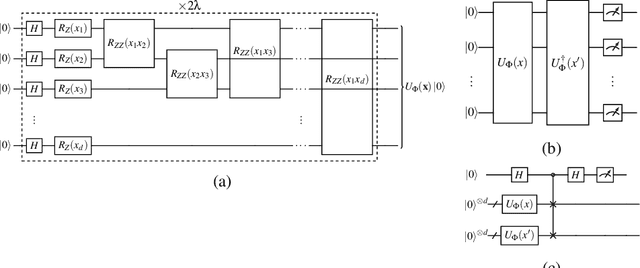
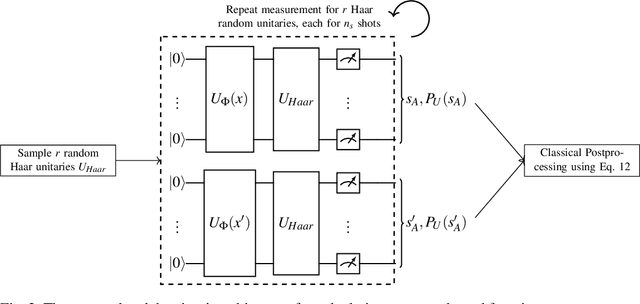
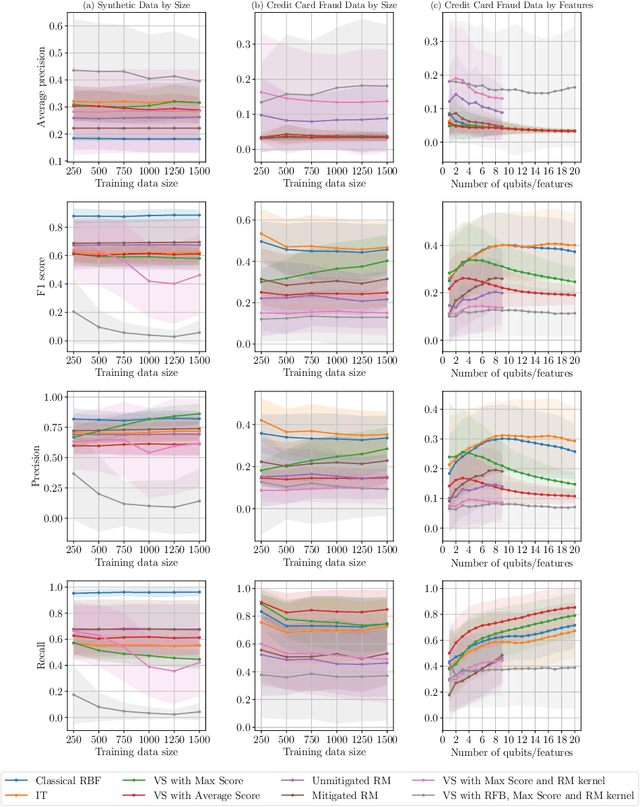
Quantum one-class support vector machines leverage the advantage of quantum kernel methods for semi-supervised anomaly detection. However, their quadratic time complexity with respect to data size poses challenges when dealing with large datasets. In recent work, quantum randomized measurements kernels and variable subsampling were proposed, as two independent methods to address this problem. The former achieves higher average precision, but suffers from variance, while the latter achieves linear complexity to data size and has lower variance. The current work focuses instead on combining these two methods, along with rotated feature bagging, to achieve linear time complexity both to data size and to number of features. Despite their instability, the resulting models exhibit considerably higher performance and faster training and testing times.